 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBounding Box Annotation with Visible Status
Apr 11, 2023



Training deep-learning-based vision systems requires the manual annotation of a significant amount of data to optimize several parameters of the deep convolutional neural networks. Such manual annotation is highly time-consuming and labor-intensive. To reduce this burden, a previous study presented a fully automated annotation approach that does not require any manual intervention. The proposed method associates a visual marker with an object and captures it in the same image. However, because the previous method relied on moving the object within the capturing range using a fixed-point camera, the collected image dataset was limited in terms of capturing viewpoints. To overcome this limitation, this study presents a mobile application-based free-viewpoint image-capturing method. With the proposed application, users can collect multi-view image datasets automatically that are annotated with bounding boxes by moving the camera. However, capturing images through human involvement is laborious and monotonous. Therefore, we propose gamified application features to track the progress of the collection status. Our experiments demonstrated that using the gamified mobile application for bounding box annotation, with visible collection progress status, can motivate users to collect multi-view object image datasets with less mental workload and time pressure in an enjoyable manner, leading to increased engagement.
Active Vapor-Based Robotic Wiper
Nov 16, 2021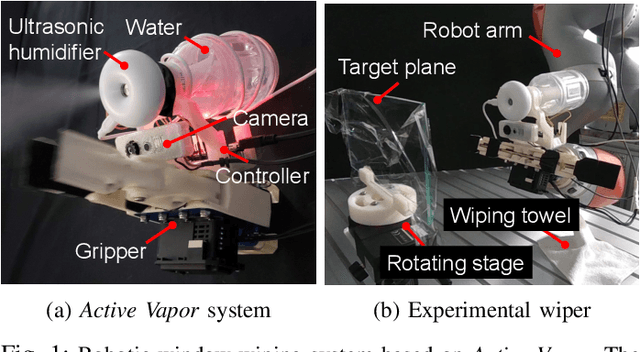

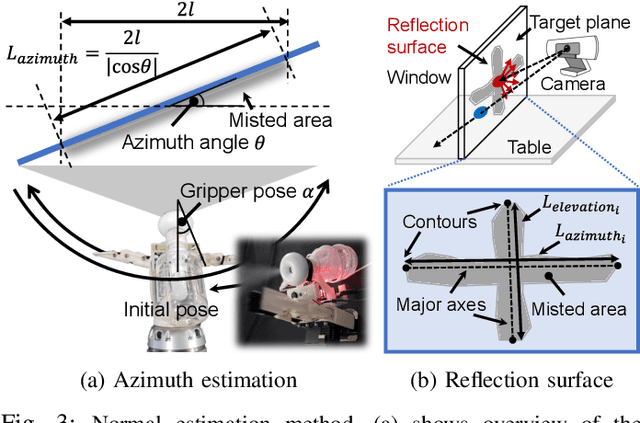

This paper presents a method of normal estimation for mirrors and transparent objects, which are difficult to recognize with a camera. To create a diffuse reflective surface, we propose to spray the water vapor onto the transparent or mirror surface. In the proposed method, we move an ultrasonic humidifier equipped on the tip of a robotic arm to apply the sprayed water vapor onto a plane of a target object so as to form a cross-shaped misted area. Diffuse reflective surfaces are partially generated as the misted area, which allows the camera to detect a surface of the target object. The viewpoint of the gripper-mounted camera is adjusted so that the extracted misted area appears as largest in the image, and finally the plane normal of the target object surface are estimated. We conducted normal estimation experiments to evaluate the effectiveness of the proposed method. The RMSEs of the azimuth estimation for a mirror and a transparent glass are about 4.2 and 5.8 degrees, respectively. Consequently, our robot experiments demonstrate that our robotic wiper can perform contact-force-regulated wiping motions for cleaning a transparent window as humans do.
Robotic Waste Sorter with Agile Manipulation and Quickly Trainable Detector
Apr 02, 2021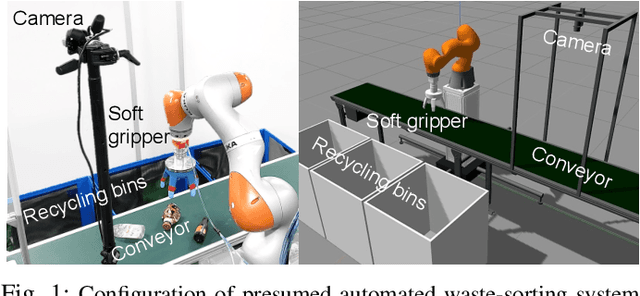
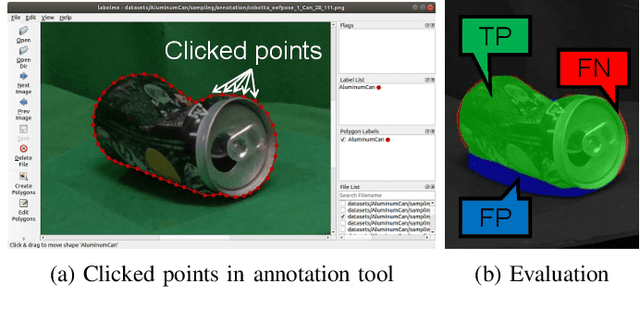
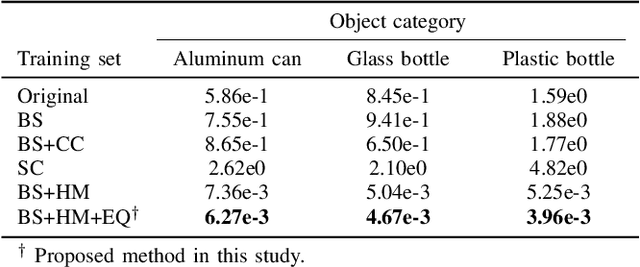
Owing to human labor shortages, the automation of labor-intensive manual waste-sorting is needed. The goal of automating the waste-sorting is to replace the human role of robust detection and agile manipulation of the waste items by robots. To achieve this, we propose three methods. First, we propose a combined manipulation method using graspless push-and-drop and pick-and-release manipulation. Second, we propose a robotic system that can automatically collect object images to quickly train a deep neural network model. Third, we propose the method to mitigate the differences in the appearance of target objects from two scenes: one for the dataset collection and the other for waste sorting in a recycling factory. If differences exist, the performance of a trained waste detector could be decreased. We address differences in illumination and background by applying object scaling, histogram matching with histogram equalization, and background synthesis to the source target-object images. Via experiments in an indoor experimental workplace for waste-sorting, we confirmed the proposed methods enable quickly collecting the training image sets for three classes of waste items, i.e., aluminum can, glass bottle, and plastic bottle and detecting them with higher performance than the methods that do not consider the differences. We also confirmed that the proposed method enables the robot quickly manipulate them.