 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large-Scale Evaluation of Speech Foundation Models
Apr 15, 2024The foundation model paradigm leverages a shared foundation model to achieve state-of-the-art (SOTA) performance for various tasks, requiring minimal downstream-specific modeling and data annotation. This approach has proven crucial in the field of Natural Language Processing (NLP). However, the speech processing community lacks a similar setup to explore the paradigm systematically. In this work, we establish the Speech processing Universal PERformance Benchmark (SUPERB) to study the effectiveness of the paradigm for speech. We propose a unified multi-tasking framework to address speech processing tasks in SUPERB using a frozen foundation model followed by task-specialized, lightweight prediction heads. Combining our results with community submissions, we verify that the foundation model paradigm is promising for speech, and our multi-tasking framework is simple yet effective, as the best-performing foundation model shows competitive generalizability across most SUPERB tasks. For reproducibility and extensibility, we have developed a long-term maintained platform that enables deterministic benchmarking, allows for result sharing via an online leaderboard, and promotes collaboration through a community-driven benchmark database to support new development cycles. Finally, we conduct a series of analyses to offer an in-depth understanding of SUPERB and speech foundation models, including information flows across tasks inside the models, the correctness of the weighted-sum benchmarking protocol and the statistical significance and robustness of the benchmark.
Improving Frame-level Classifier for Word Timings with Non-peaky CTC in End-to-End Automatic Speech Recognition
Jun 09, 2023



End-to-end (E2E) systems have shown comparable performance to hybrid systems for automatic speech recognition (ASR). Word timings, as a by-product of ASR, are essential in many applications, especially for subtitling and computer-aided pronunciation training. In this paper, we improve the frame-level classifier for word timings in E2E system by introducing label priors in connectionist temporal classification (CTC) loss, which is adopted from prior works, and combining low-level Mel-scale filter banks with high-level ASR encoder output as input feature. On the internal Chinese corpus, the proposed method achieves 95.68%/94.18% compared to the hybrid system 93.0%/90.22% on the word timing accuracy metrics. It also surpass a previous E2E approach with an absolute increase of 4.80%/8.02% on the metrics on 7 languages. In addition, we further improve word timing accuracy by delaying CTC peaks with frame-wise knowledge distillation, though only experimenting on LibriSpeech.
SUPERB: Speech processing Universal PERformance Benchmark
May 03, 2021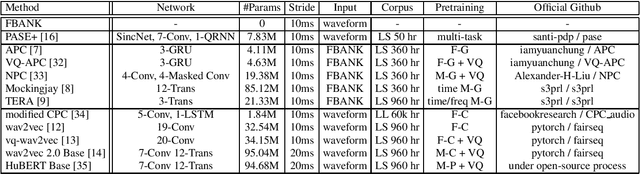
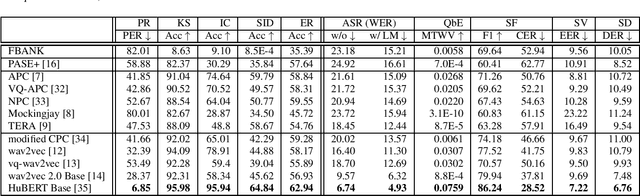
Self-supervised learning (SSL) has proven vital for advancing research in natural language processing (NLP) and computer vision (CV). The paradigm pretrains a shared model on large volumes of unlabeled data and achieves state-of-the-art (SOTA) for various tasks with minimal adaptation. However, the speech processing community lacks a similar setup to systematically explore the paradigm. To bridge this gap, we introduce Speech processing Universal PERformance Benchmark (SUPERB). SUPERB is a leaderboard to benchmark the performance of a shared model across a wide range of speech processing tasks with minimal architecture changes and labeled data. Among multiple usages of the shared model, we especially focus on extracting the representation learned from SSL due to its preferable re-usability. We present a simple framework to solve SUPERB tasks by learning task-specialized lightweight prediction heads on top of the frozen shared model. Our results demonstrate that the framework is promising as SSL representations show competitive generalizability and accessibility across SUPERB tasks. We release SUPERB as a challenge with a leaderboard and a benchmark toolkit to fuel the research in representation learning and general speech processing.
