 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-aware Speech Separation for Multi-talker Keyword Spotting
Jun 18, 2024



For noisy environments, ensuring the robustness of keyword spotting (KWS) systems is essential. While much research has focused on noisy KWS, less attention has been paid to multi-talker mixed speech scenarios. Unlike the usual cocktail party problem where multi-talker speech is separated using speaker clues, the key challenge here is to extract the target speech for KWS based on text clues. To address it, this paper proposes a novel Text-aware Permutation Determinization Training method for multi-talker KWS with a clue-based Speech Separation front-end (TPDT-SS). Our research highlights the critical role of SS front-ends and shows that incorporating keyword-specific clues into these models can greatly enhance the effectiveness. TPDT-SS shows remarkable success in addressing permutation problems in mixed keyword speech, thereby greatly boosting the performance of the backend. Additionally, fine-tuning our system on unseen mixed speech results in further performance improvement.
TDT-KWS: Fast And Accurate Keyword Spotting Using Token-and-duration Transducer
Mar 20, 2024



Designing an efficient keyword spotting (KWS) system that delivers exceptional performance on resource-constrained edge devices has long been a subject of significant attention. Existing KWS search algorithms typically follow a frame-synchronous approach, where search decisions are made repeatedly at each frame despite the fact that most frames are keyword-irrelevant. In this paper, we propose TDT-KWS, which leverages token-and-duration Transducers (TDT) for KWS tasks. We also propose a novel KWS task-specific decoding algorithm for Transducer-based models, which supports highly effective frame-asynchronous keyword search in streaming speech scenarios. With evaluations conducted on both the public Hey Snips and self-constructed LibriKWS-20 datasets, our proposed KWS-decoding algorithm produces more accurate results than conventional ASR decoding algorithms. Additionally, TDT-KWS achieves on-par or better wake word detection performance than both RNN-T and traditional TDT-ASR systems while achieving significant inference speed-up. Furthermore, experiments show that TDT-KWS is more robust to noisy environments compared to RNN-T KWS.
Contrastive Learning With Audio Discrimination For Customizable Keyword Spotting In Continuous Speech
Jan 12, 2024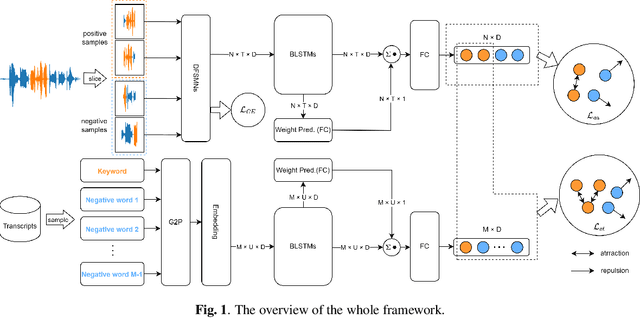
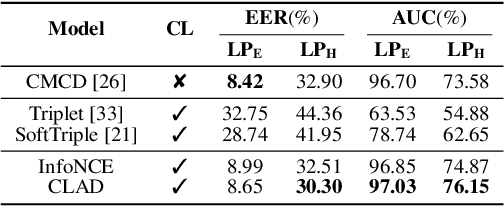
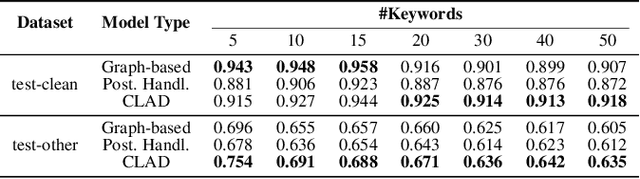
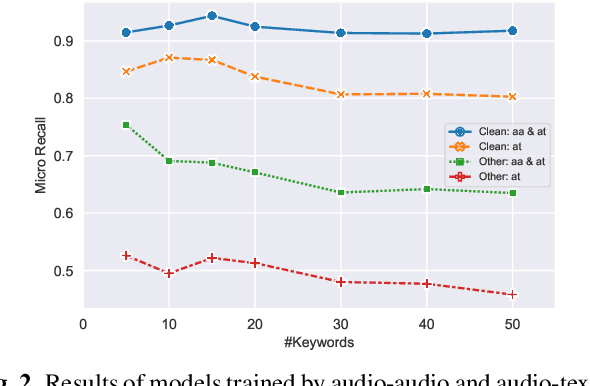
Customizable keyword spotting (KWS) in continuous speech has attracted increasing attention due to its real-world application potential. While contrastive learning (CL) has been widely used to extract keyword representations, previous CL approaches all operate on pre-segmented isolated words and employ only audio-text representations matching strategy. However, for KWS in continuous speech, co-articulation and streaming word segmentation can easily yield similar audio patterns for different texts, which may consequently trigger false alarms. To address this issue, we propose a novel CL with Audio Discrimination (CLAD) approach to learning keyword representation with both audio-text matching and audio-audio discrimination ability. Here, an InfoNCE loss considering both audio-audio and audio-text CL data pairs is employed for each sliding window during training. Evaluations on the open-source LibriPhrase dataset show that the use of sliding-window level InfoNCE loss yields comparable performance compared to previous CL approaches. Furthermore, experiments on the continuous speech dataset LibriSpeech demonstrate that, by incorporating audio discrimination, CLAD achieves significant performance gain over CL without audio discrimination. Meanwhile, compared to two-stage KWS approaches, the end-to-end KWS with CLAD achieves not only better performance, but also significant speed-up.