 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtecting Privacy Through Approximating Optimal Parameters for Sequence Unlearning in Language Models
Jun 20, 2024Although language models (LMs) demonstrate exceptional capabilities on various tasks, they are potentially vulnerable to extraction attacks, which represent a significant privacy risk. To mitigate the privacy concerns of LMs, machine unlearning has emerged as an important research area, which is utilized to induce the LM to selectively forget about some of its training data. While completely retraining the model will guarantee successful unlearning and privacy assurance, it is impractical for LMs, as it would be time-consuming and resource-intensive. Prior works efficiently unlearn the target token sequences, but upon subsequent iterations, the LM displays significant degradation in performance. In this work, we propose Privacy Protection via Optimal Parameters (POP), a novel unlearning method that effectively forgets the target token sequences from the pretrained LM by applying optimal gradient updates to the parameters. Inspired by the gradient derivation of complete retraining, we approximate the optimal training objective that successfully unlearns the target sequence while retaining the knowledge from the rest of the training data. Experimental results demonstrate that POP exhibits remarkable retention performance post-unlearning across 9 classification and 4 dialogue benchmarks, outperforming the state-of-the-art by a large margin. Furthermore, we introduce Remnant Memorization Accuracy that quantifies privacy risks based on token likelihood and validate its effectiveness through both qualitative and quantitative analyses.
SNAP: Unlearning Selective Knowledge in Large Language Models with Negative Instructions
Jun 18, 2024Instruction-following large language models (LLMs), such as ChatGPT, have become increasingly popular with the general audience, many of whom are incorporating them into their daily routines. However, these LLMs inadvertently disclose personal or copyrighted information, which calls for a machine unlearning method to remove selective knowledge. Previous attempts sought to forget the link between the target information and its associated entities, but it rather led to generating undesirable responses about the target, compromising the end-user experience. In this work, we propose SNAP, an innovative framework designed to selectively unlearn information by 1) training an LLM with negative instructions to generate obliterated responses, 2) augmenting hard positives to retain the original LLM performance, and 3) applying the novel Wasserstein regularization to ensure adequate deviation from the initial weights of the LLM. We evaluate our framework on various NLP benchmarks and demonstrate that our approach retains the original LLM capabilities, while successfully unlearning the specified information.
DEnsity: Open-domain Dialogue Evaluation Metric using Density Estimation
May 08, 2023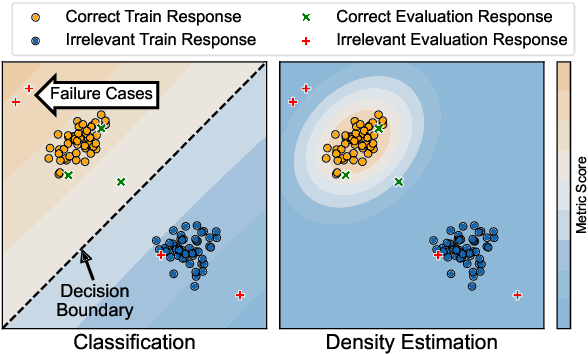



Despite the recent advances in open-domain dialogue systems, building a reliable evaluation metric is still a challenging problem. Recent studies proposed learnable metrics based on classification models trained to distinguish the correct response. However, neural classifiers are known to make overly confident predictions for examples from unseen distributions. We propose DEnsity, which evaluates a response by utilizing density estimation on the feature space derived from a neural classifier. Our metric measures how likely a response would appear in the distribution of human conversations. Moreover, to improve the performance of DEnsity, we utilize contrastive learning to further compress the feature space. Experiments on multiple response evaluation datasets show that DEnsity correlates better with human evaluations than the existing metrics. Our code is available at https://github.com/ddehun/DEnsity.