Utilizing Self-supervised Representations for MOS Prediction
Apr 21, 2021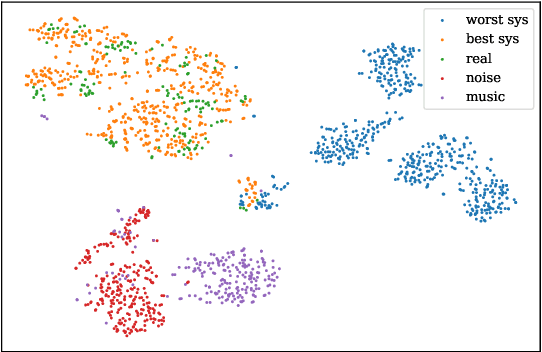
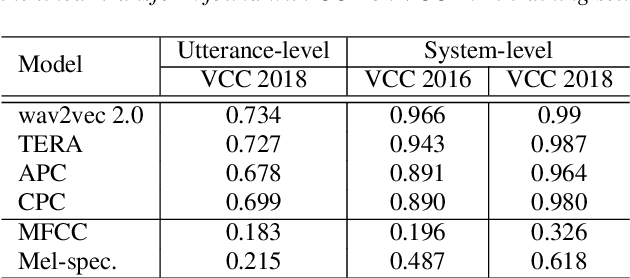
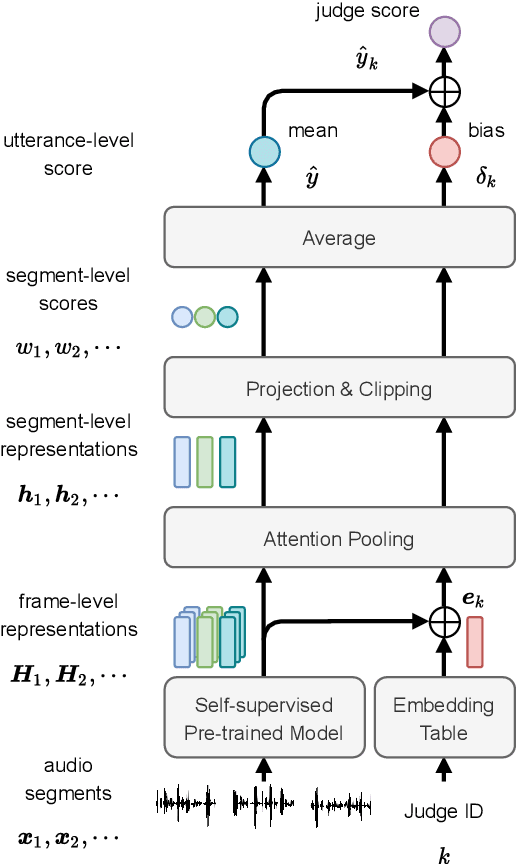
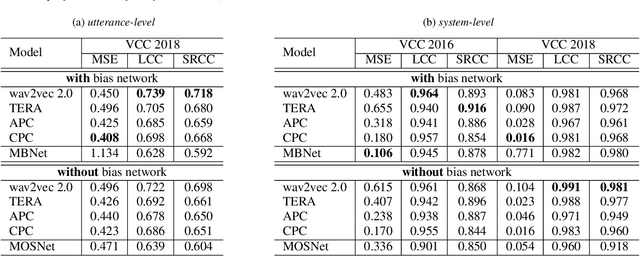
Speech quality assessment has been a critical issue in speech processing for decades. Existing automatic evaluations usually require clean references or parallel ground truth data, which is infeasible when the amount of data soars. Subjective tests, on the other hand, do not need any additional clean or parallel data and correlates better to human perception. However, such a test is expensive and time-consuming because crowd work is necessary. It thus becomes highly desired to develop an automatic evaluation approach that correlates well with human perception while not requiring ground truth data. In this paper, we use self-supervised pre-trained models for MOS prediction. We show their representations can distinguish between clean and noisy audios. Then, we fine-tune these pre-trained models followed by simple linear layers in an end-to-end manner. The experiment results showed that our framework outperforms the two previous state-of-the-art models by a significant improvement on Voice Conversion Challenge 2018 and achieves comparable or superior performance on Voice Conversion Challenge 2016. We also conducted an ablation study to further investigate how each module benefits the task. The experiment results are implemented and reproducible with publicly available toolkits.
