 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiLexNorm++: A Unified Benchmark and a Generative Model for Lexical Normalization for Asian Languages
Jan 23, 2026Social media data has been of interest to Natural Language Processing (NLP) practitioners for over a decade, because of its richness in information, but also challenges for automatic processing. Since language use is more informal, spontaneous, and adheres to many different sociolects, the performance of NLP models often deteriorates. One solution to this problem is to transform data to a standard variant before processing it, which is also called lexical normalization. There has been a wide variety of benchmarks and models proposed for this task. The MultiLexNorm benchmark proposed to unify these efforts, but it consists almost solely of languages from the Indo-European language family in the Latin script. Hence, we propose an extension to MultiLexNorm, which covers 5 Asian languages from different language families in 4 different scripts. We show that the previous state-of-the-art model performs worse on the new languages and propose a new architecture based on Large Language Models (LLMs), which shows more robust performance. Finally, we analyze remaining errors, revealing future directions for this task.
Edit-Constrained Decoding for Sentence Simplification
Sep 28, 2024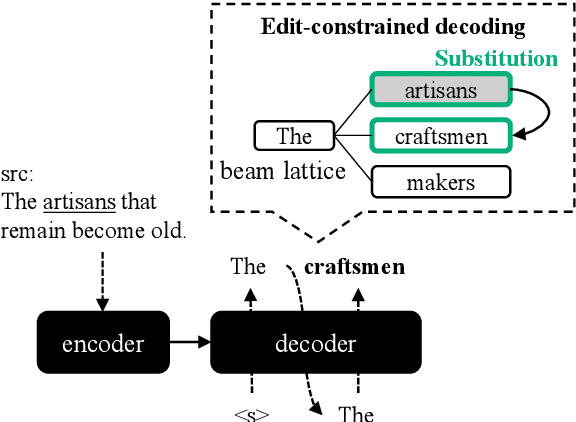
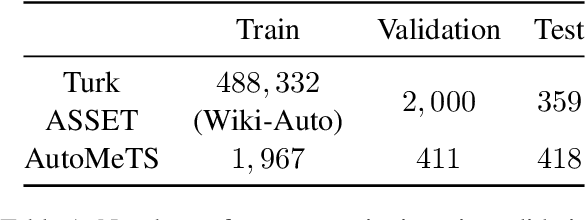
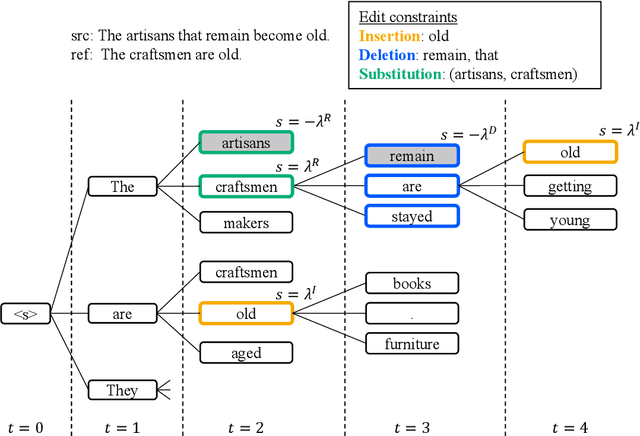
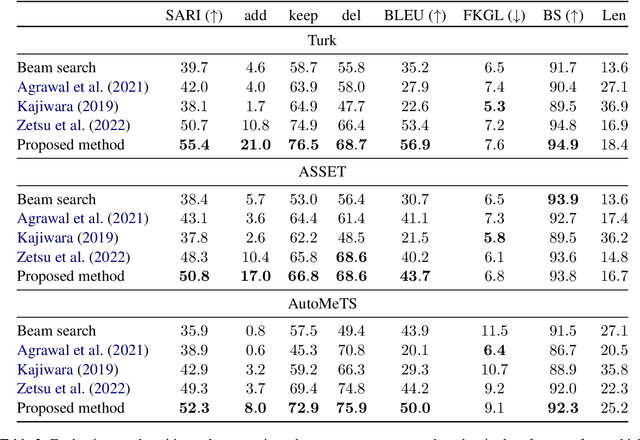
We propose edit operation based lexically constrained decoding for sentence simplification. In sentence simplification, lexical paraphrasing is one of the primary procedures for rewriting complex sentences into simpler correspondences. While previous studies have confirmed the efficacy of lexically constrained decoding on this task, their constraints can be loose and may lead to sub-optimal generation. We address this problem by designing constraints that replicate the edit operations conducted in simplification and defining stricter satisfaction conditions. Our experiments indicate that the proposed method consistently outperforms the previous studies on three English simplification corpora commonly used in this task.
Distilling Monolingual and Crosslingual Word-in-Context Representations
Sep 13, 2024In this study, we propose a method that distils representations of word meaning in context from a pre-trained masked language model in both monolingual and crosslingual settings. Word representations are the basis for context-aware lexical semantics and unsupervised semantic textual similarity (STS) estimation. Different from existing approaches, our method does not require human-annotated corpora nor updates of the parameters of the pre-trained model. The latter feature is appealing for practical scenarios where the off-the-shelf pre-trained model is a common asset among different applications. Specifically, our method learns to combine the outputs of different hidden layers of the pre-trained model using self-attention. Our auto-encoder based training only requires an automatically generated corpus. To evaluate the performance of the proposed approach, we performed extensive experiments using various benchmark tasks. The results on the monolingual tasks confirmed that our representations exhibited a competitive performance compared to that of the previous study for the context-aware lexical semantic tasks and outperformed it for STS estimation. The results of the crosslingual tasks revealed that the proposed method largely improved crosslingual word representations of multilingual pre-trained models.
Unsupervised Translation Quality Estimation Exploiting Synthetic Data and Pre-trained Multilingual Encoder
Nov 09, 2023Translation quality estimation (TQE) is the task of predicting translation quality without reference translations. Due to the enormous cost of creating training data for TQE, only a few translation directions can benefit from supervised training. To address this issue, unsupervised TQE methods have been studied. In this paper, we extensively investigate the usefulness of synthetic TQE data and pre-trained multilingual encoders in unsupervised sentence-level TQE, both of which have been proven effective in the supervised training scenarios. Our experiment on WMT20 and WMT21 datasets revealed that this approach can outperform other unsupervised TQE methods on high- and low-resource translation directions in predicting post-editing effort and human evaluation score, and some zero-resource translation directions in predicting post-editing effort.
Machine Translation Evaluation with BERT Regressor
Jul 29, 2019



