 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Horizon Hybrid Internal Model for Low-Gravity Quadrupedal Jumping with Hardware-in-the-Loop Validation
Mar 09, 2026Locomotion under reduced gravity is commonly realized through jumping, yet continuous pronking in lunar gravity remains challenging due to prolonged flight phases and sparse ground contact. The extended aerial duration increases landing impact sensitivity and makes stable attitude regulation over rough planetary terrain difficult. Existing approaches primarily address single jumps on flat surfaces and lack both continuous-terrain solutions and realistic hardware validation. This work presents a Dual-Horizon Hybrid Internal Model for continuous quadrupedal jumping under lunar gravity using proprioceptive sensing only. Two temporal encoders capture complementary time scales: a short-horizon branch models rapid vertical dynamics with explicit vertical velocity estimation, while a long-horizon branch models horizontal motion trends and center-of-mass height evolution across the jump cycle. The fused representation enables stable and continuous jumping under extended aerial phases characteristic of lunar gravity. To provide hardware-in-the-loop validation, we develop the MATRIX (Mixed-reality Adaptive Testbed for Robotic Integrated eXploration) platform, a digital-twin-driven system that offloads gravity through a pulley-counterweight mechanism and maps Unreal Engine lunar terrain to a motion platform and treadmill in real time. Using MATRIX, we demonstrate continuous jumping of a quadruped robot under lunar-gravity emulation across cratered lunar-like terrain.
Overconfidence in LLM-as-a-Judge: Diagnosis and Confidence-Driven Solution
Aug 08, 2025Large Language Models (LLMs) are widely used as automated judges, where practical value depends on both accuracy and trustworthy, risk-aware judgments. Existing approaches predominantly focus on accuracy, overlooking the necessity of well-calibrated confidence, which is vital for adaptive and reliable evaluation pipelines. In this work, we advocate a shift from accuracy-centric evaluation to confidence-driven, risk-aware LLM-as-a-Judge systems, emphasizing the necessity of well-calibrated confidence for trustworthy and adaptive evaluation. We systematically identify the **Overconfidence Phenomenon** in current LLM-as-a-Judges, where predicted confidence significantly overstates actual correctness, undermining reliability in practical deployment. To quantify this phenomenon, we introduce **TH-Score**, a novel metric measuring confidence-accuracy alignment. Furthermore, we propose **LLM-as-a-Fuser**, an ensemble framework that transforms LLMs into reliable, risk-aware evaluators. Extensive experiments demonstrate that our approach substantially improves calibration and enables adaptive, confidence-driven evaluation pipelines, achieving superior reliability and accuracy compared to existing baselines.
Sok: Comprehensive Security Overview, Challenges, and Future Directions of Voice-Controlled Systems
May 27, 2024



The integration of Voice Control Systems (VCS) into smart devices and their growing presence in daily life accentuate the importance of their security. Current research has uncovered numerous vulnerabilities in VCS, presenting significant risks to user privacy and security. However, a cohesive and systematic examination of these vulnerabilities and the corresponding solutions is still absent. This lack of comprehensive analysis presents a challenge for VCS designers in fully understanding and mitigating the security issues within these systems. Addressing this gap, our study introduces a hierarchical model structure for VCS, providing a novel lens for categorizing and analyzing existing literature in a systematic manner. We classify attacks based on their technical principles and thoroughly evaluate various attributes, such as their methods, targets, vectors, and behaviors. Furthermore, we consolidate and assess the defense mechanisms proposed in current research, offering actionable recommendations for enhancing VCS security. Our work makes a significant contribution by simplifying the complexity inherent in VCS security, aiding designers in effectively identifying and countering potential threats, and setting a foundation for future advancements in VCS security research.
HAZARD Challenge: Embodied Decision Making in Dynamically Changing Environments
Jan 23, 2024
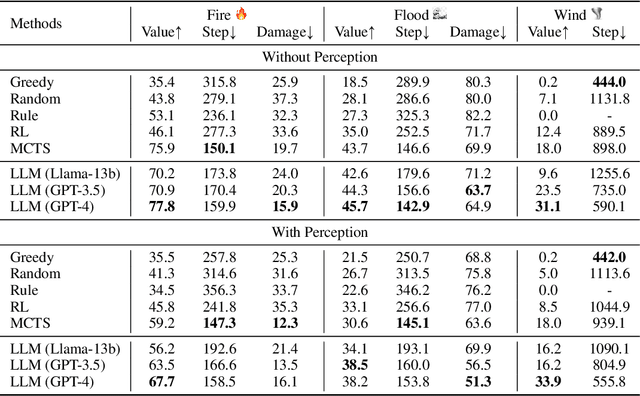

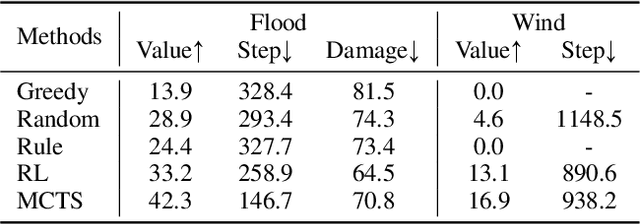
Recent advances in high-fidelity virtual environments serve as one of the major driving forces for building intelligent embodied agents to perceive, reason and interact with the physical world. Typically, these environments remain unchanged unless agents interact with them. However, in real-world scenarios, agents might also face dynamically changing environments characterized by unexpected events and need to rapidly take action accordingly. To remedy this gap, we propose a new simulated embodied benchmark, called HAZARD, specifically designed to assess the decision-making abilities of embodied agents in dynamic situations. HAZARD consists of three unexpected disaster scenarios, including fire, flood, and wind, and specifically supports the utilization of large language models (LLMs) to assist common sense reasoning and decision-making. This benchmark enables us to evaluate autonomous agents' decision-making capabilities across various pipelines, including reinforcement learning (RL), rule-based, and search-based methods in dynamically changing environments. As a first step toward addressing this challenge using large language models, we further develop an LLM-based agent and perform an in-depth analysis of its promise and challenge of solving these challenging tasks. HAZARD is available at https://vis-www.cs.umass.edu/hazard/.