 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecipe Generation from Unsegmented Cooking Videos
Paper and Code
Sep 21, 2022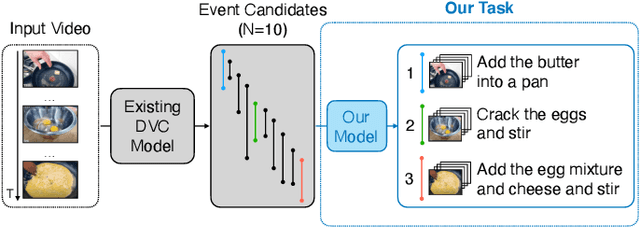
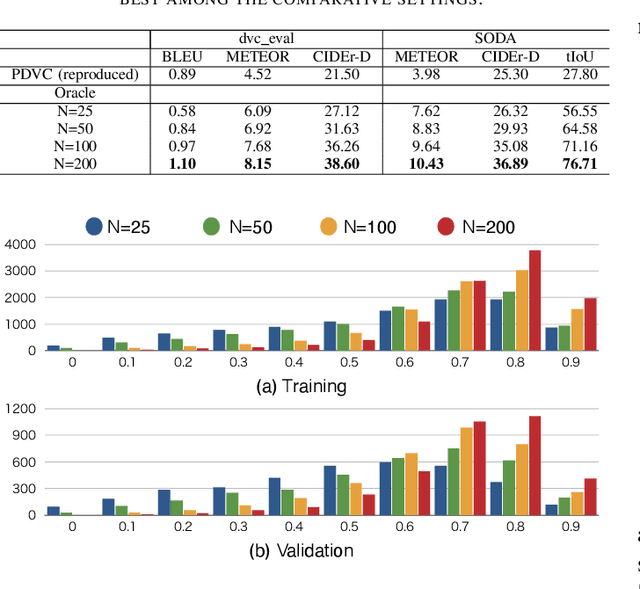
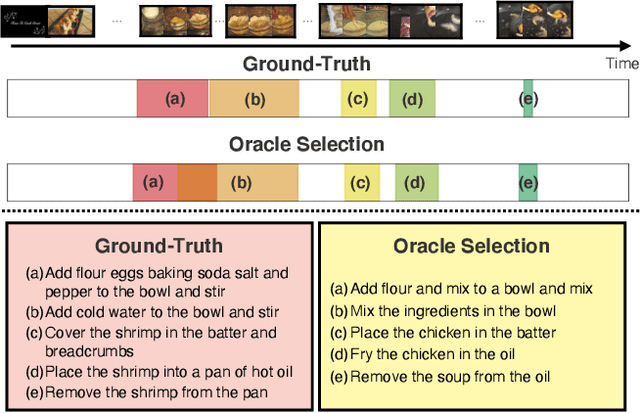
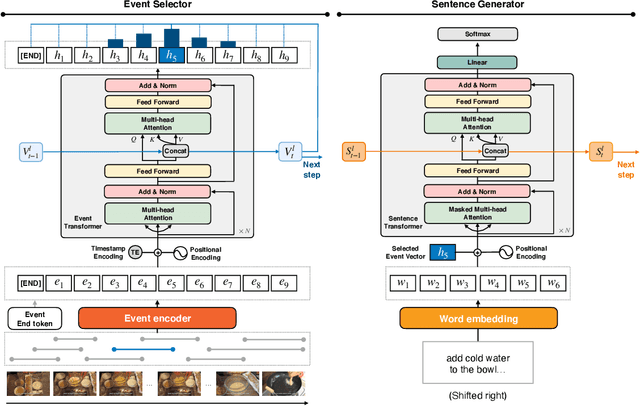
This paper tackles recipe generation from unsegmented cooking videos, a task that requires agents to (1) extract key events in completing the dish and (2) generate sentences for the extracted events. Our task is similar to dense video captioning (DVC), which aims at detecting events thoroughly and generating sentences for them. However, unlike DVC, in recipe generation, recipe story awareness is crucial, and a model should output an appropriate number of key events in the correct order. We analyze the output of the DVC model and observe that although (1) several events are adoptable as a recipe story, (2) the generated sentences for such events are not grounded in the visual content. Based on this, we hypothesize that we can obtain correct recipes by selecting oracle events from the output events of the DVC model and re-generating sentences for them. To achieve this, we propose a novel transformer-based joint approach of training event selector and sentence generator for selecting oracle events from the outputs of the DVC model and generating grounded sentences for the events, respectively. In addition, we extend the model by including ingredients to generate more accurate recipes. The experimental results show that the proposed method outperforms state-of-the-art DVC models. We also confirm that, by modeling the recipe in a story-aware manner, the proposed model output the appropriate number of events in the correct order.