 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDDOS: A MOS Prediction Framework utilizing Domain Adaptive Pre-training and Distribution of Opinion Scores
Apr 07, 2022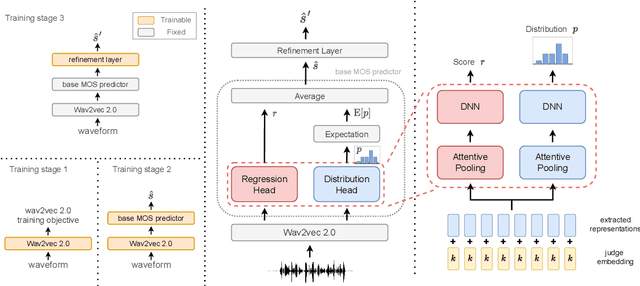
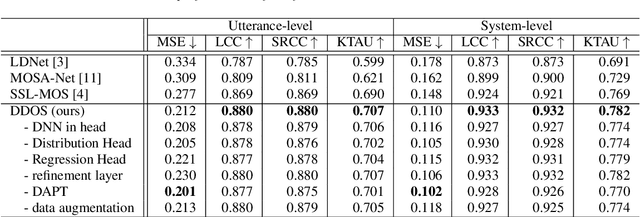
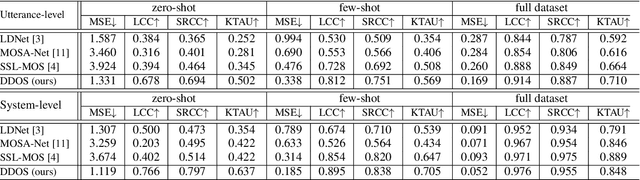
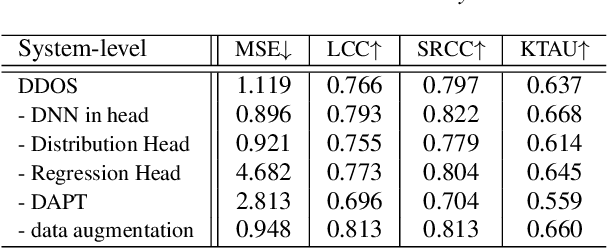
Mean opinion score (MOS) is a typical subjective evaluation metric for speech synthesis systems. Since collecting MOS is time-consuming, it would be desirable if there are accurate MOS prediction models for automatic evaluation. In this work, we propose DDOS, a novel MOS prediction model. DDOS utilizes domain adaptive pre-training to further pre-train self-supervised learning models on synthetic speech. And a proposed module is added to model the opinion score distribution of each utterance. With the proposed components, DDOS outperforms previous works on BVCC dataset. And the zero shot transfer result on BC2019 dataset is significantly improved. DDOS also wins second place in Interspeech 2022 VoiceMOS challenge in terms of system-level score.
On the Efficiency of Integrating Self-supervised Learning and Meta-learning for User-defined Few-shot Keyword Spotting
Apr 01, 2022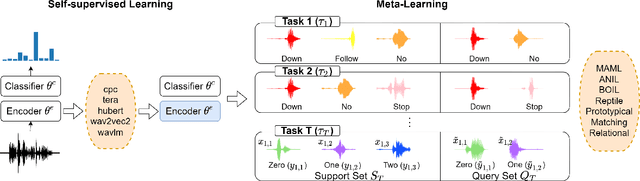
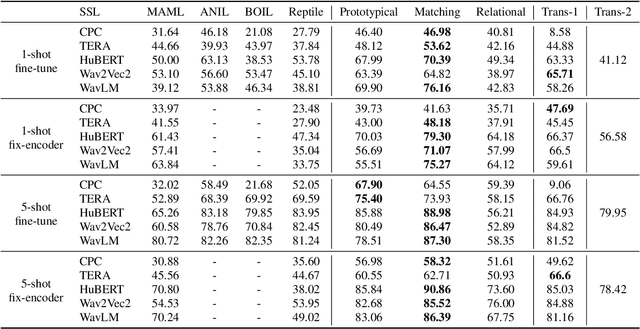
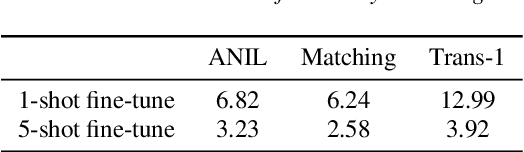
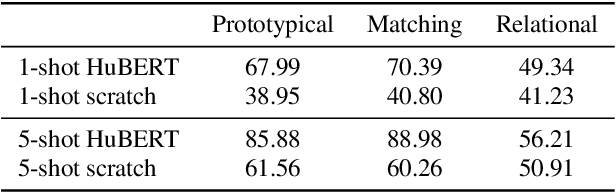
User-defined keyword spotting is a task to detect new spoken terms defined by users. This can be viewed as a few-shot learning problem since it is unreasonable for users to define their desired keywords by providing many examples. To solve this problem, previous works try to incorporate self-supervised learning models or apply meta-learning algorithms. But it is unclear whether self-supervised learning and meta-learning are complementary and which combination of the two types of approaches is most effective for few-shot keyword discovery. In this work, we systematically study these questions by utilizing various self-supervised learning models and combining them with a wide variety of meta-learning algorithms. Our result shows that HuBERT combined with Matching network achieves the best result and is robust to the changes of few-shot examples.