S2VC: A Framework for Any-to-Any Voice Conversion with Self-Supervised Pretrained Representations
Apr 07, 2021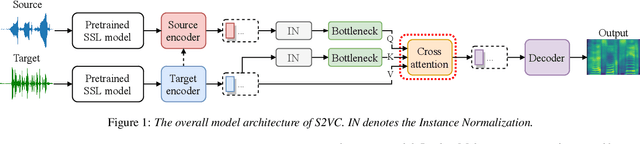
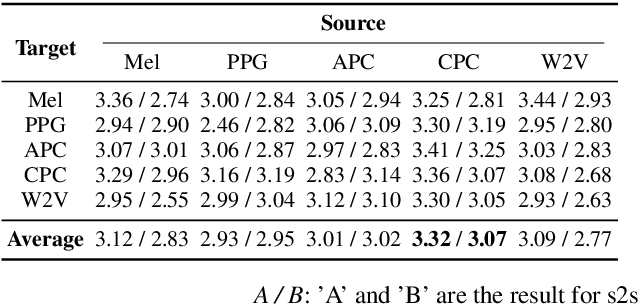
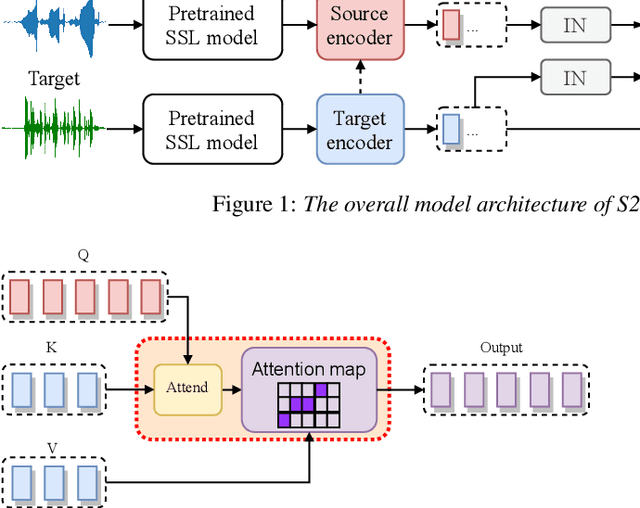

Any-to-any voice conversion (VC) aims to convert the timbre of utterances from and to any speakers seen or unseen during training. Various any-to-any VC approaches have been proposed like AUTOVC, AdaINVC, and FragmentVC. AUTOVC, and AdaINVC utilize source and target encoders to disentangle the content and speaker information of the features. FragmentVC utilizes two encoders to encode source and target information and adopts cross attention to align the source and target features with similar phonetic content. Moreover, pre-trained features are adopted. AUTOVC used dvector to extract speaker information, and self-supervised learning (SSL) features like wav2vec 2.0 is used in FragmentVC to extract the phonetic content information. Different from previous works, we proposed S2VC that utilizes Self-Supervised features as both source and target features for VC model. Supervised phoneme posteriororgram (PPG), which is believed to be speaker-independent and widely used in VC to extract content information, is chosen as a strong baseline for SSL features. The objective evaluation and subjective evaluation both show models taking SSL feature CPC as both source and target features outperforms that taking PPG as source feature, suggesting that SSL features have great potential in improving VC.
