 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Documents Are What You Need for Extracting Instruction Tuning Data
May 18, 2025Instruction tuning improves the performance of large language models (LLMs), but it heavily relies on high-quality training data. Recently, LLMs have been used to synthesize instruction data using seed question-answer (QA) pairs. However, these synthesized instructions often lack diversity and tend to be similar to the input seeds, limiting their applicability in real-world scenarios. To address this, we propose extracting instruction tuning data from web corpora that contain rich and diverse knowledge. A naive solution is to retrieve domain-specific documents and extract all QA pairs from them, but this faces two key challenges: (1) extracting all QA pairs using LLMs is prohibitively expensive, and (2) many extracted QA pairs may be irrelevant to the downstream tasks, potentially degrading model performance. To tackle these issues, we introduce EQUAL, an effective and scalable data extraction framework that iteratively alternates between document selection and high-quality QA pair extraction to enhance instruction tuning. EQUAL first clusters the document corpus based on embeddings derived from contrastive learning, then uses a multi-armed bandit strategy to efficiently identify clusters that are likely to contain valuable QA pairs. This iterative approach significantly reduces computational cost while boosting model performance. Experiments on AutoMathText and StackOverflow across four downstream tasks show that EQUAL reduces computational costs by 5-10x and improves accuracy by 2.5 percent on LLaMA-3.1-8B and Mistral-7B
Price of Stability in Quality-Aware Federated Learning
Oct 13, 2023Federated Learning (FL) is a distributed machine learning scheme that enables clients to train a shared global model without exchanging local data. The presence of label noise can severely degrade the FL performance, and some existing studies have focused on algorithm design for label denoising. However, they ignored the important issue that clients may not apply costly label denoising strategies due to them being self-interested and having heterogeneous valuations on the FL performance. To fill this gap, we model the clients' interactions as a novel label denoising game and characterize its equilibrium. We also analyze the price of stability, which quantifies the difference in the system performance (e.g., global model accuracy, social welfare) between the equilibrium outcome and the socially optimal solution. We prove that the equilibrium outcome always leads to a lower global model accuracy than the socially optimal solution does. We further design an efficient algorithm to compute the socially optimal solution. Numerical experiments on MNIST dataset show that the price of stability increases as the clients' data become noisier, calling for an effective incentive mechanism.
Interpretable Outlier Summarization
Mar 15, 2023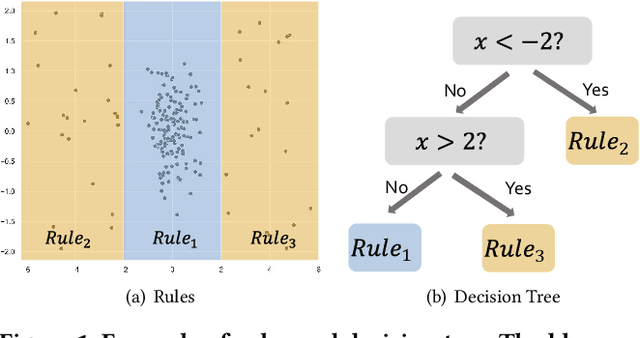
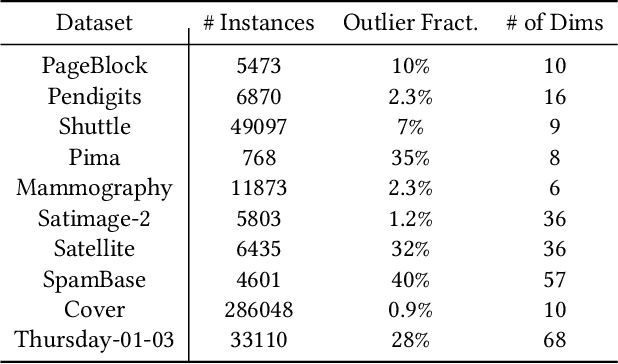
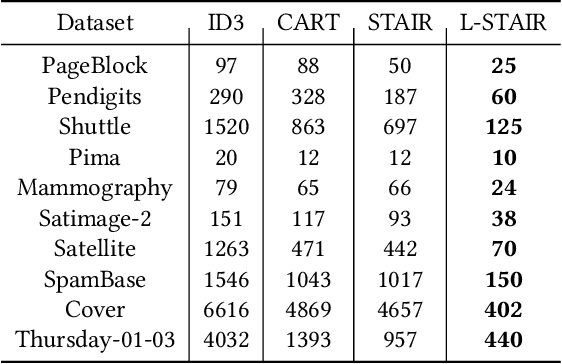
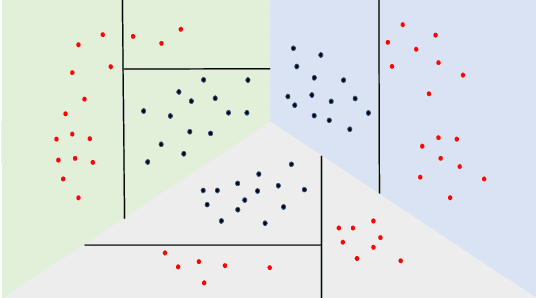
Outlier detection is critical in real applications to prevent financial fraud, defend network intrusions, or detecting imminent device failures. To reduce the human effort in evaluating outlier detection results and effectively turn the outliers into actionable insights, the users often expect a system to automatically produce interpretable summarizations of subgroups of outlier detection results. Unfortunately, to date no such systems exist. To fill this gap, we propose STAIR which learns a compact set of human understandable rules to summarize and explain the anomaly detection results. Rather than use the classical decision tree algorithms to produce these rules, STAIR proposes a new optimization objective to produce a small number of rules with least complexity, hence strong interpretability, to accurately summarize the detection results. The learning algorithm of STAIR produces a rule set by iteratively splitting the large rules and is optimal in maximizing this objective in each iteration. Moreover, to effectively handle high dimensional, highly complex data sets which are hard to summarize with simple rules, we propose a localized STAIR approach, called L-STAIR. Taking data locality into consideration, it simultaneously partitions data and learns a set of localized rules for each partition. Our experimental study on many outlier benchmark datasets shows that STAIR significantly reduces the complexity of the rules required to summarize the outlier detection results, thus more amenable for humans to understand and evaluate, compared to the decision tree methods.