 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Lightweight Text-to-Speech: Voice Cloning with Adaptive Structured Pruning
Mar 21, 2023Personalized TTS is an exciting and highly desired application that allows users to train their TTS voice using only a few recordings. However, TTS training typically requires many hours of recording and a large model, making it unsuitable for deployment on mobile devices. To overcome this limitation, related works typically require fine-tuning a pre-trained TTS model to preserve its ability to generate high-quality audio samples while adapting to the target speaker's voice. This process is commonly referred to as ``voice cloning.'' Although related works have achieved significant success in changing the TTS model's voice, they are still required to fine-tune from a large pre-trained model, resulting in a significant size for the voice-cloned model. In this paper, we propose applying trainable structured pruning to voice cloning. By training the structured pruning masks with voice-cloning data, we can produce a unique pruned model for each target speaker. Our experiments demonstrate that using learnable structured pruning, we can compress the model size to 7 times smaller while achieving comparable voice-cloning performance.
On the Efficiency of Integrating Self-supervised Learning and Meta-learning for User-defined Few-shot Keyword Spotting
Apr 01, 2022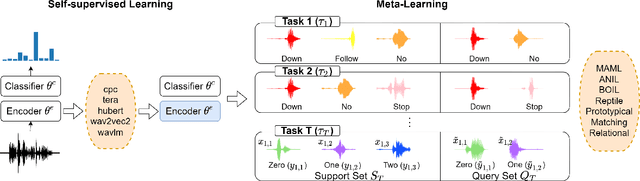
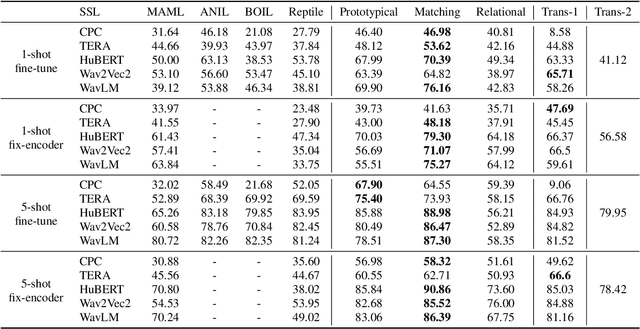
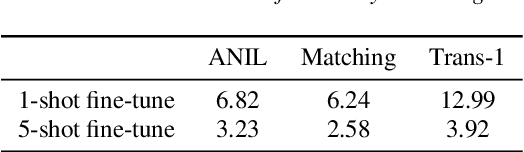
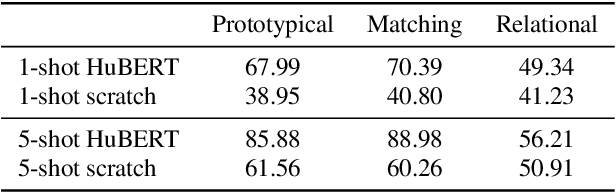
User-defined keyword spotting is a task to detect new spoken terms defined by users. This can be viewed as a few-shot learning problem since it is unreasonable for users to define their desired keywords by providing many examples. To solve this problem, previous works try to incorporate self-supervised learning models or apply meta-learning algorithms. But it is unclear whether self-supervised learning and meta-learning are complementary and which combination of the two types of approaches is most effective for few-shot keyword discovery. In this work, we systematically study these questions by utilizing various self-supervised learning models and combining them with a wide variety of meta-learning algorithms. Our result shows that HuBERT combined with Matching network achieves the best result and is robust to the changes of few-shot examples.