 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Matryoshka: Revisiting Sparse Coding for Adaptive Representation
Mar 05, 2025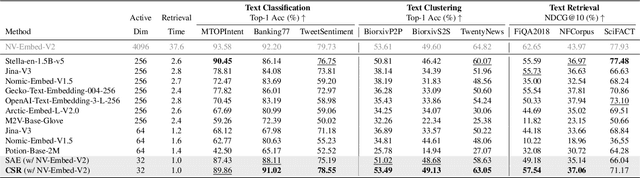
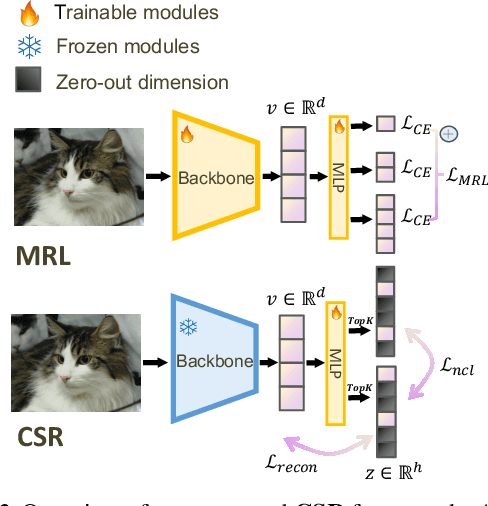
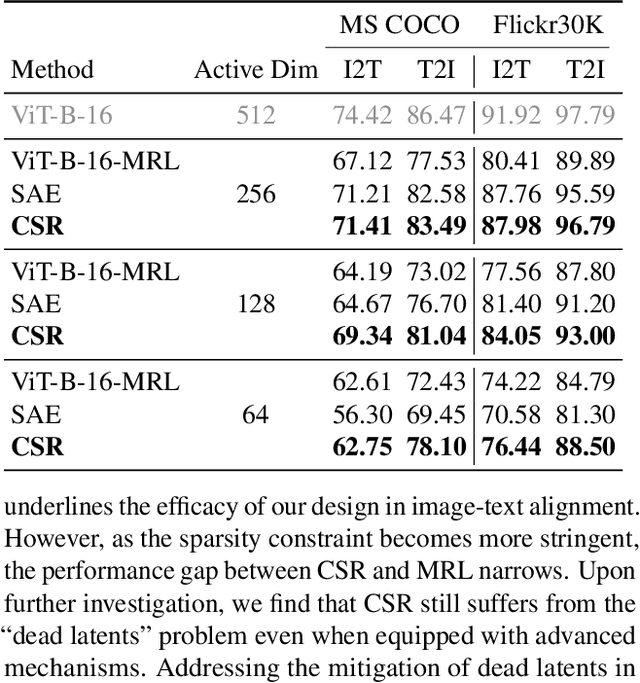
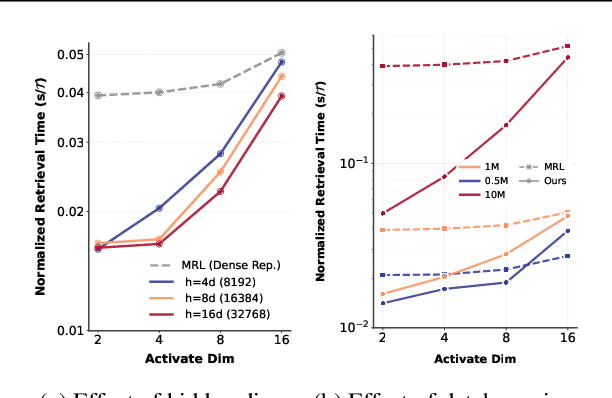
Many large-scale systems rely on high-quality deep representations (embeddings) to facilitate tasks like retrieval, search, and generative modeling. Matryoshka Representation Learning (MRL) recently emerged as a solution for adaptive embedding lengths, but it requires full model retraining and suffers from noticeable performance degradations at short lengths. In this paper, we show that sparse coding offers a compelling alternative for achieving adaptive representation with minimal overhead and higher fidelity. We propose Contrastive Sparse Representation (CSR), a method that sparsifies pre-trained embeddings into a high-dimensional but selectively activated feature space. By leveraging lightweight autoencoding and task-aware contrastive objectives, CSR preserves semantic quality while allowing flexible, cost-effective inference at different sparsity levels. Extensive experiments on image, text, and multimodal benchmarks demonstrate that CSR consistently outperforms MRL in terms of both accuracy and retrieval speed-often by large margins-while also cutting training time to a fraction of that required by MRL. Our results establish sparse coding as a powerful paradigm for adaptive representation learning in real-world applications where efficiency and fidelity are both paramount. Code is available at https://github.com/neilwen987/CSR_Adaptive_Rep
HICEScore: A Hierarchical Metric for Image Captioning Evaluation
Jul 26, 2024



Image captioning evaluation metrics can be divided into two categories, reference-based metrics and reference-free metrics. However, reference-based approaches may struggle to evaluate descriptive captions with abundant visual details produced by advanced multimodal large language models, due to their heavy reliance on limited human-annotated references. In contrast, previous reference-free metrics have been proven effective via CLIP cross-modality similarity. Nonetheless, CLIP-based metrics, constrained by their solution of global image-text compatibility, often have a deficiency in detecting local textual hallucinations and are insensitive to small visual objects. Besides, their single-scale designs are unable to provide an interpretable evaluation process such as pinpointing the position of caption mistakes and identifying visual regions that have not been described. To move forward, we propose a novel reference-free metric for image captioning evaluation, dubbed Hierarchical Image Captioning Evaluation Score (HICE-S). By detecting local visual regions and textual phrases, HICE-S builds an interpretable hierarchical scoring mechanism, breaking through the barriers of the single-scale structure of existing reference-free metrics. Comprehensive experiments indicate that our proposed metric achieves the SOTA performance on several benchmarks, outperforming existing reference-free metrics like CLIP-S and PAC-S, and reference-based metrics like METEOR and CIDEr. Moreover, several case studies reveal that the assessment process of HICE-S on detailed captions closely resembles interpretable human judgments.Our code is available at https://github.com/joeyz0z/HICE.
SnapCap: Efficient Snapshot Compressive Video Captioning
Jan 10, 2024Video Captioning (VC) is a challenging multi-modal task since it requires describing the scene in language by understanding various and complex videos. For machines, the traditional VC follows the "imaging-compression-decoding-and-then-captioning" pipeline, where compression is pivot for storage and transmission. However, in such a pipeline, some potential shortcomings are inevitable, i.e., information redundancy resulting in low efficiency and information loss during the sampling process for captioning. To address these problems, in this paper, we propose a novel VC pipeline to generate captions directly from the compressed measurement, which can be captured by a snapshot compressive sensing camera and we dub our model SnapCap. To be more specific, benefiting from the signal simulation, we have access to obtain abundant measurement-video-annotation data pairs for our model. Besides, to better extract language-related visual representations from the compressed measurement, we propose to distill the knowledge from videos via a pre-trained CLIP with plentiful language-vision associations to guide the learning of our SnapCap. To demonstrate the effectiveness of SnapCap, we conduct experiments on two widely-used VC datasets. Both the qualitative and quantitative results verify the superiority of our pipeline over conventional VC pipelines. In particular, compared to the "caption-after-reconstruction" methods, our SnapCap can run at least 3$\times$ faster, and achieve better caption results.