 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCIVET: Systematic Evaluation of Understanding in VLMs
Jun 05, 2025While Vision-Language Models (VLMs) have achieved competitive performance in various tasks, their comprehension of the underlying structure and semantics of a scene remains understudied. To investigate the understanding of VLMs, we study their capability regarding object properties and relations in a controlled and interpretable manner. To this scope, we introduce CIVET, a novel and extensible framework for systematiC evaluatIon Via controllEd sTimuli. CIVET addresses the lack of standardized systematic evaluation for assessing VLMs' understanding, enabling researchers to test hypotheses with statistical rigor. With CIVET, we evaluate five state-of-the-art VLMs on exhaustive sets of stimuli, free from annotation noise, dataset-specific biases, and uncontrolled scene complexity. Our findings reveal that 1) current VLMs can accurately recognize only a limited set of basic object properties; 2) their performance heavily depends on the position of the object in the scene; 3) they struggle to understand basic relations among objects. Furthermore, a comparative evaluation with human annotators reveals that VLMs still fall short of achieving human-level accuracy.
Will LLMs Replace the Encoder-Only Models in Temporal Relation Classification?
Oct 14, 2024The automatic detection of temporal relations among events has been mainly investigated with encoder-only models such as RoBERTa. Large Language Models (LLM) have recently shown promising performance in temporal reasoning tasks such as temporal question answering. Nevertheless, recent studies have tested the LLMs' performance in detecting temporal relations of closed-source models only, limiting the interpretability of those results. In this work, we investigate LLMs' performance and decision process in the Temporal Relation Classification task. First, we assess the performance of seven open and closed-sourced LLMs experimenting with in-context learning and lightweight fine-tuning approaches. Results show that LLMs with in-context learning significantly underperform smaller encoder-only models based on RoBERTa. Then, we delve into the possible reasons for this gap by applying explainable methods. The outcome suggests a limitation of LLMs in this task due to their autoregressive nature, which causes them to focus only on the last part of the sequence. Additionally, we evaluate the word embeddings of these two models to better understand their pre-training differences. The code and the fine-tuned models can be found respectively on GitHub.
Should We Fine-Tune or RAG? Evaluating Different Techniques to Adapt LLMs for Dialogue
Jun 10, 2024



We study the limitations of Large Language Models (LLMs) for the task of response generation in human-machine dialogue. Several techniques have been proposed in the literature for different dialogue types (e.g., Open-Domain). However, the evaluations of these techniques have been limited in terms of base LLMs, dialogue types and evaluation metrics. In this work, we extensively analyze different LLM adaptation techniques when applied to different dialogue types. We have selected two base LLMs, Llama-2 and Mistral, and four dialogue types Open-Domain, Knowledge-Grounded, Task-Oriented, and Question Answering. We evaluate the performance of in-context learning and fine-tuning techniques across datasets selected for each dialogue type. We assess the impact of incorporating external knowledge to ground the generation in both scenarios of Retrieval-Augmented Generation (RAG) and gold knowledge. We adopt consistent evaluation and explainability criteria for automatic metrics and human evaluation protocols. Our analysis shows that there is no universal best-technique for adapting large language models as the efficacy of each technique depends on both the base LLM and the specific type of dialogue. Last but not least, the assessment of the best adaptation technique should include human evaluation to avoid false expectations and outcomes derived from automatic metrics.
Are LLMs Robust for Spoken Dialogues?
Jan 04, 2024
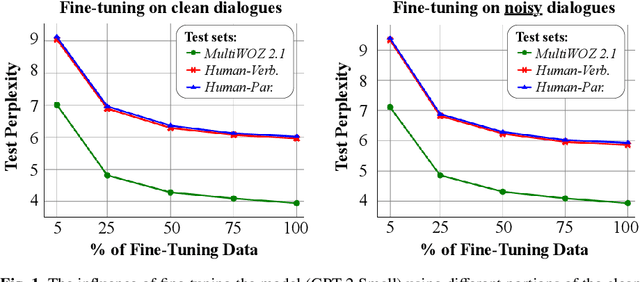

