 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePairEval: Open-domain Dialogue Evaluation with Pairwise Comparison
Paper and Code
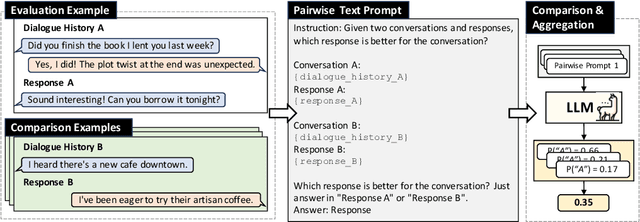



Building a reliable and automated evaluation metric is a necessary but challenging problem for open-domain dialogue systems. Recent studies proposed evaluation metrics that assess generated responses by considering their relevance to previous dialogue histories. Although effective, these metrics evaluate individual responses directly rather than considering their relative quality compared to other responses. To handle this, we propose PairEval, a novel dialogue evaluation metric for assessing responses by comparing their quality against responses in different conversations. PairEval is built on top of open-sourced and moderate-size language models, and we make them specialized in pairwise comparison between dialogue responses. Extensive experiments on multiple benchmarks demonstrate that our metric exhibits a higher correlation with human judgments than baseline metrics. We also find that the proposed comparative metric is more robust in detecting common failures from open-domain dialogue systems, including repetition and speaker insensitivity.