 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGetting to the Point: Why Pointing Improves LVLMs
Mar 23, 2026Pointing increases the accuracy and explainability of Large Vision-Language Models (LVLMs) by modeling grounding and reasoning as explicit sequential steps. The model grounds the objects mentioned in the natural-language query by predicting their coordinates, and then generates an answer conditioned on these points. While pointing has been shown to increase LVLMs' accuracy, it is unclear which mechanism supports these gains and its relevance in cognitive tasks. In addition, the reliability of the intermediate points remains understudied, limiting their use as visual explanations. In this work, we study the role of pointing in a cognitive task: zero-shot counting from a visual scene. We fine-tune state-of-the-art LVLMs following two approaches: Direct Counting, where models only predict the total number of objects, and Point-then-Count, where LVLMs generate the target objects' coordinates followed by their count. The results show that Point-then-Count achieves higher out-of-distribution generalization, suggesting that coordinates help LVLMs learn skills rather than overfitting on narrow tasks. Although predicted points are accurately grounded in the image in over 89\% of cases (as measured by F1), performance varies across image regions, revealing spatial biases. Finally, mechanistic analyses show that gains in counting arise from the spatial information encoded in the coordinates.
V-DyKnow: A Dynamic Benchmark for Time-Sensitive Knowledge in Vision Language Models
Mar 17, 2026Vision-Language Models (VLMs) are trained on data snapshots of documents, including images and texts. Their training data and evaluation benchmarks are typically static, implicitly treating factual knowledge as time-invariant. However, real-world facts are intrinsically time-sensitive and subject to erratic and periodic changes, causing model predictions to become outdated. We present V-DyKnow, a Visual Dynamic Knowledge benchmark for evaluating time-sensitive factual knowledge in VLMs. Using V-DyKnow, we benchmark closed- and open-source VLMs and analyze a) the reliability (correctness and consistency) of model responses across modalities and input perturbations; b) the efficacy of knowledge editing and multi-modal RAG methods for knowledge updates across modalities; and c) the sources of outdated predictions, through data and mechanistic analysis. Our results show that VLMs frequently output outdated facts, reflecting outdated snapshots used in the (pre-)training phase. Factual reliability degrades from textual to visual stimuli, even when entities are correctly recognized. Besides, existing alignment approaches fail to consistently update the models' knowledge across modalities. Together, these findings highlight fundamental limitations in how current VLMs acquire and update time-sensitive knowledge across modalities. We release the benchmark, code, and evaluation data.
What Does Loss Optimization Actually Teach, If Anything? Knowledge Dynamics in Continual Pre-training of LLMs
Jan 07, 2026Continual Pre-Training (CPT) is widely used for acquiring and updating factual knowledge in LLMs. This practice treats loss as a proxy for knowledge learning, while offering no grounding into how it changes during training. We study CPT as a knowledge learning process rather than a solely optimization problem. We construct a controlled, distribution-matched benchmark of factual documents and interleave diagnostic probes directly into the CPT loop, enabling epoch-level measurement of knowledge acquisition dynamics and changes in Out-Of-Domain (OOD) general skills (e.g., math). We further analyze how CPT reshapes knowledge circuits during training. Across three instruction-tuned LLMs and multiple CPT strategies, optimization and learning systematically diverge as loss decreases monotonically while factual learning is unstable and non-monotonic. Acquired facts are rarely consolidated, learning is strongly conditioned on prior exposure, and OOD performance degrades from early epochs. Circuit analysis reveals rapid reconfiguration of knowledge pathways across epochs, providing an explanation for narrow acquisition windows and systematic forgetting. These results show that loss optimization is misaligned with learning progress in CPT and motivate evaluation of stopping criteria based on task-level learning dynamics.
From Synthetic Scenes to Real Performance: Enhancing Spatial Reasoning in VLMs
Nov 14, 2025Fine-tuning Vision-Language Models (VLMs) is a common strategy to improve performance following an ad-hoc data collection and annotation of real-world scenes. However, this process is often prone to biases, errors, and distribution imbalance, resulting in overfitting and imbalanced performance. Although a few studies have tried to address this problem by generating synthetic data, they lacked control over distribution bias and annotation quality. To address these challenges, we redesign the fine-tuning process in two ways. First, we control the generation of data and its annotations, ensuring it is free from bias, distribution imbalance, and annotation errors. We automatically construct the dataset by comprehensively sampling objects' attributes, including color, shape, size, and position within the scene. Secondly, using this annotated dataset, we fine-tune state-of-the-art VLMs and assess performance transferability to real-world data on the absolute position task. We conduct exhaustive evaluations on both synthetic and real-world benchmarks. Our experiments reveal two key findings: 1) fine-tuning on balanced synthetic data yields uniform performance across the visual scene and mitigates common biases; and 2) fine-tuning on synthetic stimuli significantly improves performance on real-world data (COCO), outperforming models fine-tuned in the matched setting.
