 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOdysSim: Building Foundation Models for Human Behavior Simulation
Jun 12, 2026Large language models are increasingly deployed as human simulators for interactive evaluation and social simulation. Yet helpfulness-driven post-training pulls them toward a homogeneous, overly agreeable assistant register, creating a behavioral Sim2Real gap. We present OdysSim, the largest open systematic investigation of behavioral foundation models, i.e., models trained to simulate human behavior at scale. We propose SOUL, a taxonomy of five capability axes (CONV, SS, COG, ROLE, EVAL) that unifies 62 datasets and 23 benchmark tasks under one framework. Specifically, we curate the OdysSim corpus (21.4M interactions, 10B tokens, retrofitted with back-generated social contexts), construct the SOUL-Index benchmark, and develop an end-to-end training recipe combining midtraining, task-specific RL, and expert distillation. The resulting open 8B OSim model ranks first or tied-first on 8 of 23 tasks, outperforming any individual frontier model by this count, with the strongest gains on conversational and social tasks. Its outputs are also more human-like in length, formatting, and word choice, and it transfers zero-shot to out-of-distribution user simulation on $τ$-bench, nearly matching real users on reaction alignment (93.2 vs. 93.5). We further show that LLM-as-judge RL induces reward-hacking patterns, and that our detectors can mitigate them during post-training. Together, our findings suggest that behavioral foundation models require rethinking the LLM training paradigm. We release all artifacts to support future research.
Reinforcing Human Behavior Simulation via Verbal Feedback
May 19, 2026Humans learn social norms and behaviors from verbal feedback (e.g., a parent saying "that was rude" or a friend explaining "here's why that hurt"). Yet, learning from feedback for LLMs has largely focused on domains like code and math, where RL rewards are directly verifiable and condensed into scalar values. As LLMs are increasingly used to simulate human behavior, e.g., standing in for users, patients, students, and other personas, there is a pressing need to make them more human-like, which requires embracing a fundamentally different kind of signal: feedback that is verbal, subjective, and multi-faceted. We present DITTO, a model trained by treating verbal feedback as a first-class signal in reinforcement learning. After each rollout, DITTO receives verbal feedback and generates a feedback-conditioned improved rollout; both outputs are jointly optimized with GRPO, distilling verbal guidance into the base policy without requiring feedback at test time. We also introduce SOUL (Simulation gym Of hUman-Like behavior), a unified benchmark and training data suite spanning 10 tasks across six categories: Theory of Mind, character role play, social skill, learner simulation, user simulation, and persona simulation. DITTO achieves an average 36% improvement over the base model and exceeds GPT-5.4 on 6 of 10 SOUL benchmarks, demonstrating that RL with verbal feedback is a promising direction for training LLMs to simulate human behavior.
Why Search When You Can Transfer? Amortized Agentic Workflow Design from Structural Priors
Apr 27, 2026Automated agentic workflow design currently relies on per-task iterative search, which is computationally prohibitive and fails to reuse structural knowledge across tasks. We observe that optimized workflows converge to a small family of domain-specific topologies, suggesting that this combinatorial search is largely redundant. Building on this insight, we propose SWIFT (Synthesizing Workflows via Few-shot Transfer), a framework that amortizes workflow design into reusable structural priors. SWIFT first distills compositional heuristics and output-interface contracts from contrastive analysis of prior search trajectories across source tasks. At inference time, it conditions a single LLM generation pass on these priors together with cross-task workflow demonstrations to synthesize a complete, executable workflow for an unseen target task, bypassing iterative search entirely. On five benchmarks, SWIFT outperforms the state-of-the-art search-based method while reducing marginal per-task optimization cost by three orders of magnitude. It further generalizes to four additional unseen benchmarks and transfers successfully from GPT-4o-mini to three additional foundation models (Grok, Qwen, Gemma). Controlled ablations reveal that workflow demonstrations primarily transfer topological structure rather than surface semantics: replacing all operator names with random strings still retains over 93% of the full system's average performance.
Mind the Sim2Real Gap in User Simulation for Agentic Tasks
Mar 11, 2026As NLP evaluation shifts from static benchmarks to multi-turn interactive settings, LLM-based simulators have become widely used as user proxies, serving two roles: generating user turns and providing evaluation signals. Yet, these simulations are frequently assumed to be faithful to real human behaviors, often without rigorous verification. We formalize the Sim2Real gap in user simulation and present the first study running the full $τ$-bench protocol with real humans (451 participants, 165 tasks), benchmarking 31 LLM simulators across proprietary, open-source, and specialized families using the User-Sim Index (USI), a metric we introduce to quantify how well LLM simulators resemble real user interactive behaviors and feedback. Behaviorally, LLM simulators are excessively cooperative, stylistically uniform, and lack realistic frustration or ambiguity, creating an "easy mode" that inflates agent success rates above the human baseline. In evaluations, real humans provide nuanced judgments across eight quality dimensions while simulated users produce uniformly more positive feedback; rule-based rewards are failing to capture rich feedback signals generated by human users. Overall, higher general model capability does not necessarily yield more faithful user simulation. These findings highlight the importance of human validation when using LLM-based user simulators in the agent development cycle and motivate improved models for user simulation.
