 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large-Scale Evaluation of Speech Foundation Models
Apr 15, 2024The foundation model paradigm leverages a shared foundation model to achieve state-of-the-art (SOTA) performance for various tasks, requiring minimal downstream-specific modeling and data annotation. This approach has proven crucial in the field of Natural Language Processing (NLP). However, the speech processing community lacks a similar setup to explore the paradigm systematically. In this work, we establish the Speech processing Universal PERformance Benchmark (SUPERB) to study the effectiveness of the paradigm for speech. We propose a unified multi-tasking framework to address speech processing tasks in SUPERB using a frozen foundation model followed by task-specialized, lightweight prediction heads. Combining our results with community submissions, we verify that the foundation model paradigm is promising for speech, and our multi-tasking framework is simple yet effective, as the best-performing foundation model shows competitive generalizability across most SUPERB tasks. For reproducibility and extensibility, we have developed a long-term maintained platform that enables deterministic benchmarking, allows for result sharing via an online leaderboard, and promotes collaboration through a community-driven benchmark database to support new development cycles. Finally, we conduct a series of analyses to offer an in-depth understanding of SUPERB and speech foundation models, including information flows across tasks inside the models, the correctness of the weighted-sum benchmarking protocol and the statistical significance and robustness of the benchmark.
Leveraging Sequence Embedding and Convolutional Neural Network for Protein Function Prediction
Dec 01, 2021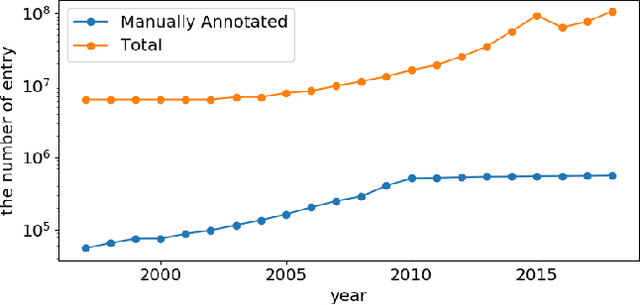
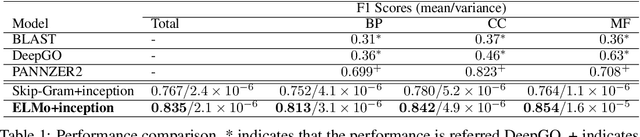
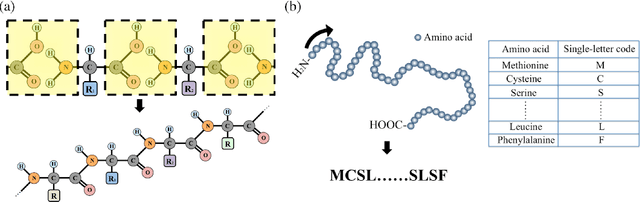
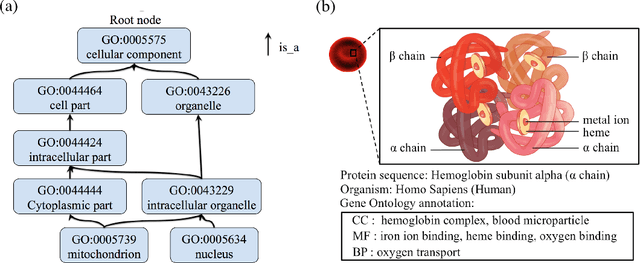
The capability of accurate prediction of protein functions and properties is essential in the biotechnology industry, e.g. drug development and artificial protein synthesis, etc. The main challenges of protein function prediction are the large label space and the lack of labeled training data. Our method leverages unsupervised sequence embedding and the success of deep convolutional neural network to overcome these challenges. In contrast, most of the existing methods delete the rare protein functions to reduce the label space. Furthermore, some existing methods require additional bio-information (e.g., the 3-dimensional structure of the proteins) which is difficult to be determined in biochemical experiments. Our proposed method significantly outperforms the other methods on the publicly available benchmark using only protein sequences as input. This allows the process of identifying protein functions to be sped up.
