 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Domain Style Mixing for Face Cartoonization
Paper and Code
May 25, 2022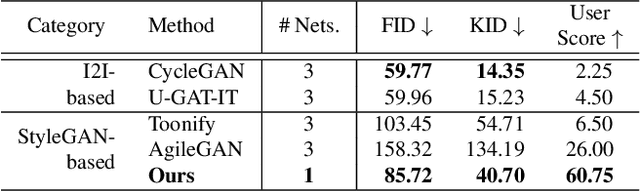

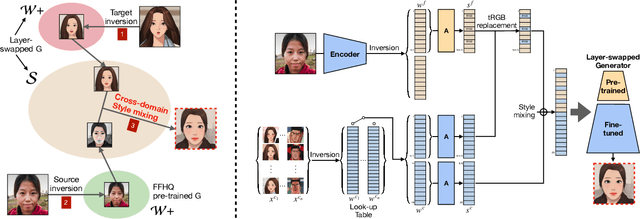
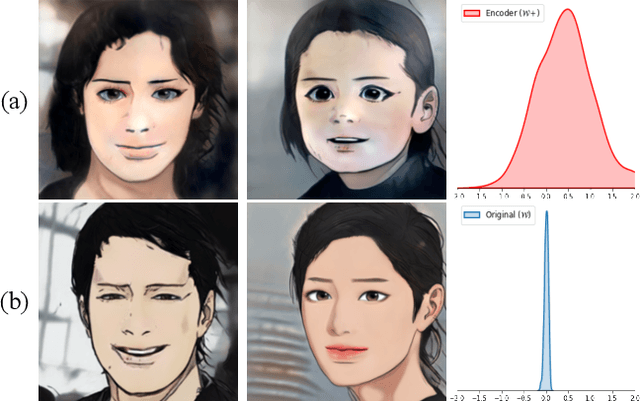
Cartoon domain has recently gained increasing popularity. Previous studies have attempted quality portrait stylization into the cartoon domain; however, this poses a great challenge since they have not properly addressed the critical constraints, such as requiring a large number of training images or the lack of support for abstract cartoon faces. Recently, a layer swapping method has been used for stylization requiring only a limited number of training images; however, its use cases are still narrow as it inherits the remaining issues. In this paper, we propose a novel method called Cross-domain Style mixing, which combines two latent codes from two different domains. Our method effectively stylizes faces into multiple cartoon characters at various face abstraction levels using only a single generator without even using a large number of training images.