GradAlign: Gradient-Aligned Data Selection for LLM Reinforcement Learning
Feb 25, 2026Reinforcement learning (RL) has become a central post-training paradigm for large language models (LLMs), but its performance is highly sensitive to the quality of training problems. This sensitivity stems from the non-stationarity of RL: rollouts are generated by an evolving policy, and learning is shaped by exploration and reward feedback, unlike supervised fine-tuning (SFT) with fixed trajectories. As a result, prior work often relies on manual curation or simple heuristic filters (e.g., accuracy), which can admit incorrect or low-utility problems. We propose GradAlign, a gradient-aligned data selection method for LLM reinforcement learning that uses a small, trusted validation set to prioritize training problems whose policy gradients align with validation gradients, yielding an adaptive curriculum. We evaluate GradAlign across three challenging data regimes: unreliable reward signals, distribution imbalance, and low-utility training corpus, showing that GradAlign consistently outperforms existing baselines, underscoring the importance of directional gradient signals in navigating non-stationary policy optimization and yielding more stable training and improved final performance. We release our implementation at https://github.com/StigLidu/GradAlign
Optimizing Temperature for Language Models with Multi-Sample Inference
Feb 07, 2025Multi-sample aggregation strategies, such as majority voting and best-of-N sampling, are widely used in contemporary large language models (LLMs) to enhance predictive accuracy across various tasks. A key challenge in this process is temperature selection, which significantly impacts model performance. Existing approaches either rely on a fixed default temperature or require labeled validation data for tuning, which are often scarce and difficult to obtain. This paper addresses the challenge of automatically identifying the (near)-optimal temperature for different LLMs using multi-sample aggregation strategies, without relying on task-specific validation data. We provide a comprehensive analysis of temperature's role in performance optimization, considering variations in model architectures, datasets, task types, model sizes, and predictive accuracy. Furthermore, we propose a novel entropy-based metric for automated temperature optimization, which consistently outperforms fixed-temperature baselines. Additionally, we incorporate a stochastic process model to enhance interpretability, offering deeper insights into the relationship between temperature and model performance.
Constrained Human-AI Cooperation: An Inclusive Embodied Social Intelligence Challenge
Nov 05, 2024



We introduce Constrained Human-AI Cooperation (CHAIC), an inclusive embodied social intelligence challenge designed to test social perception and cooperation in embodied agents. In CHAIC, the goal is for an embodied agent equipped with egocentric observations to assist a human who may be operating under physical constraints -- e.g., unable to reach high places or confined to a wheelchair -- in performing common household or outdoor tasks as efficiently as possible. To achieve this, a successful helper must: (1) infer the human's intents and constraints by following the human and observing their behaviors (social perception), and (2) make a cooperative plan tailored to the human partner to solve the task as quickly as possible, working together as a team (cooperative planning). To benchmark this challenge, we create four new agents with real physical constraints and eight long-horizon tasks featuring both indoor and outdoor scenes with various constraints, emergency events, and potential risks. We benchmark planning- and learning-based baselines on the challenge and introduce a new method that leverages large language models and behavior modeling. Empirical evaluations demonstrate the effectiveness of our benchmark in enabling systematic assessment of key aspects of machine social intelligence. Our benchmark and code are publicly available at https://github.com/UMass-Foundation-Model/CHAIC.