CIVET: Systematic Evaluation of Understanding in VLMs
Jun 05, 2025While Vision-Language Models (VLMs) have achieved competitive performance in various tasks, their comprehension of the underlying structure and semantics of a scene remains understudied. To investigate the understanding of VLMs, we study their capability regarding object properties and relations in a controlled and interpretable manner. To this scope, we introduce CIVET, a novel and extensible framework for systematiC evaluatIon Via controllEd sTimuli. CIVET addresses the lack of standardized systematic evaluation for assessing VLMs' understanding, enabling researchers to test hypotheses with statistical rigor. With CIVET, we evaluate five state-of-the-art VLMs on exhaustive sets of stimuli, free from annotation noise, dataset-specific biases, and uncontrolled scene complexity. Our findings reveal that 1) current VLMs can accurately recognize only a limited set of basic object properties; 2) their performance heavily depends on the position of the object in the scene; 3) they struggle to understand basic relations among objects. Furthermore, a comparative evaluation with human annotators reveals that VLMs still fall short of achieving human-level accuracy.
Should We Fine-Tune or RAG? Evaluating Different Techniques to Adapt LLMs for Dialogue
Jun 10, 2024



We study the limitations of Large Language Models (LLMs) for the task of response generation in human-machine dialogue. Several techniques have been proposed in the literature for different dialogue types (e.g., Open-Domain). However, the evaluations of these techniques have been limited in terms of base LLMs, dialogue types and evaluation metrics. In this work, we extensively analyze different LLM adaptation techniques when applied to different dialogue types. We have selected two base LLMs, Llama-2 and Mistral, and four dialogue types Open-Domain, Knowledge-Grounded, Task-Oriented, and Question Answering. We evaluate the performance of in-context learning and fine-tuning techniques across datasets selected for each dialogue type. We assess the impact of incorporating external knowledge to ground the generation in both scenarios of Retrieval-Augmented Generation (RAG) and gold knowledge. We adopt consistent evaluation and explainability criteria for automatic metrics and human evaluation protocols. Our analysis shows that there is no universal best-technique for adapting large language models as the efficacy of each technique depends on both the base LLM and the specific type of dialogue. Last but not least, the assessment of the best adaptation technique should include human evaluation to avoid false expectations and outcomes derived from automatic metrics.
