 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Limit of Outcome Reward for Learning Mathematical Reasoning
Feb 10, 2025Reasoning abilities, especially those for solving complex math problems, are crucial components of general intelligence. Recent advances by proprietary companies, such as o-series models of OpenAI, have made remarkable progress on reasoning tasks. However, the complete technical details remain unrevealed, and the techniques that are believed certainly to be adopted are only reinforcement learning (RL) and the long chain of thoughts. This paper proposes a new RL framework, termed OREAL, to pursue the performance limit that can be achieved through \textbf{O}utcome \textbf{RE}w\textbf{A}rd-based reinforcement \textbf{L}earning for mathematical reasoning tasks, where only binary outcome rewards are easily accessible. We theoretically prove that behavior cloning on positive trajectories from best-of-N (BoN) sampling is sufficient to learn the KL-regularized optimal policy in binary feedback environments. This formulation further implies that the rewards of negative samples should be reshaped to ensure the gradient consistency between positive and negative samples. To alleviate the long-existing difficulties brought by sparse rewards in RL, which are even exacerbated by the partial correctness of the long chain of thought for reasoning tasks, we further apply a token-level reward model to sample important tokens in reasoning trajectories for learning. With OREAL, for the first time, a 7B model can obtain 94.0 pass@1 accuracy on MATH-500 through RL, being on par with 32B models. OREAL-32B also surpasses previous 32B models trained by distillation with 95.0 pass@1 accuracy on MATH-500. Our investigation also indicates the importance of initial policy models and training queries for RL. Code, models, and data will be released to benefit future research\footnote{https://github.com/InternLM/OREAL}.
Training Language Models to Critique With Multi-agent Feedback
Oct 20, 2024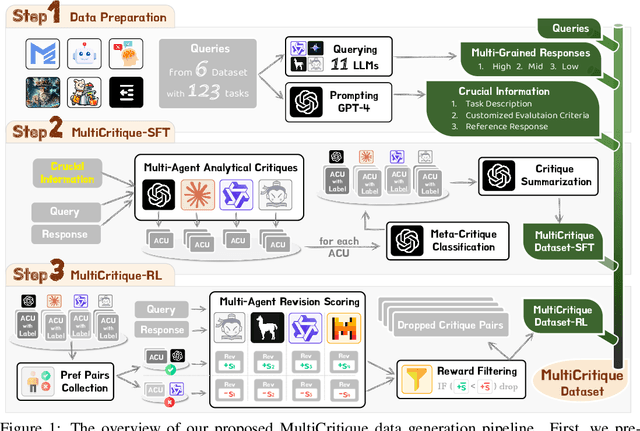
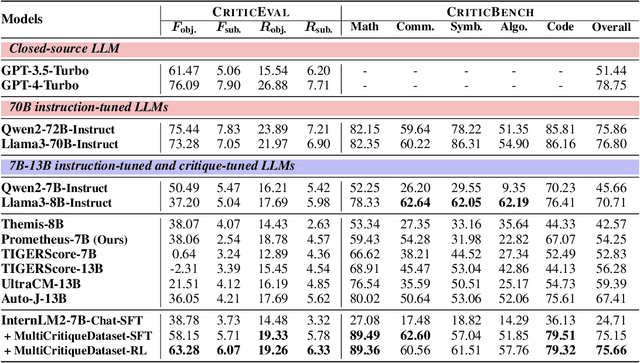
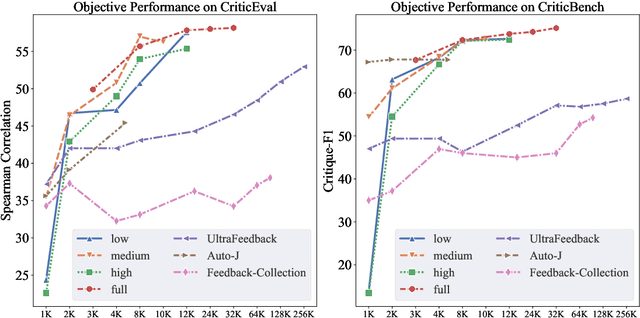
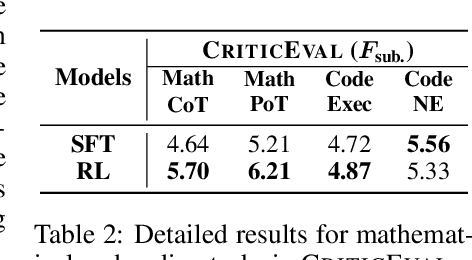
Critique ability, a meta-cognitive capability of humans, presents significant challenges for LLMs to improve. Recent works primarily rely on supervised fine-tuning (SFT) using critiques generated by a single LLM like GPT-4. However, these model-generated critiques often exhibit flaws due to the inherent complexity of the critique. Consequently, fine-tuning LLMs on such flawed critiques typically limits the model's performance and propagates these flaws into the learned model. To overcome these challenges, this paper proposes a novel data generation pipeline, named MultiCritique, that improves the critique ability of LLMs by utilizing multi-agent feedback in both the SFT and reinforcement learning (RL) stages. First, our data generation pipeline aggregates high-quality critiques from multiple agents instead of a single model, with crucial information as input for simplifying the critique. Furthermore, our pipeline improves the preference accuracy of critique quality through multi-agent feedback, facilitating the effectiveness of RL in improving the critique ability of LLMs. Based on our proposed MultiCritique data generation pipeline, we construct the MultiCritiqueDataset for the SFT and RL fine-tuning stages. Extensive experimental results on two benchmarks demonstrate: 1) the superior quality of our constructed SFT dataset compared to existing critique datasets; 2) additional improvements to the critique ability of LLMs brought by the RL stage. Notably, our fine-tuned 7B model significantly surpasses other advanced 7B-13B open-source models, approaching the performance of advanced 70B LLMs and GPT-4. Codes, datasets and model weights will be publicly available.
