 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRestoration-Guided Kuzushiji Character Recognition Framework under Seal Interference
Feb 22, 2026Kuzushiji was one of the most popular writing styles in pre-modern Japan and was widely used in both personal letters and official documents. However, due to its highly cursive forms and extensive glyph variations, most modern Japanese readers cannot directly interpret Kuzushiji characters. Therefore, recent research has focused on developing automated Kuzushiji character recognition methods, which have achieved satisfactory performance on relatively clean Kuzushiji document images. However, existing methods struggle to maintain recognition accuracy under seal interference (e.g., when seals overlap characters), despite the frequent occurrence of seals in pre-modern Japanese documents. To address this challenge, we propose a three-stage restoration-guided Kuzushiji character recognition (RG-KCR) framework specifically designed to mitigate seal interference. We construct datasets for evaluating Kuzushiji character detection (Stage 1) and classification (Stage 3). Experimental results show that the YOLOv12-medium model achieves a precision of 98.0% and a recall of 93.3% on the constructed test set. We quantitatively evaluate the restoration performance of Stage 2 using PSNR and SSIM. In addition, we conduct an ablation study to demonstrate that Stage 2 improves the Top-1 accuracy of Metom, a Vision Transformer (ViT)-based Kuzushiji classifier employed in Stage 3, from 93.45% to 95.33%. The implementation code of this work is available at https://ruiyangju.github.io/RG-KCR.
DKDS: A Benchmark Dataset of Degraded Kuzushiji Documents with Seals for Detection and Binarization
Nov 12, 2025Kuzushiji, a pre-modern Japanese cursive script, can currently be read and understood by only a few thousand trained experts in Japan. With the rapid development of deep learning, researchers have begun applying Optical Character Recognition (OCR) techniques to transcribe Kuzushiji into modern Japanese. Although existing OCR methods perform well on clean pre-modern Japanese documents written in Kuzushiji, they often fail to consider various types of noise, such as document degradation and seals, which significantly affect recognition accuracy. To the best of our knowledge, no existing dataset specifically addresses these challenges. To address this gap, we introduce the Degraded Kuzushiji Documents with Seals (DKDS) dataset as a new benchmark for related tasks. We describe the dataset construction process, which required the assistance of a trained Kuzushiji expert, and define two benchmark tracks: (1) text and seal detection and (2) document binarization. For the text and seal detection track, we provide baseline results using multiple versions of the You Only Look Once (YOLO) models for detecting Kuzushiji characters and seals. For the document binarization track, we present baseline results from traditional binarization algorithms, traditional algorithms combined with K-means clustering, and Generative Adversarial Network (GAN)-based methods. The DKDS dataset and the implementation code for baseline methods are available at https://ruiyangju.github.io/DKDS.
EgoOops: A Dataset for Mistake Action Detection from Egocentric Videos with Procedural Texts
Oct 07, 2024


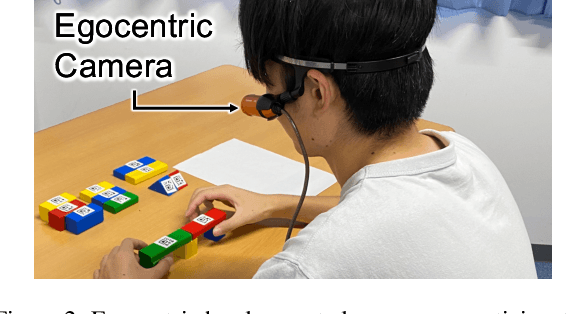
Mistake action detection from egocentric videos is crucial for developing intelligent archives that detect workers' errors and provide feedback. Previous studies have been limited to specific domains, focused on detecting mistakes from videos without procedural texts, and analyzed whether actions are mistakes. To address these limitations, in this paper, we propose the EgoOops dataset, which includes egocentric videos, procedural texts, and three types of annotations: video-text alignment, mistake labels, and descriptions for mistakes. EgoOops covers five procedural domains and includes 50 egocentric videos. The video-text alignment allows the model to detect mistakes based on both videos and procedural texts. The mistake labels and descriptions enable detailed analysis of real-world mistakes. Based on EgoOops, we tackle two tasks: video-text alignment and mistake detection. For video-text alignment, we enhance the recent StepFormer model with an additional loss for fine-tuning. Based on the alignment results, we propose a multi-modal classifier to predict mistake labels. In our experiments, the proposed methods achieve higher performance than the baselines. In addition, our ablation study demonstrates the effectiveness of combining videos and texts. We will release the dataset and codes upon publication.