Is Your LLM Outdated? Benchmarking LLMs & Alignment Algorithms for Time-Sensitive Knowledge
Apr 10, 2024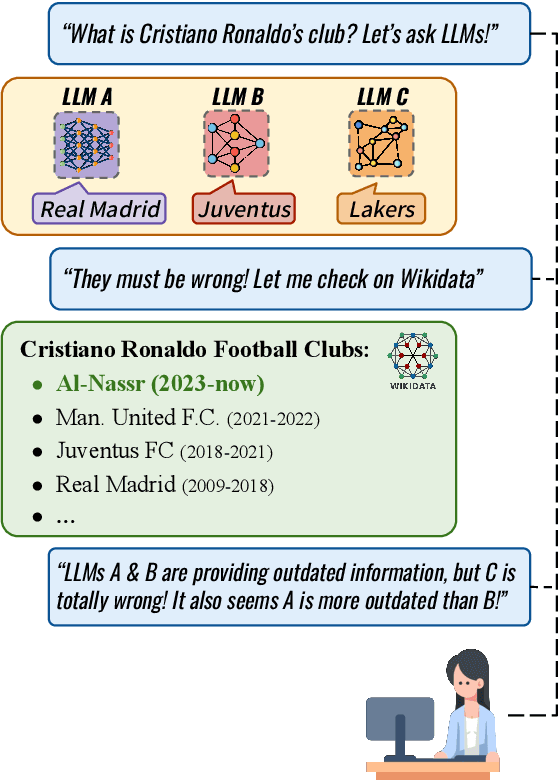
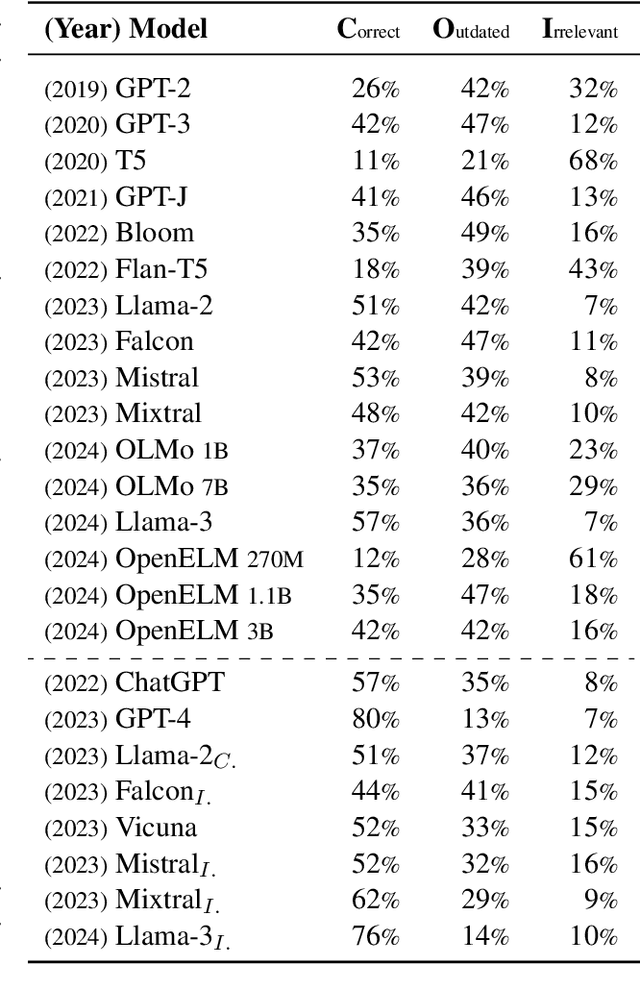

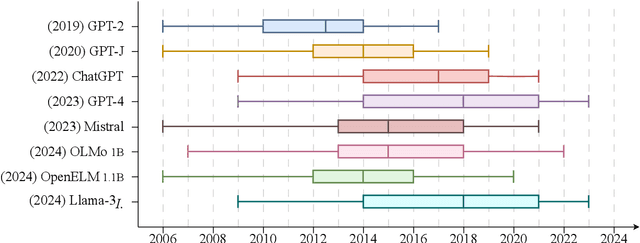
We study the appropriateness of Large Language Models (LLMs) as knowledge repositories. We focus on the challenge of maintaining LLMs' factual knowledge up-to-date over time. Motivated by the lack of studies on identifying outdated knowledge within LLMs, we design and develop a dynamic benchmark with up-to-date ground truth answers for each target factual question. We evaluate eighteen open-source and closed-source state-of-the-art LLMs on time-sensitive knowledge retrieved in real-time from Wikidata. We select time-sensitive domain facts in politics, sports, and organizations, and estimate the recency of the information learned by the model during pre-training\fine-tuning. In the second contribution, we evaluate the effectiveness of knowledge editing methods for aligning LLMs with up-to-date factual knowledge and compare their performance with Retrieval Augmented Generation. The dynamic benchmark is designed to be used as-is to assess LLMs's up-to-dateness, as well as to be extended to other domains by sharing the code, the dataset, as well as evaluation and visualization scripts.
Are LLMs Robust for Spoken Dialogues?
Jan 04, 2024
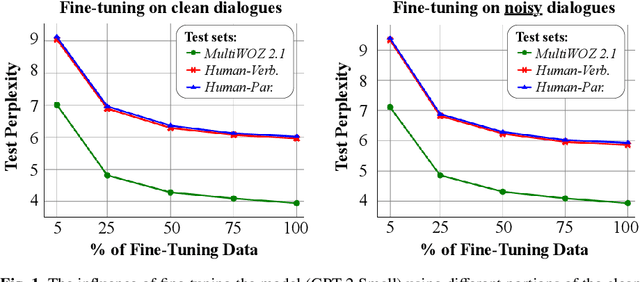

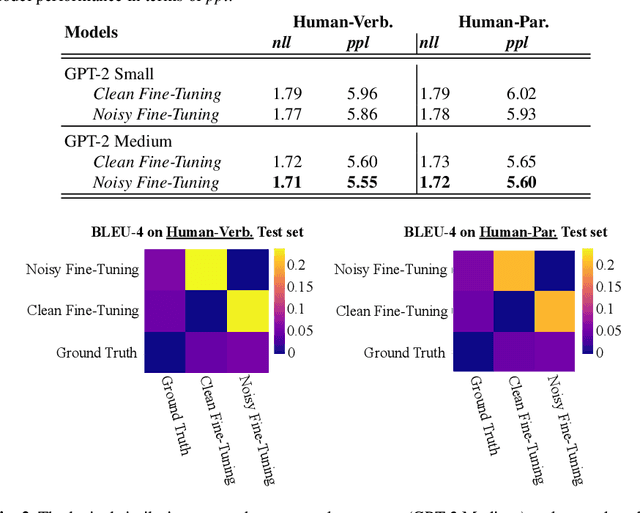
Large Pre-Trained Language Models have demonstrated state-of-the-art performance in different downstream tasks, including dialogue state tracking and end-to-end response generation. Nevertheless, most of the publicly available datasets and benchmarks on task-oriented dialogues focus on written conversations. Consequently, the robustness of the developed models to spoken interactions is unknown. In this work, we have evaluated the performance of LLMs for spoken task-oriented dialogues on the DSTC11 test sets. Due to the lack of proper spoken dialogue datasets, we have automatically transcribed a development set of spoken dialogues with a state-of-the-art ASR engine. We have characterized the ASR-error types and their distributions and simulated these errors in a large dataset of dialogues. We report the intrinsic (perplexity) and extrinsic (human evaluation) performance of fine-tuned GPT-2 and T5 models in two subtasks of response generation and dialogue state tracking, respectively. The results show that LLMs are not robust to spoken noise by default, however, fine-tuning/training such models on a proper dataset of spoken TODs can result in a more robust performance.