 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudioGAN: A Compact and Efficient Framework for Real-Time High-Fidelity Text-to-Audio Generation
Dec 17, 2025Text-to-audio (TTA) generation can significantly benefit the media industry by reducing production costs and enhancing work efficiency. However, most current TTA models (primarily diffusion-based) suffer from slow inference speeds and high computational costs. In this paper, we introduce AudioGAN, the first successful Generative Adversarial Networks (GANs)-based TTA framework that generates audio in a single pass, thereby reducing model complexity and inference time. To overcome the inherent difficulties in training GANs, we integrate multiple ,contrastive losses and propose innovative components Single-Double-Triple (SDT) Attention and Time-Frequency Cross-Attention (TF-CA). Extensive experiments on the AudioCaps dataset demonstrate that AudioGAN achieves state-of-the-art performance while using 90% fewer parameters and running 20 times faster, synthesizing audio in under one second. These results establish AudioGAN as a practical and powerful solution for real-time TTA.
Cross-Modal Contrastive Representation Learning for Audio-to-Image Generation
Jul 20, 2022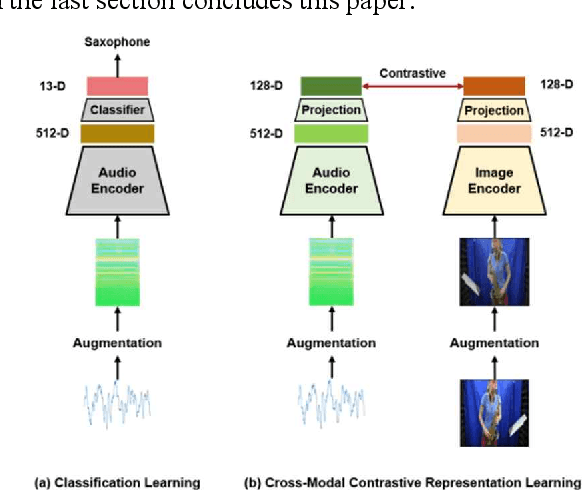

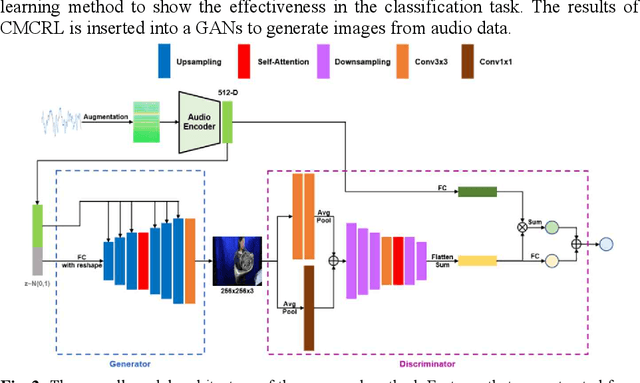

Multiple modalities for certain information provide a variety of perspectives on that information, which can improve the understanding of the information. Thus, it may be crucial to generate data of different modality from the existing data to enhance the understanding. In this paper, we investigate the cross-modal audio-to-image generation problem and propose Cross-Modal Contrastive Representation Learning (CMCRL) to extract useful features from audios and use it in the generation phase. Experimental results show that CMCRL enhances quality of images generated than previous research.