BioVL-QR: Egocentric Biochemical Video-and-Language Dataset Using Micro QR Codes
Apr 04, 2024This paper introduces a biochemical vision-and-language dataset, which consists of 24 egocentric experiment videos, corresponding protocols, and video-and-language alignments. The key challenge in the wet-lab domain is detecting equipment, reagents, and containers is difficult because the lab environment is scattered by filling objects on the table and some objects are indistinguishable. Therefore, previous studies assume that objects are manually annotated and given for downstream tasks, but this is costly and time-consuming. To address this issue, this study focuses on Micro QR Codes to detect objects automatically. From our preliminary study, we found that detecting objects only using Micro QR Codes is still difficult because the researchers manipulate objects, causing blur and occlusion frequently. To address this, we also propose a novel object labeling method by combining a Micro QR Code detector and an off-the-shelf hand object detector. As one of the applications of our dataset, we conduct the task of generating protocols from experiment videos and find that our approach can generate accurate protocols.
Automatic Construction of a Large-Scale Corpus for Geoparsing Using Wikipedia Hyperlinks
Mar 25, 2024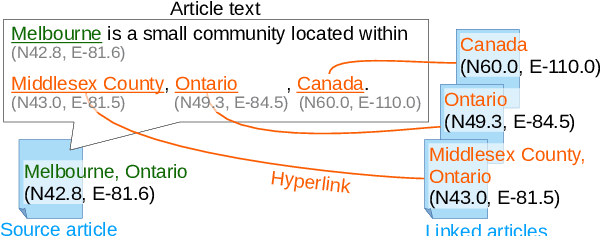
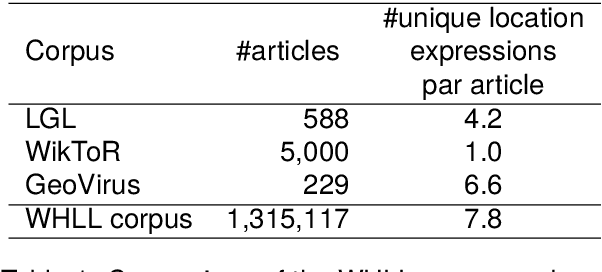

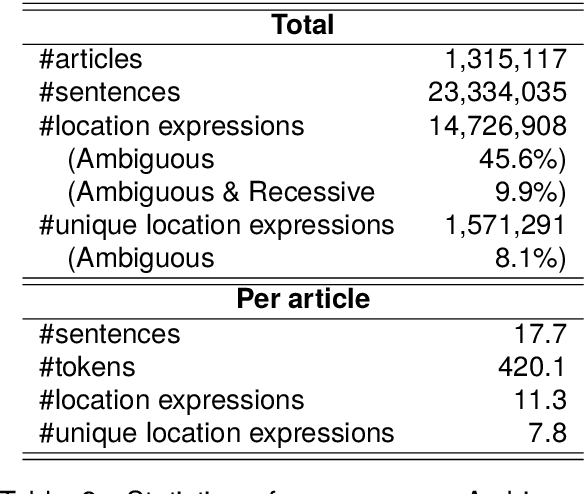
Geoparsing is the task of estimating the latitude and longitude (coordinates) of location expressions in texts. Geoparsing must deal with the ambiguity of the expressions that indicate multiple locations with the same notation. For evaluating geoparsing systems, several corpora have been proposed in previous work. However, these corpora are small-scale and suffer from the coverage of location expressions on general domains. In this paper, we propose Wikipedia Hyperlink-based Location Linking (WHLL), a novel method to construct a large-scale corpus for geoparsing from Wikipedia articles. WHLL leverages hyperlinks in Wikipedia to annotate multiple location expressions with coordinates. With this method, we constructed the WHLL corpus, a new large-scale corpus for geoparsing. The WHLL corpus consists of 1.3M articles, each containing about 7.8 unique location expressions. 45.6% of location expressions are ambiguous and refer to more than one location with the same notation. In each article, location expressions of the article title and those hyperlinks to other articles are assigned with coordinates. By utilizing hyperlinks, we can accurately assign location expressions with coordinates even with ambiguous location expressions in the texts. Experimental results show that there remains room for improvement by disambiguating location expressions.