Membership Inference Attacks Against Self-supervised Speech Models
Nov 09, 2021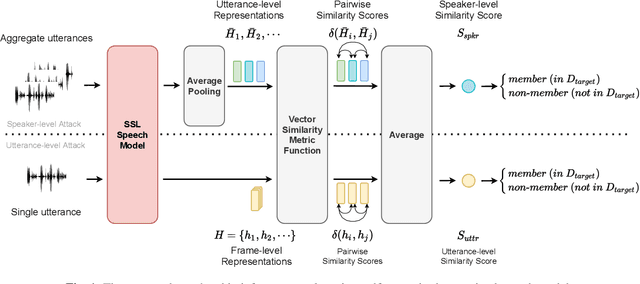

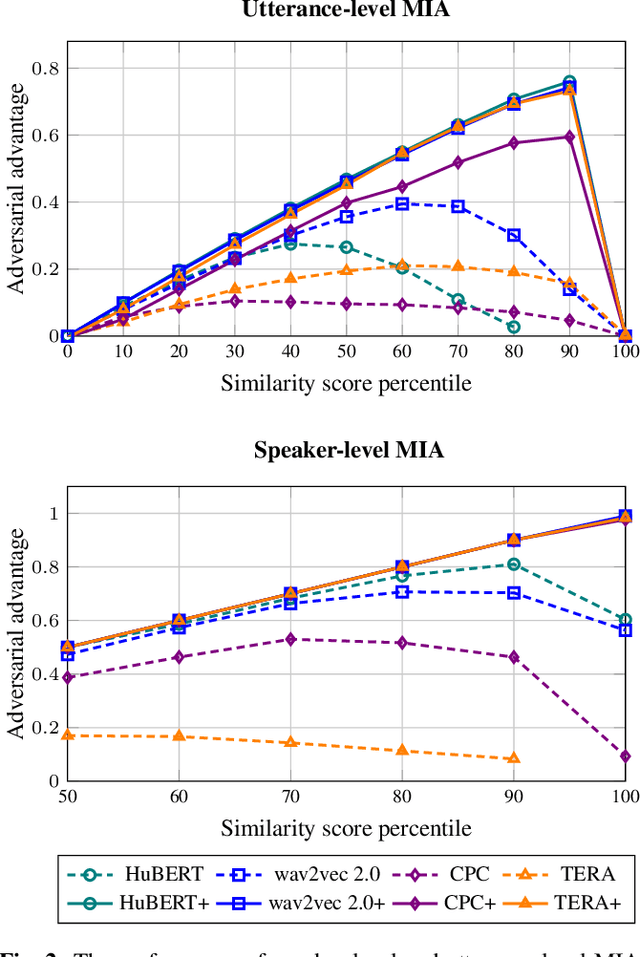
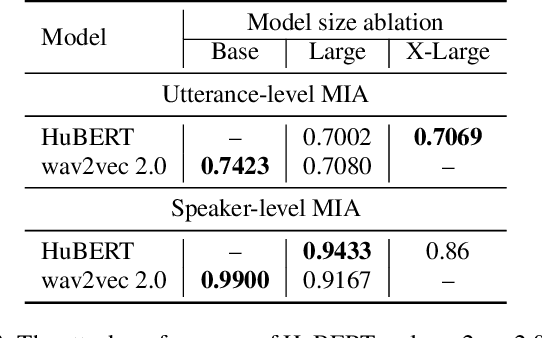
Recently, adapting the idea of self-supervised learning (SSL) on continuous speech has started gaining attention. SSL models pre-trained on a huge amount of unlabeled audio can generate general-purpose representations that benefit a wide variety of speech processing tasks. Despite their ubiquitous deployment, however, the potential privacy risks of these models have not been well investigated. In this paper, we present the first privacy analysis on several SSL speech models using Membership Inference Attacks (MIA) under black-box access. The experiment results show that these pre-trained models are vulnerable to MIA and prone to membership information leakage with high adversarial advantage scores in both utterance-level and speaker-level. Furthermore, we also conduct several ablation studies to understand the factors that contribute to the success of MIA.