We introduce the metric using BERT (Bidirectional Encoder Representations from Transformers) (Devlin et al., 2019) for automatic machine translation evaluation. The experimental results of the WMT-2017 Metrics Shared Task dataset show that our metric achieves state-of-the-art performance in segment-level metrics task for all to-English language pairs.
Using Natural Language Processing to Develop an Automated Orthodontic Diagnostic System
May 31, 2019


We work on the task of automatically designing a treatment plan from the findings included in the medical certificate written by the dentist. To develop an artificial intelligence system that deals with free-form certificates written by dentists, we annotate the findings and utilized the natural language processing approach. As a result of the experiment using 990 certificates, 0.585 F1-score was achieved for the task of extracting orthodontic problems from findings, and 0.584 correlation coefficient with the human ranking was achieved for the treatment prioritization task.
Metric for Automatic Machine Translation Evaluation based on Universal Sentence Representations
May 18, 2018


Sentence representations can capture a wide range of information that cannot be captured by local features based on character or word N-grams. This paper examines the usefulness of universal sentence representations for evaluating the quality of machine translation. Although it is difficult to train sentence representations using small-scale translation datasets with manual evaluation, sentence representations trained from large-scale data in other tasks can improve the automatic evaluation of machine translation. Experimental results of the WMT-2016 dataset show that the proposed method achieves state-of-the-art performance with sentence representation features only.