 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo More K-means:Single-Stage Sparse Coding for Efficient Multi-Vector Retrieval
May 28, 2026Multi-vector retrieval (MVR) models, exemplified by ColBERT, have established new benchmarks in retrieval accuracy by preserving fine-grained token-level interactions. However, this granularity imposes prohibitive storage and retrieval efficiency bottlenecks: to manage the immense memory footprint and computational overhead of billion-scale token vectors, state-of-the-art systems are forced to rely on aggressive dimension reduction and complex clustering (e.g., K-means). This compromise introduces two critical limitations: excessive indexing latency of clustering large-scale corpora and semantic information loss inherent to compression. In this paper, we propose Single-stage Sparse Retrieval (SSR}, a paradigm shift that replaces expensive clustering with efficient sparse coding. Instead of compressing features into low-dimensional dense vectors, we utilize Sparse Autoencoder (SAE) to project token embeddings into a high-dimensional but highly sparse representation. This transformation enables us to bypass vector clustering entirely and leverage inverted indexing for precise, high-throughput retrieval. Extensive experiments on the BEIR benchmark demonstrate that SSR achieves a "trifecta" of improvements: it reduces indexing time by 15x compared to ColBERTv2, halves retrieval latency, and simultaneously improves retrieval performance over leading baselines.
CSRv2: Unlocking Ultra-Sparse Embeddings
Feb 05, 2026In the era of large foundation models, the quality of embeddings has become a central determinant of downstream task performance and overall system capability. Yet widely used dense embeddings are often extremely high-dimensional, incurring substantial costs in storage, memory, and inference latency. To address these, Contrastive Sparse Representation (CSR) is recently proposed as a promising direction, mapping dense embeddings into high-dimensional but k-sparse vectors, in contrast to compact dense embeddings such as Matryoshka Representation Learning (MRL). Despite its promise, CSR suffers severe degradation in the ultra-sparse regime, where over 80% of neurons remain inactive, leaving much of its efficiency potential unrealized. In this paper, we introduce CSRv2, a principled training approach designed to make ultra-sparse embeddings viable. CSRv2 stabilizes sparsity learning through progressive k-annealing, enhances representational quality via supervised contrastive objectives, and ensures end-to-end adaptability with full backbone finetuning. CSRv2 reduces dead neurons from 80% to 20% and delivers a 14% accuracy gain at k=2, bringing ultra-sparse embeddings on par with CSR at k=8 and MRL at 32 dimensions, all with only two active features. While maintaining comparable performance, CSRv2 delivers a 7x speedup over MRL, and yields up to 300x improvements in compute and memory efficiency relative to dense embeddings in text representation. Extensive experiments across text and vision demonstrate that CSRv2 makes ultra-sparse embeddings practical without compromising performance, where CSRv2 achieves 7%/4% improvement over CSR when k=4 and further increases this gap to 14%/6% when k=2 in text/vision representation. By making extreme sparsity viable, CSRv2 broadens the design space for real-time and edge-deployable AI systems where both embedding quality and efficiency are critical.
Route Experts by Sequence, not by Token
Nov 09, 2025Mixture-of-Experts (MoE) architectures scale large language models (LLMs) by activating only a subset of experts per token, but the standard TopK routing assigns the same fixed number of experts to all tokens, ignoring their varying complexity. Prior adaptive routing methods introduce additional modules and hyperparameters, often requiring costly retraining from scratch. We propose Sequence-level TopK (SeqTopK), a minimal modification that shifts the expert budget from the token level to the sequence level. By selecting the top $T \cdot K$ experts across all $T$ tokens, SeqTopK enables end-to-end learned dynamic allocation -- assigning more experts to difficult tokens and fewer to easy ones -- while preserving the same overall budget. SeqTopK requires only a few lines of code, adds less than 1% overhead, and remains fully compatible with pretrained MoE models. Experiments across math, coding, law, and writing show consistent improvements over TopK and prior parameter-free adaptive methods, with gains that become substantially larger under higher sparsity (up to 16.9%). These results highlight SeqTopK as a simple, efficient, and scalable routing strategy, particularly well-suited for the extreme sparsity regimes of next-generation LLMs. Code is available at https://github.com/Y-Research-SBU/SeqTopK.