HAZARD Challenge: Embodied Decision Making in Dynamically Changing Environments
Jan 23, 2024
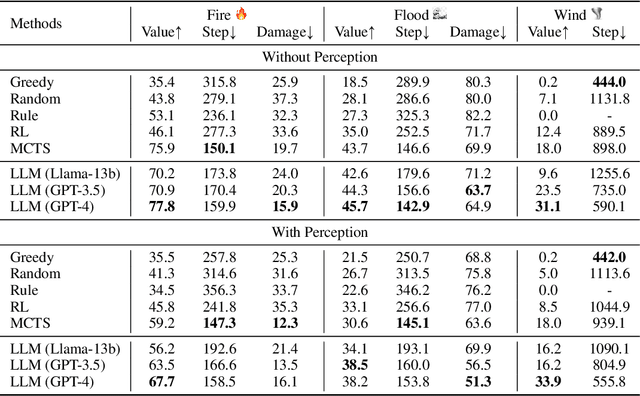

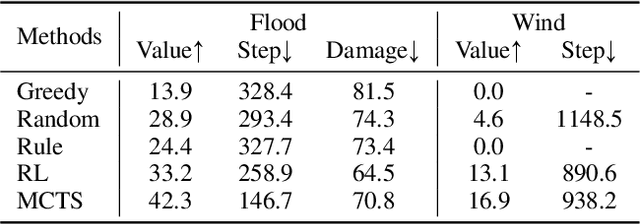
Recent advances in high-fidelity virtual environments serve as one of the major driving forces for building intelligent embodied agents to perceive, reason and interact with the physical world. Typically, these environments remain unchanged unless agents interact with them. However, in real-world scenarios, agents might also face dynamically changing environments characterized by unexpected events and need to rapidly take action accordingly. To remedy this gap, we propose a new simulated embodied benchmark, called HAZARD, specifically designed to assess the decision-making abilities of embodied agents in dynamic situations. HAZARD consists of three unexpected disaster scenarios, including fire, flood, and wind, and specifically supports the utilization of large language models (LLMs) to assist common sense reasoning and decision-making. This benchmark enables us to evaluate autonomous agents' decision-making capabilities across various pipelines, including reinforcement learning (RL), rule-based, and search-based methods in dynamically changing environments. As a first step toward addressing this challenge using large language models, we further develop an LLM-based agent and perform an in-depth analysis of its promise and challenge of solving these challenging tasks. HAZARD is available at https://vis-www.cs.umass.edu/hazard/.
T-Eval: Evaluating the Tool Utilization Capability of Large Language Models Step by Step
Jan 15, 2024



Large language models (LLM) have achieved remarkable performance on various NLP tasks and are augmented by tools for broader applications. Yet, how to evaluate and analyze the tool-utilization capability of LLMs is still under-explored. In contrast to previous works that evaluate models holistically, we comprehensively decompose the tool utilization into multiple sub-processes, including instruction following, planning, reasoning, retrieval, understanding, and review. Based on that, we further introduce T-Eval to evaluate the tool utilization capability step by step. T-Eval disentangles the tool utilization evaluation into several sub-domains along model capabilities, facilitating the inner understanding of both holistic and isolated competency of LLMs. We conduct extensive experiments on T-Eval and in-depth analysis of various LLMs. T-Eval not only exhibits consistency with the outcome-oriented evaluation but also provides a more fine-grained analysis of the capabilities of LLMs, providing a new perspective in LLM evaluation on tool-utilization ability. The benchmark will be available at https://github.com/open-compass/T-Eval.
Iteratively Learn Diverse Strategies with State Distance Information
Oct 23, 2023
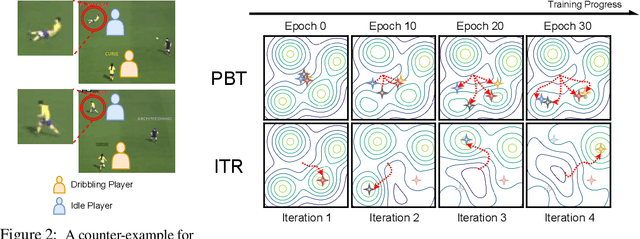
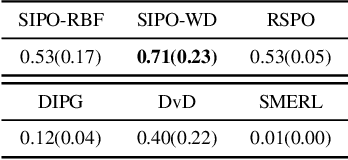
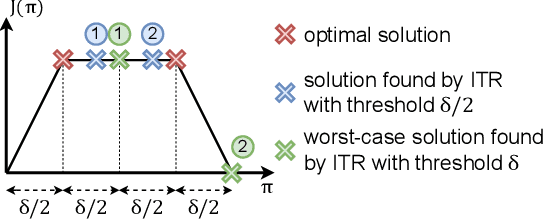
In complex reinforcement learning (RL) problems, policies with similar rewards may have substantially different behaviors. It remains a fundamental challenge to optimize rewards while also discovering as many diverse strategies as possible, which can be crucial in many practical applications. Our study examines two design choices for tackling this challenge, i.e., diversity measure and computation framework. First, we find that with existing diversity measures, visually indistinguishable policies can still yield high diversity scores. To accurately capture the behavioral difference, we propose to incorporate the state-space distance information into the diversity measure. In addition, we examine two common computation frameworks for this problem, i.e., population-based training (PBT) and iterative learning (ITR). We show that although PBT is the precise problem formulation, ITR can achieve comparable diversity scores with higher computation efficiency, leading to improved solution quality in practice. Based on our analysis, we further combine ITR with two tractable realizations of the state-distance-based diversity measures and develop a novel diversity-driven RL algorithm, State-based Intrinsic-reward Policy Optimization (SIPO), with provable convergence properties. We empirically examine SIPO across three domains from robot locomotion to multi-agent games. In all of our testing environments, SIPO consistently produces strategically diverse and human-interpretable policies that cannot be discovered by existing baselines.