 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Your LLM Outdated? Benchmarking LLMs & Alignment Algorithms for Time-Sensitive Knowledge
Paper and Code
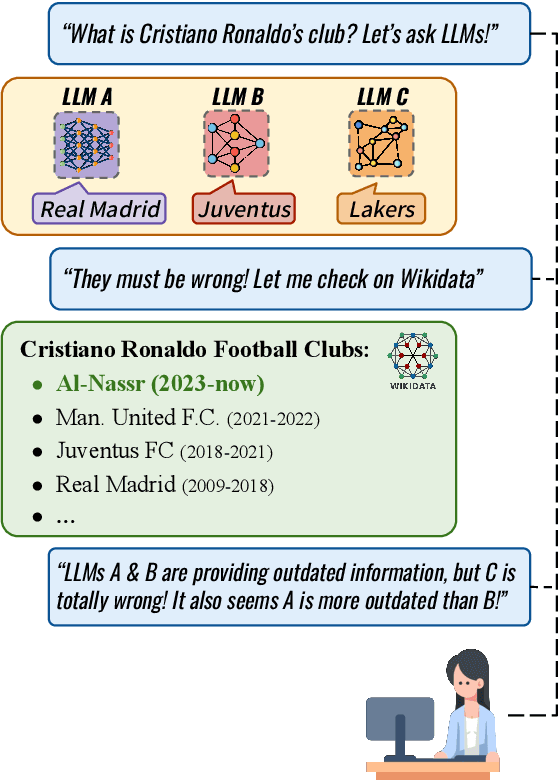
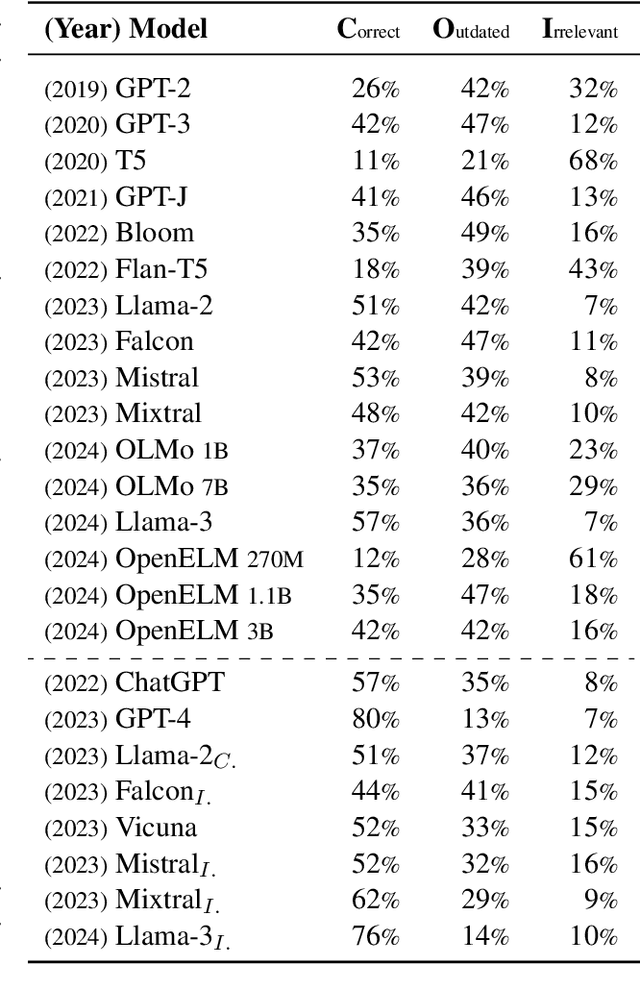

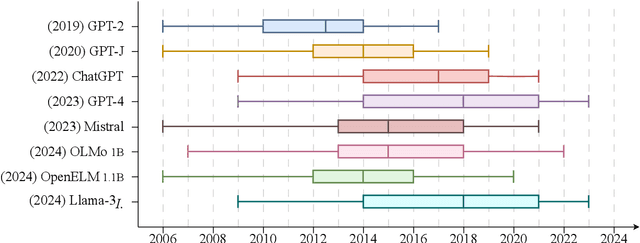
We study the appropriateness of Large Language Models (LLMs) as knowledge repositories. We focus on the challenge of maintaining LLMs' factual knowledge up-to-date over time. Motivated by the lack of studies on identifying outdated knowledge within LLMs, we design and develop a dynamic benchmark with up-to-date ground truth answers for each target factual question. We evaluate eighteen open-source and closed-source state-of-the-art LLMs on time-sensitive knowledge retrieved in real-time from Wikidata. We select time-sensitive domain facts in politics, sports, and organizations, and estimate the recency of the information learned by the model during pre-training\fine-tuning. In the second contribution, we evaluate the effectiveness of knowledge editing methods for aligning LLMs with up-to-date factual knowledge and compare their performance with Retrieval Augmented Generation. The dynamic benchmark is designed to be used as-is to assess LLMs's up-to-dateness, as well as to be extended to other domains by sharing the code, the dataset, as well as evaluation and visualization scripts.