 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForce Map: Learning to Predict Contact Force Distribution from Vision
Apr 12, 2023



When humans see a scene, they can roughly imagine the forces applied to objects based on their experience and use them to handle the objects properly. This paper considers transferring this "force-visualization" ability to robots. We hypothesize that a rough force distribution (named "force map") can be utilized for object manipulation strategies even if accurate force estimation is impossible. Based on this hypothesis, we propose a training method to predict the force map from vision. To investigate this hypothesis, we generated scenes where objects were stacked in bulk through simulation and trained a model to predict the contact force from a single image. We further applied domain randomization to make the trained model function on real images. The experimental results showed that the model trained using only synthetic images could predict approximate patterns representing the contact areas of the objects even for real images. Then, we designed a simple algorithm to plan a lifting direction using the predicted force distribution. We confirmed that using the predicted force distribution contributes to finding natural lifting directions for typical real-world scenes. Furthermore, the evaluation through simulations showed that the disturbance caused to surrounding objects was reduced by 26 % (translation displacement) and by 39 % (angular displacement) for scenes where objects were overlapping.
Virtual Landmark-Based Control of Docking Support for Assistive Mobility Devices
Jul 28, 2021


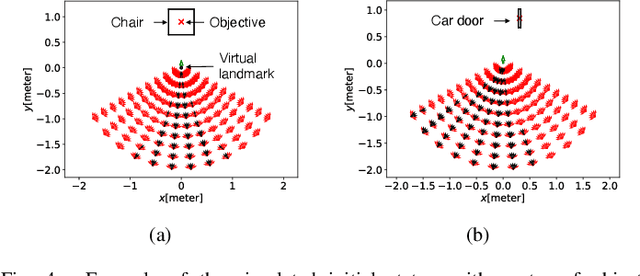
This work proposes an autonomous docking control for nonholonomic constrained mobile robots and applies it to an intelligent mobility device or wheelchair for assisting the user in approaching resting furniture such as a chair or a bed. We defined a virtual landmark inferred from the target docking destination. Then, we solve the problem of keeping the targeted volume inside the field of view (FOV) of a tracking camera and docking to the virtual landmark through a novel definition that enables to control for the desired end-pose. In this article, we proposed a nonlinear feedback controller to perform the docking with the depth camera's FOV as a constraint. Then, a numerical method is proposed to find the feasible space of initial states where convergence could be guaranteed. Finally, the entire system was embedded for real-time operation on a standing wheelchair with the virtual landmark estimation by 3D object tracking with an RGB-D camera and we validated the effectiveness in simulation and experimental evaluations. The results show the guaranteed convergence for the feasible space depending on the virtual landmark location. In the implementation, the robot converges to the virtual landmark while respecting the FOV constraints.
* IEEE/ASME International Conference on Advanced Intelligent Mechatronics (AIM2021), JULY 12-16. Virtual Conference hosted by TU Delft, Delft, The Netherlands. Presentation video: https://www.youtube.com/watch?v=p6DzbjV6w4c