 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Debiased Representation via Disentangled Feature Augmentation
Paper and Code
Jul 03, 2021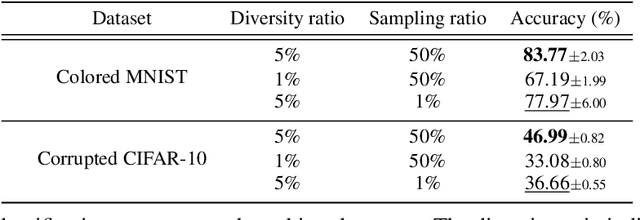
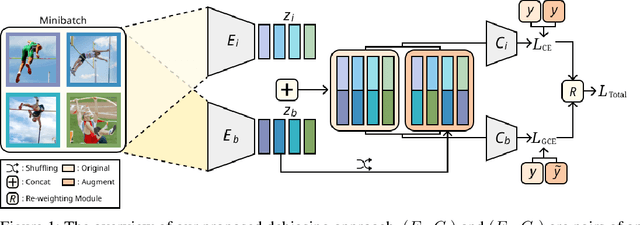

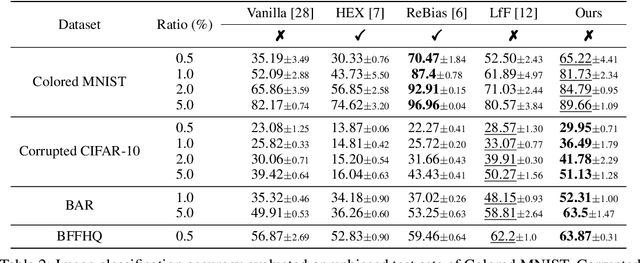
Image classification models tend to make decisions based on peripheral attributes of data items that have strong correlation with a target variable (i.e., dataset bias). These biased models suffer from the poor generalization capability when evaluated on unbiased datasets. Existing approaches for debiasing often identify and emphasize those samples with no such correlation (i.e., bias-conflicting) without defining the bias type in advance. However, such bias-conflicting samples are significantly scarce in biased datasets, limiting the debiasing capability of these approaches. This paper first presents an empirical analysis revealing that training with "diverse" bias-conflicting samples beyond a given training set is crucial for debiasing as well as the generalization capability. Based on this observation, we propose a novel feature-level data augmentation technique in order to synthesize diverse bias-conflicting samples. To this end, our method learns the disentangled representation of (1) the intrinsic attributes (i.e., those inherently defining a certain class) and (2) bias attributes (i.e., peripheral attributes causing the bias), from a large number of bias-aligned samples, the bias attributes of which have strong correlation with the target variable. Using the disentangled representation, we synthesize bias-conflicting samples that contain the diverse intrinsic attributes of bias-aligned samples by swapping their latent features. By utilizing these diversified bias-conflicting features during the training, our approach achieves superior classification accuracy and debiasing results against the existing baselines on both synthetic as well as real-world datasets.