Beyond Matryoshka: Revisiting Sparse Coding for Adaptive Representation
Mar 05, 2025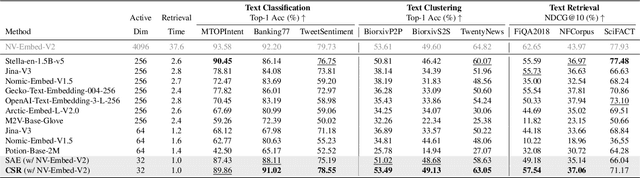
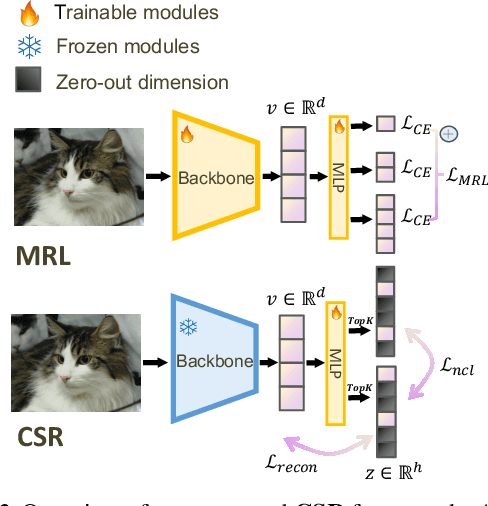
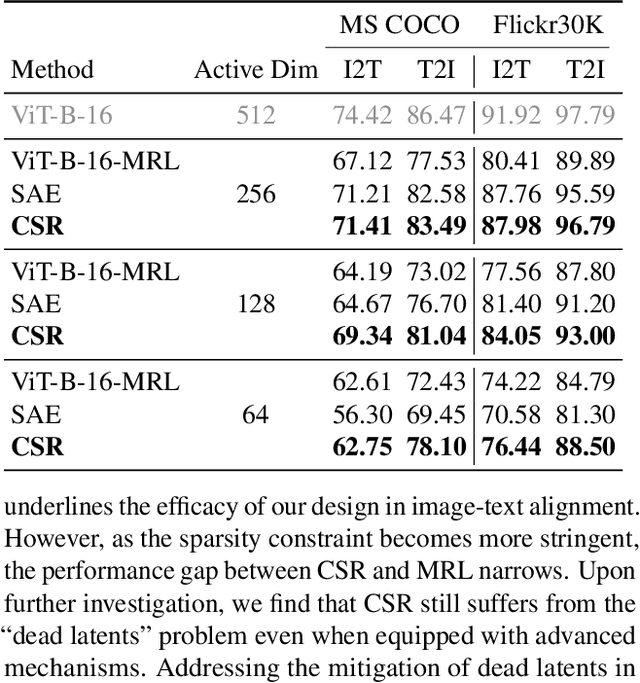
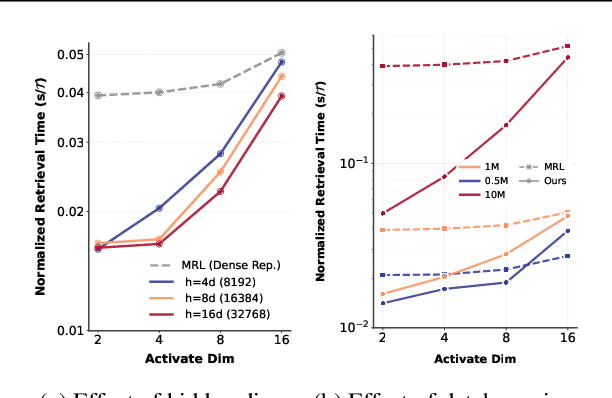
Many large-scale systems rely on high-quality deep representations (embeddings) to facilitate tasks like retrieval, search, and generative modeling. Matryoshka Representation Learning (MRL) recently emerged as a solution for adaptive embedding lengths, but it requires full model retraining and suffers from noticeable performance degradations at short lengths. In this paper, we show that sparse coding offers a compelling alternative for achieving adaptive representation with minimal overhead and higher fidelity. We propose Contrastive Sparse Representation (CSR), a method that sparsifies pre-trained embeddings into a high-dimensional but selectively activated feature space. By leveraging lightweight autoencoding and task-aware contrastive objectives, CSR preserves semantic quality while allowing flexible, cost-effective inference at different sparsity levels. Extensive experiments on image, text, and multimodal benchmarks demonstrate that CSR consistently outperforms MRL in terms of both accuracy and retrieval speed-often by large margins-while also cutting training time to a fraction of that required by MRL. Our results establish sparse coding as a powerful paradigm for adaptive representation learning in real-world applications where efficiency and fidelity are both paramount. Code is available at https://github.com/neilwen987/CSR_Adaptive_Rep
A Non-negative VAE:the Generalized Gamma Belief Network
Aug 06, 2024The gamma belief network (GBN), often regarded as a deep topic model, has demonstrated its potential for uncovering multi-layer interpretable latent representations in text data. Its notable capability to acquire interpretable latent factors is partially attributed to sparse and non-negative gamma-distributed latent variables. However, the existing GBN and its variations are constrained by the linear generative model, thereby limiting their expressiveness and applicability. To address this limitation, we introduce the generalized gamma belief network (Generalized GBN) in this paper, which extends the original linear generative model to a more expressive non-linear generative model. Since the parameters of the Generalized GBN no longer possess an analytic conditional posterior, we further propose an upward-downward Weibull inference network to approximate the posterior distribution of the latent variables. The parameters of both the generative model and the inference network are jointly trained within the variational inference framework. Finally, we conduct comprehensive experiments on both expressivity and disentangled representation learning tasks to evaluate the performance of the Generalized GBN against state-of-the-art Gaussian variational autoencoders serving as baselines.
Contrastive Factor Analysis
Aug 01, 2024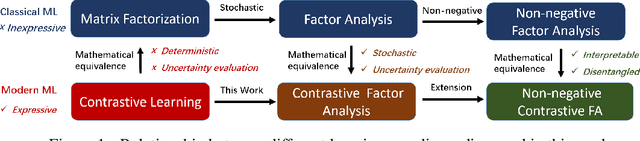