Towards Flow Graph Prediction of Open-Domain Procedural Texts
May 31, 2023Machine comprehension of procedural texts is essential for reasoning about the steps and automating the procedures. However, this requires identifying entities within a text and resolving the relationships between the entities. Previous work focused on the cooking domain and proposed a framework to convert a recipe text into a flow graph (FG) representation. In this work, we propose a framework based on the recipe FG for flow graph prediction of open-domain procedural texts. To investigate flow graph prediction performance in non-cooking domains, we introduce the wikiHow-FG corpus from articles on wikiHow, a website of how-to instruction articles. In experiments, we consider using the existing recipe corpus and performing domain adaptation from the cooking to the target domain. Experimental results show that the domain adaptation models achieve higher performance than those trained only on the cooking or target domain data.
Recipe Generation from Unsegmented Cooking Videos
Sep 21, 2022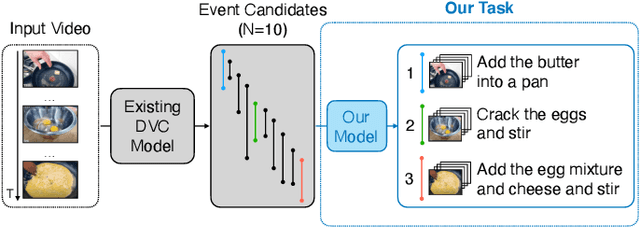
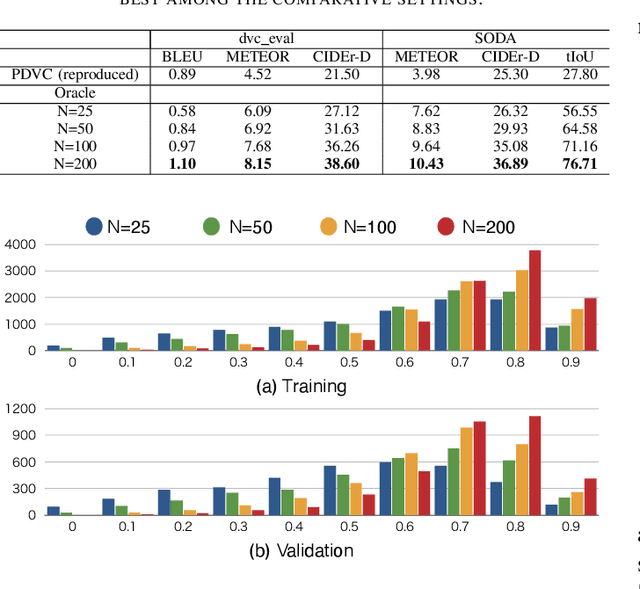
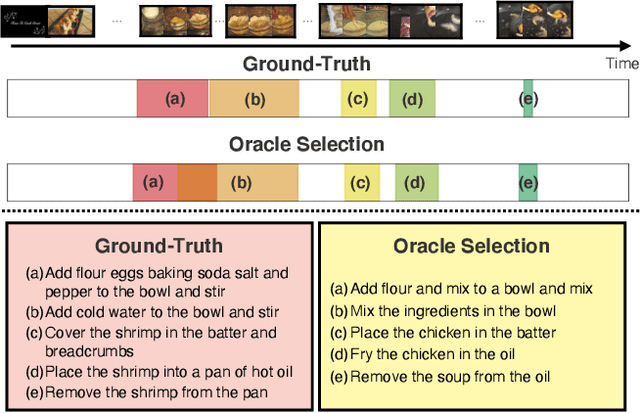
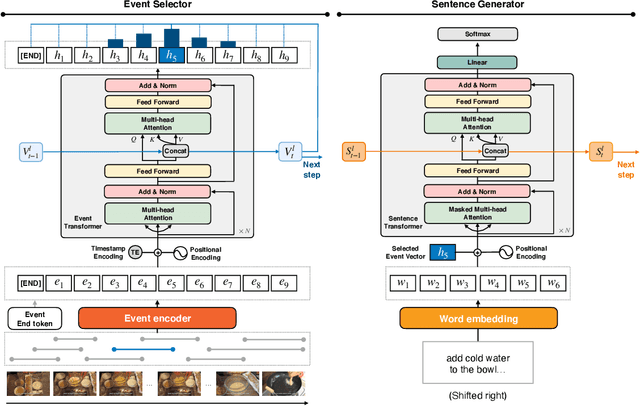
This paper tackles recipe generation from unsegmented cooking videos, a task that requires agents to (1) extract key events in completing the dish and (2) generate sentences for the extracted events. Our task is similar to dense video captioning (DVC), which aims at detecting events thoroughly and generating sentences for them. However, unlike DVC, in recipe generation, recipe story awareness is crucial, and a model should output an appropriate number of key events