FragmentVC: Any-to-Any Voice Conversion by End-to-End Extracting and Fusing Fine-Grained Voice Fragments With Attention
Oct 27, 2020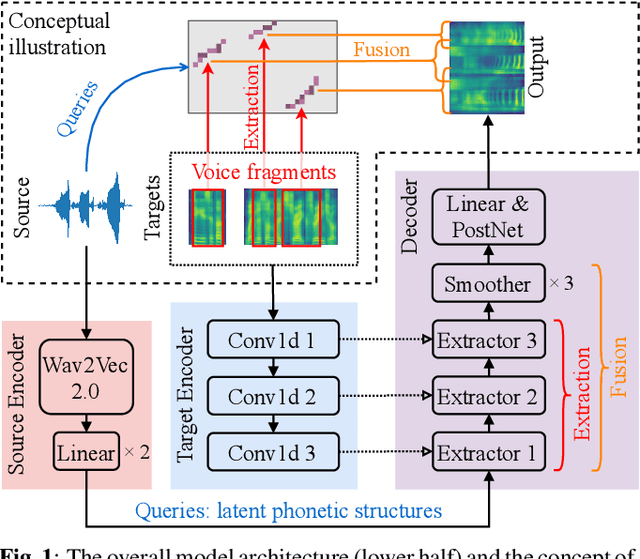



Any-to-any voice conversion aims to convert the voice from and to any speakers even unseen during training, which is much more challenging compared to one-to-one or many-to-many tasks, but much more attractive in real-world scenarios. In this paper we proposed FragmentVC, in which the latent phonetic structure of the utterance from the source speaker is obtained from Wav2Vec 2.0, while the spectral features of the utterance(s) from the target speaker are obtained from log mel-spectrograms. By aligning the hidden structures of the two different feature spaces with a two-stage training process, FragmentVC is able to extract fine-grained voice fragments from the target speaker utterance(s) and fuse them into the desired utterance, all based on the attention mechanism of Transformer as verified with analysis on attention maps, and is accomplished end-to-end. This approach is trained with reconstruction loss only without any disentanglement considerations between content and speaker information and doesn't require parallel data. Objective evaluation based on speaker verification and subjective evaluation with MOS both showed that this approach outperformed SOTA approaches, such as AdaIN-VC and AutoVC.
Defending Your Voice: Adversarial Attack on Voice Conversion
May 18, 2020


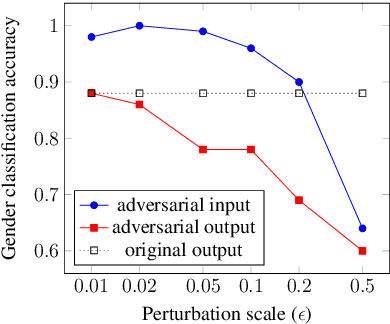
Substantial improvements have been achieved in recent years in voice conversion, which converts the speaker characteristics of an utterance into those of another speaker without changing the linguistic content of the utterance. Nonetheless, the improved conversion technologies also led to concerns about privacy and authentication. It thus becomes highly desired to be able to prevent one's voice from being improperly utilized with such voice conversion technologies. This is why we report in this paper the first known attempt to try to perform adversarial attack on voice conversion. We introduce human imperceptible noise into the utterances of a speaker whose voice is to be defended. Given these adversarial examples, voice conversion models cannot convert other utterances so as to sound like being produced by the defended speaker. Preliminary experiments were conducted on two currently state-of-the-art zero-shot voice conversion models. Objective and subjective evaluation results in both white-box and black-box scenarios are reported. It was shown that the speaker characteristics of the converted utterances were made obviously different from those of the defended speaker, while the adversarial examples of the defended speaker are not distinguishable from the authentic utterances.