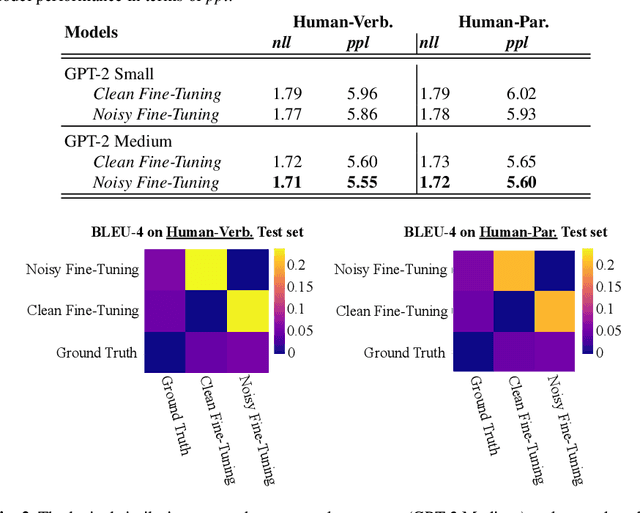
Large Pre-Trained Language Models have demonstrated state-of-the-art performance in different downstream tasks, including dialogue state tracking and end-to-end response generation. Nevertheless, most of the publicly available datasets and benchmarks on task-oriented dialogues focus on written conversations. Consequently, the robustness of the developed models to spoken interactions is unknown. In this work, we have evaluated the performance of LLMs for spoken task-oriented dialogues on the DSTC11 test sets. Due to the lack of proper spoken dialogue datasets, we have automatically transcribed a development set of spoken dialogues with a state-of-the-art ASR engine. We have characterized the ASR-error types and their distributions and simulated these errors in a large dataset of dialogues. We report the intrinsic (perplexity) and extrinsic (human evaluation) performance of fine-tuned GPT-2 and T5 models in two subtasks of response generation and dialogue state tracking, respectively. The results show that LLMs are not robust to spoken noise by default, however, fine-tuning/training such models on a proper dataset of spoken TODs can result in a more robust performance.
Let's Give a Voice to Conversational Agents in Virtual Reality
Aug 04, 2023

The dialogue experience with conversational agents can be greatly enhanced with multimodal and immersive interactions in virtual reality. In this work, we present an open-source architecture with the goal of simplifying the development of conversational agents operating in virtual environments. The architecture offers the possibility of plugging in conversational agents of different domains and adding custom or cloud-based Speech-To-Text and Text-To-Speech models to make the interaction voice-based. Using this architecture, we present two conversational prototypes operating in the digital health domain developed in Unity for both non-immersive displays and VR headsets.
Understanding Emotion Valence is a Joint Deep Learning Task
May 27, 2023