Utilizing Self-supervised Representations for MOS Prediction
Apr 21, 2021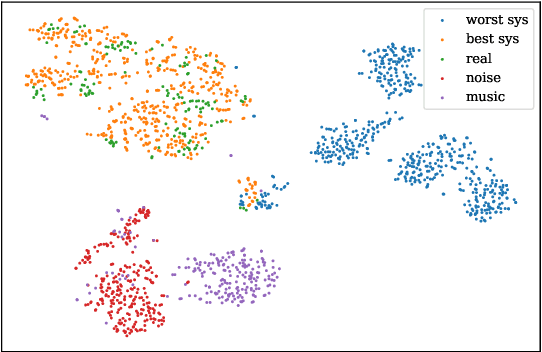
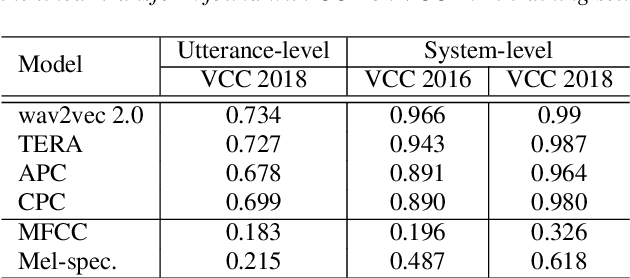
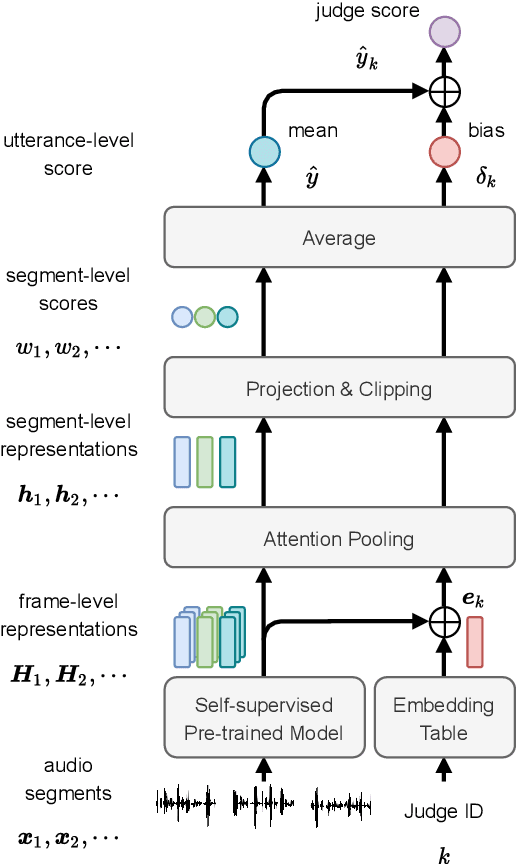
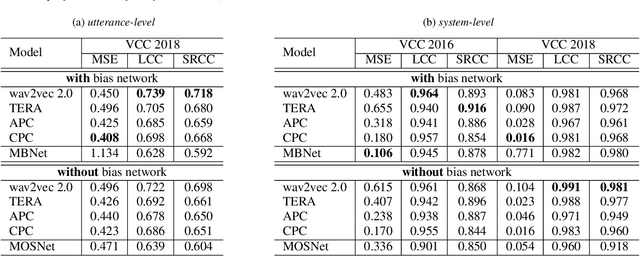
Speech quality assessment has been a critical issue in speech processing for decades. Existing automatic evaluations usually require clean references or parallel ground truth data, which is infeasible when the amount of data soars. Subjective tests, on the other hand, do not need any additional clean or parallel data and correlates better to human perception. However, such a test is expensive and time-consuming because crowd work is necessary. It thus becomes highly desired to develop an automatic evaluation approach that correlates well with human perception while not requiring ground truth data. In this paper, we use self-supervised pre-trained models for MOS prediction. We show their representations can distinguish between clean and noisy audios. Then, we fine-tune these pre-trained models followed by simple linear layers in an end-to-end manner. The experiment results showed that our framework outperforms the two previous state-of-the-art models by a significant improvement on Voice Conversion Challenge 2018 and achieves comparable or superior performance on Voice Conversion Challenge 2016. We also conducted an ablation study to further investigate how each module benefits the task. The experiment results are implemented and reproducible with publicly available toolkits.