InternLM2 Technical Report
Mar 26, 2024



The evolution of Large Language Models (LLMs) like ChatGPT and GPT-4 has sparked discussions on the advent of Artificial General Intelligence (AGI). However, replicating such advancements in open-source models has been challenging. This paper introduces InternLM2, an open-source LLM that outperforms its predecessors in comprehensive evaluations across 6 dimensions and 30 benchmarks, long-context modeling, and open-ended subjective evaluations through innovative pre-training and optimization techniques. The pre-training process of InternLM2 is meticulously detailed, highlighting the preparation of diverse data types including text, code, and long-context data. InternLM2 efficiently captures long-term dependencies, initially trained on 4k tokens before advancing to 32k tokens in pre-training and fine-tuning stages, exhibiting remarkable performance on the 200k ``Needle-in-a-Haystack" test. InternLM2 is further aligned using Supervised Fine-Tuning (SFT) and a novel Conditional Online Reinforcement Learning from Human Feedback (COOL RLHF) strategy that addresses conflicting human preferences and reward hacking. By releasing InternLM2 models in different training stages and model sizes, we provide the community with insights into the model's evolution.
InternLM-Math: Open Math Large Language Models Toward Verifiable Reasoning
Feb 09, 2024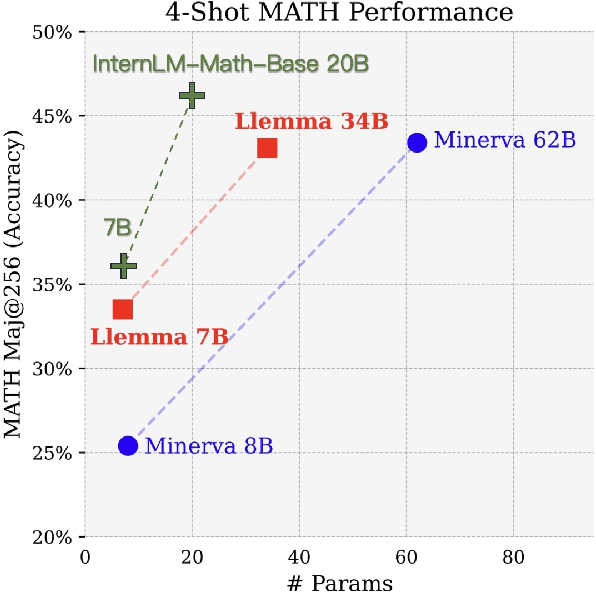
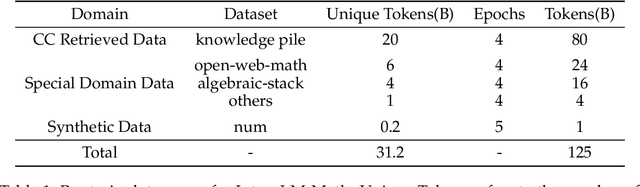
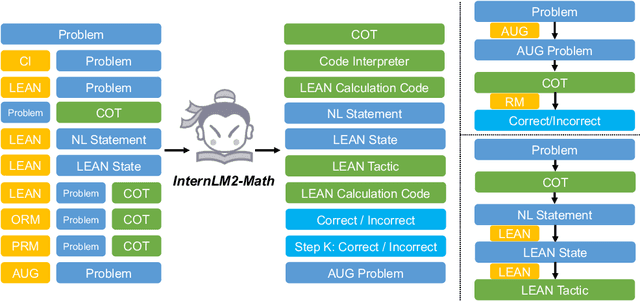
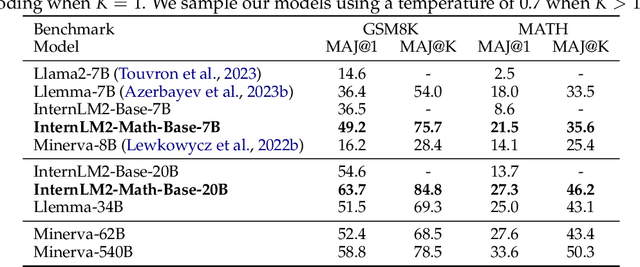
The math abilities of large language models can represent their abstract reasoning ability. In this paper, we introduce and open-source our math reasoning LLMs InternLM-Math which is continue pre-trained from InternLM2. We unify chain-of-thought reasoning, reward modeling, formal reasoning, data augmentation, and code interpreter in a unified seq2seq format and supervise our model to be a versatile math reasoner, verifier, prover, and augmenter. These abilities can be used to develop the next math LLMs or self-iteration. InternLM-Math obtains open-sourced state-of-the-art performance under the setting of in-context learning, supervised fine-tuning, and code-assisted reasoning in various informal and formal benchmarks including GSM8K, MATH, Hungary math exam, MathBench-ZH, and MiniF2F. Our pre-trained model achieves 30.3 on the MiniF2F test set without fine-tuning. We further explore how to use LEAN to solve math problems and study its performance under the setting of multi-task learning which shows the possibility of using LEAN as a unified platform for solving and proving in math. Our models, codes, and data are released at \url{https://github.com/InternLM/InternLM-Math}.