The valence analysis of speakers' utterances or written posts helps to understand the activation and variations of the emotional state throughout the conversation. More recently, the concept of Emotion Carriers (EC) has been introduced to explain the emotion felt by the speaker and its manifestations. In this work, we investigate the natural inter-dependency of valence and ECs via a multi-task learning approach. We experiment with Pre-trained Language Models (PLM) for single-task, two-step, and joint settings for the valence and EC prediction tasks. We compare and evaluate the performance of generative (GPT-2) and discriminative (BERT) architectures in each setting. We observed that providing the ground truth label of one task improves the prediction performance of the models in the other task. We further observed that the discriminative model achieves the best trade-off of valence and EC prediction tasks in the joint prediction setting. As a result, we attain a single model that performs both tasks, thus, saving computation resources at training and inference times.
Whats New? Identifying the Unfolding of New Events in Narratives
Feb 20, 2023
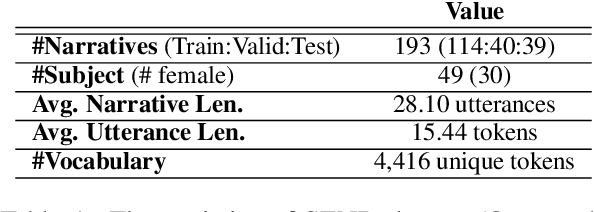
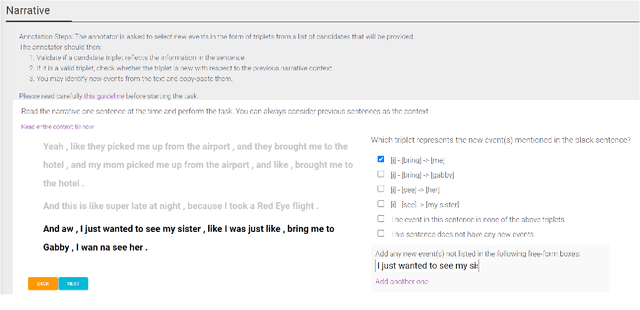
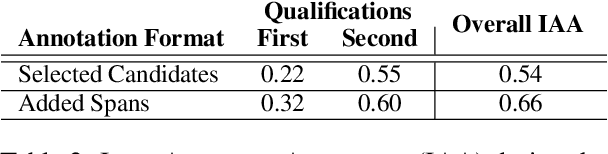
Narratives include a rich source of events unfolding over time and context. Automatic understanding of these events may provide a summarised comprehension of the narrative for further computation (such as reasoning). In this paper, we study the Information Status (IS) of the events and propose a novel challenging task: the automatic identification of new events in a narrative. We define an event as a triplet of subject, predicate, and object. The event is categorized as new with respect to the discourse context and whether it can be inferred through commonsense reasoning. We annotated a publicly available corpus of narratives with the new events at sentence level using human annotators. We present the annotation protocol and a study aiming at validating the quality of the annotation and the difficulty of the task. We publish the annotated dataset, annotation materials, and machine learning baseline models for the task of new event extraction for narrative understanding.
What can Speech and Language Tell us About the Working Alliance in Psychotherapy
Jun 27, 2022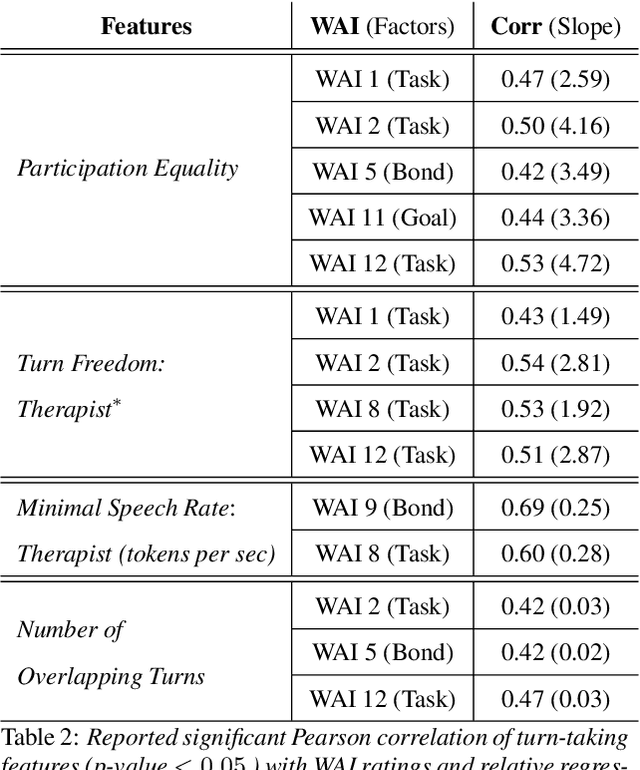

We are interested in the problem of conversational analysis and its application to the health domain. Cognitive Behavioral Therapy is a structured approach in psychotherapy, allowing the therapist to help the patient to identify and modify the malicious thoughts, behavior, or actions. This cooperative effort can be evaluated using the Working Alliance Inventory Observer-rated Shortened - a 12 items inventory covering task, goal, and relationship - which has a relevant influence on therapeutic outcomes. In this work, we investigate the relation between this alliance inventory and the spoken conversations (sessions) between the patient and the psychotherapist. We have delivered eight weeks of e-therapy, collected their audio and video call sessions, and manually transcribed them. The spoken conversations have been annotated and evaluated with WAI ratings by professional therapists. We have investigated speech and language features and their association with WAI items. The feature types include turn dynamics, lexical entrainment, and conversational descriptors extracted from the speech and language signals. Our findings provide strong evidence that a subset of these features are strong indicators of working alliance. To the best of our knowledge, this is the first and a novel study to exploit speech and language for characterising working alliance.