Is BERT a Cross-Disciplinary Knowledge Learner? A Surprising Finding of Pre-trained Models' Transferability
Mar 12, 2021
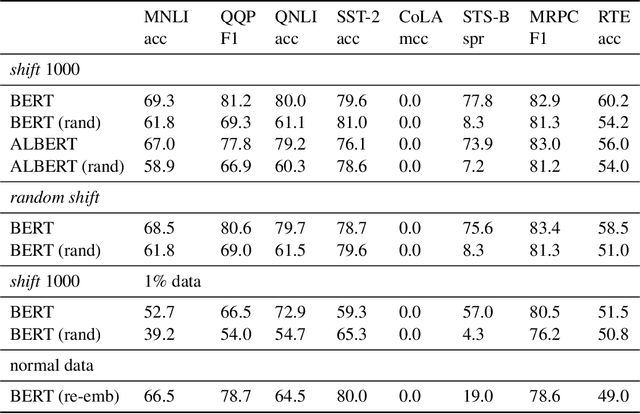
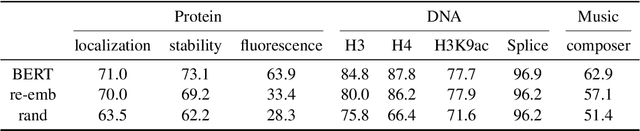
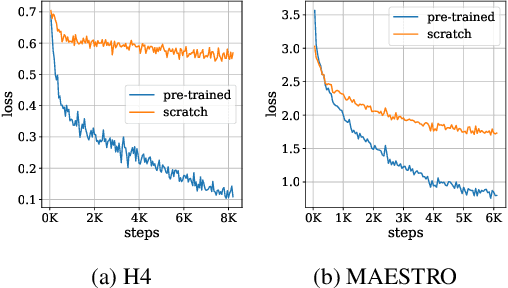
In this paper, we investigate whether the power of the models pre-trained on text data, such as BERT, can be transferred to general token sequence classification applications. To verify pre-trained models' transferability, we test the pre-trained models on (1) text classification tasks with meanings of tokens mismatches, and (2) real-world non-text token sequence classification data, including amino acid sequence, DNA sequence, and music. We find that even on non-text data, the models pre-trained on text converge faster than the randomly initialized models, and the testing performance of the pre-trained models is merely slightly worse than the models designed for the specific tasks.
Further Boosting BERT-based Models by Duplicating Existing Layers: Some Intriguing Phenomena inside BERT
Jan 25, 2020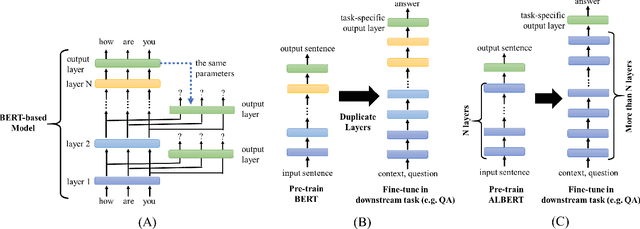
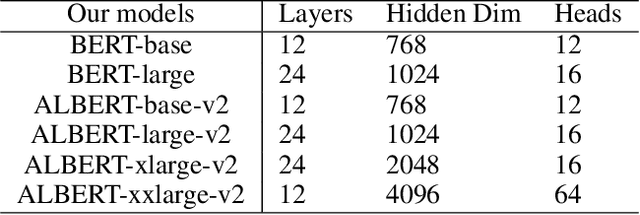


Although Bidirectional Encoder Representations from Transformers (BERT) have achieved tremendous success in many natural language processing (NLP) tasks, it remains a black box, so much previous work has tried to lift the veil of BERT and understand the functionality of each layer. In this paper, we found that removing or duplicating most layers in BERT would not change their outputs. This fact remains true across a wide variety of BERT-based models. Based on this observation, we propose a quite simple method to boost the performance of BERT. By duplicating some layers in the BERT-based models to make it deeper (no extra training required in this step), they obtain better performance in the down-stream tasks after fine-tuning.