in the correct order. We analyze the output of the DVC model and observe that although (1) several events are adoptable as a recipe story, (2) the generated sentences for such events are not grounded in the visual content. Based on this, we hypothesize that we can obtain correct recipes by selecting oracle events from the output events of the DVC model and re-generating sentences for them. To achieve this, we propose a novel transformer-based joint approach of training event selector and sentence generator for selecting oracle events from the outputs of the DVC model and generating grounded sentences for the events, respectively. In addition, we extend the model by including ingredients to generate more accurate recipes. The experimental results show that the proposed method outperforms state-of-the-art DVC models. We also confirm that, by modeling the recipe in a story-aware manner, the proposed model output the appropriate number of events in the correct order.
Visual Recipe Flow: A Dataset for Learning Visual State Changes of Objects with Recipe Flows
Sep 13, 2022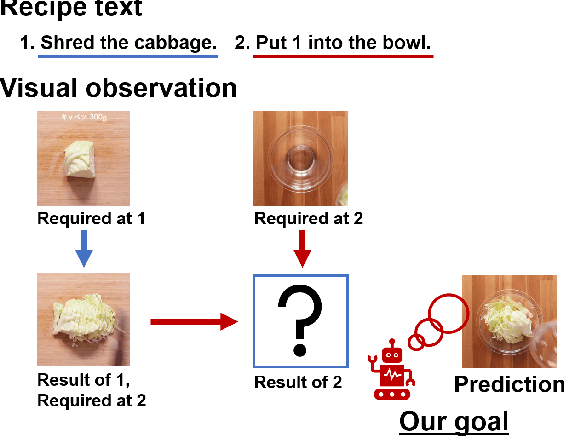

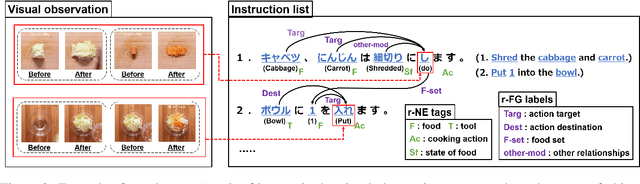
We present a new multimodal dataset called Visual Recipe Flow, which enables us to learn each cooking action result in a recipe text. The dataset consists of object state changes and the workflow of the recipe text. The state change is represented as an image pair, while the workflow is represented as a recipe flow graph (r-FG). The image pairs are grounded in the r-FG, which provides the cross-modal relation. With our dataset, one can try a range of applications, from multimodal commonsense reasoning and procedural text generation.