 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimCKP: Simple Contrastive Learning of Keyphrase Representations
Oct 12, 2023
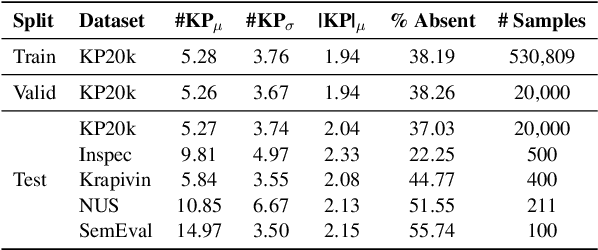
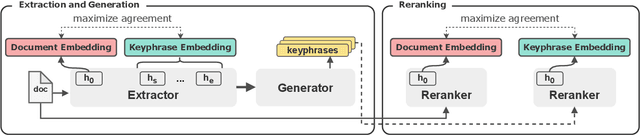
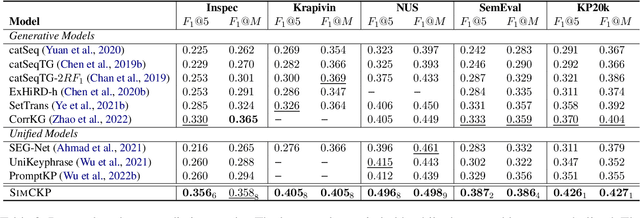
Keyphrase generation (KG) aims to generate a set of summarizing words or phrases given a source document, while keyphrase extraction (KE) aims to identify them from the text. Because the search space is much smaller in KE, it is often combined with KG to predict keyphrases that may or may not exist in the corresponding document. However, current unified approaches adopt sequence labeling and maximization-based generation that primarily operate at a token level, falling short in observing and scoring keyphrases as a whole. In this work, we propose SimCKP, a simple contrastive learning framework that consists of two stages: 1) An extractor-generator that extracts keyphrases by learning context-aware phrase-level representations in a contrastive manner while also generating keyphrases that do not appear in the document; 2) A reranker that adapts scores for each generated phrase by likewise aligning their representations with the corresponding document. Experimental results on multiple benchmark datasets demonstrate the effectiveness of our proposed approach, which outperforms the state-of-the-art models by a significant margin.
Cross-Domain Style Mixing for Face Cartoonization
May 25, 2022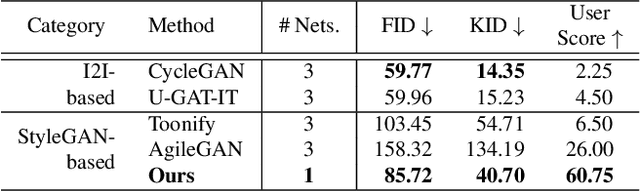

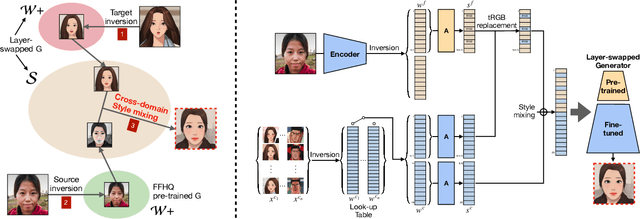
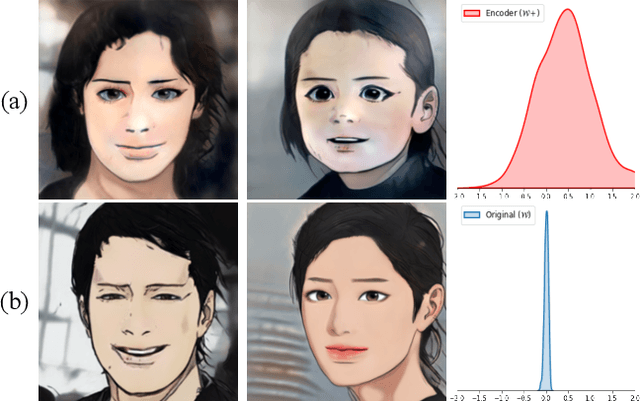
Cartoon domain has recently gained increasing popularity. Previous studies have attempted quality portrait stylization into the cartoon domain; however, this poses a great challenge since they have not properly addressed the critical constraints, such as requiring a large number of training images or the lack of support for abstract cartoon faces. Recently, a layer swapping method has been used for stylization requiring only a limited number of training images; however, its use cases are still narrow as it inherits the remaining issues. In this paper, we propose a novel method called Cross-domain Style mixing, which combines two latent codes from two different domains. Our method effectively stylizes faces into multiple cartoon characters at various face abstraction levels using only a single generator without even using a large number of training images.