Factor analysis, often regarded as a Bayesian variant of matrix factorization, offers superior capabilities in capturing uncertainty, modeling complex dependencies, and ensuring robustness. As the deep learning era arrives, factor analysis is receiving less and less attention due to their limited expressive ability. On the contrary, contrastive learning has emerged as a potent technique with demonstrated efficacy in unsupervised representational learning. While the two methods are different paradigms, recent theoretical analysis has revealed the mathematical equivalence between contrastive learning and matrix factorization, providing a potential possibility for factor analysis combined with contrastive learning. Motivated by the interconnectedness of contrastive learning, matrix factorization, and factor analysis, this paper introduces a novel Contrastive Factor Analysis framework, aiming to leverage factor analysis's advantageous properties within the realm of contrastive learning. To further leverage the interpretability properties of non-negative factor analysis, which can learn disentangled representations, contrastive factor analysis is extended to a non-negative version. Finally, extensive experimental validation showcases the efficacy of the proposed contrastive (non-negative) factor analysis methodology across multiple key properties, including expressiveness, robustness, interpretability, and accurate uncertainty estimation.
HICEScore: A Hierarchical Metric for Image Captioning Evaluation
Jul 26, 2024



Image captioning evaluation metrics can be divided into two categories, reference-based metrics and reference-free metrics. However, reference-based approaches may struggle to evaluate descriptive captions with abundant visual details produced by advanced multimodal large language models, due to their heavy reliance on limited human-annotated references. In contrast, previous reference-free metrics have been proven effective via CLIP cross-modality similarity. Nonetheless, CLIP-based metrics, constrained by their solution of global image-text compatibility, often have a deficiency in detecting local textual hallucinations and are insensitive to small visual objects. Besides, their single-scale designs are unable to provide an interpretable evaluation process such as pinpointing the position of caption mistakes and identifying visual regions that have not been described. To move forward, we propose a novel reference-free metric for image captioning evaluation, dubbed Hierarchical Image Captioning Evaluation Score (HICE-S). By detecting local visual regions and textual phrases, HICE-S builds an interpretable hierarchical scoring mechanism, breaking through the barriers of the single-scale structure of existing reference-free metrics. Comprehensive experiments indicate that our proposed metric achieves the SOTA performance on several benchmarks, outperforming existing reference-free metrics like CLIP-S and PAC-S, and reference-based metrics like METEOR and CIDEr. Moreover, several case studies reveal that the assessment process of HICE-S on detailed captions closely resembles interpretable human judgments.Our code is available at https://github.com/joeyz0z/HICE.