SpeechNet: A Universal Modularized Model for Speech Processing Tasks
May 31, 2021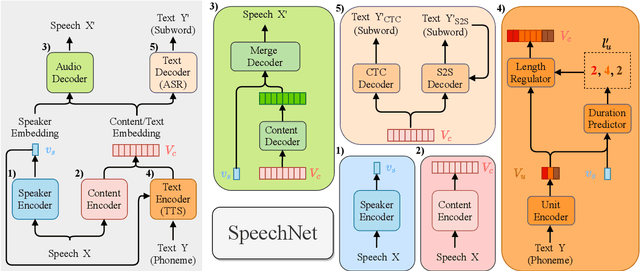
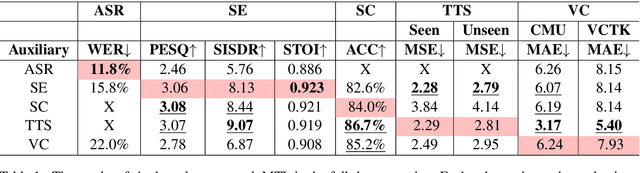
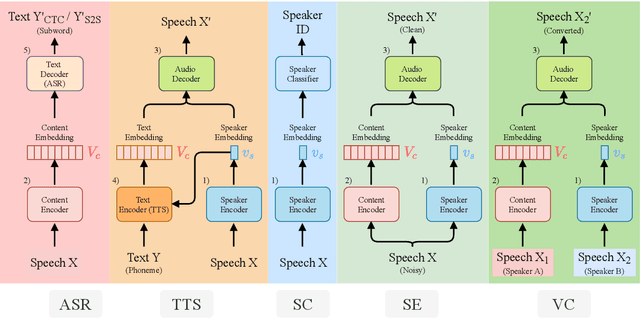
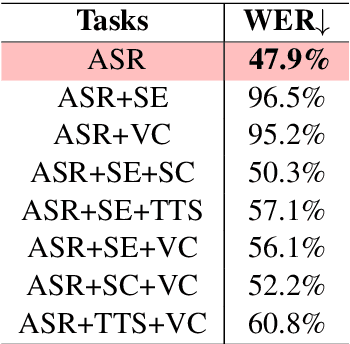
There is a wide variety of speech processing tasks ranging from extracting content information from speech signals to generating speech signals. For different tasks, model networks are usually designed and tuned separately. If a universal model can perform multiple speech processing tasks, some tasks might be improved with the related abilities learned from other tasks. The multi-task learning of a wide variety of speech processing tasks with a universal model has not been studied. This paper proposes a universal modularized model, SpeechNet, which treats all speech processing tasks into a speech/text input and speech/text output format. We select five essential speech processing tasks for multi-task learning experiments with SpeechNet. We show that SpeechNet learns all of the above tasks, and we further analyze which tasks can be improved by other tasks. SpeechNet is modularized and flexible for incorporating more modules, tasks, or training approaches in the future. We release the code and experimental settings to facilitate the research of modularized universal models and multi-task learning of speech processing tasks.
SUPERB: Speech processing Universal PERformance Benchmark
May 03, 2021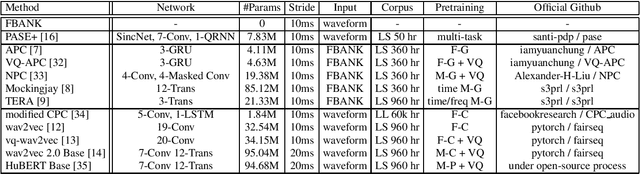
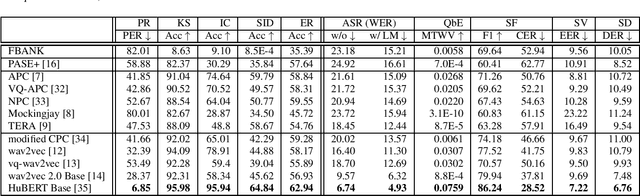
Self-supervised learning (SSL) has proven vital for advancing research in natural language processing (NLP) and computer vision (CV). The paradigm pretrains a shared model on large volumes of unlabeled data and achieves state-of-the-art (SOTA) for various tasks with minimal adaptation. However, the speech processing community lacks a similar setup to systematically explore the paradigm. To bridge this gap, we introduce Speech processing Universal PERformance Benchmark (SUPERB). SUPERB is a leaderboard to benchmark the performance of a shared model across a wide range of speech processing tasks with minimal architecture changes and labeled data. Among multiple usages of the shared model, we especially focus on extracting the representation learned from SSL due to its preferable re-usability. We present a simple framework to solve SUPERB tasks by learning task-specialized lightweight prediction heads on top of the frozen shared model. Our results demonstrate that the framework is promising as SSL representations show competitive generalizability and accessibility across SUPERB tasks. We release SUPERB as a challenge with a leaderboard and a benchmark toolkit to fuel the research in representation learning and general speech processing.
Hand-crafted Attention is All You Need? A Study of Attention on Self-supervised Audio Transformer
Jun 09, 2020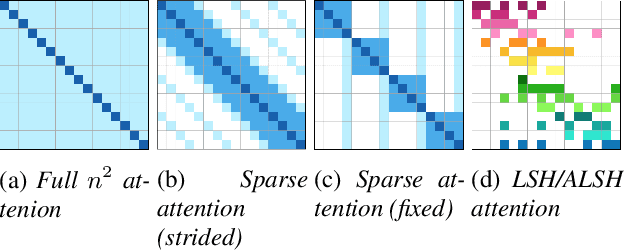


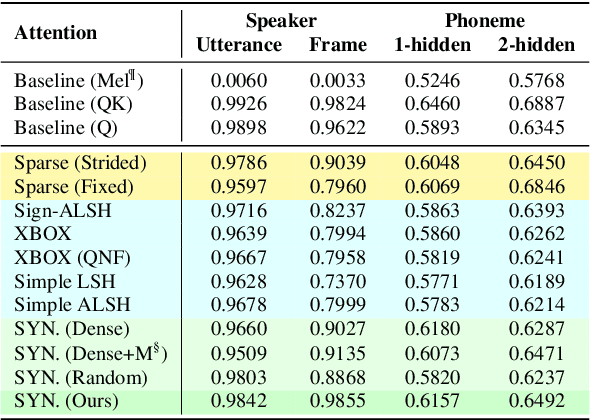
In this paper, we seek to reduce the computation complexity of transformer-based models for speech representation learning. We evaluate 10 attention mechanisms; then, we pre-train the transformer-based model with those attentions in a self-supervised fashion and use them as feature extractors on downstream tasks, including phoneme classification and speaker classification. We find that the proposed approach, which only uses hand-crafted and learnable attentions, is comparable with the full self-attention.
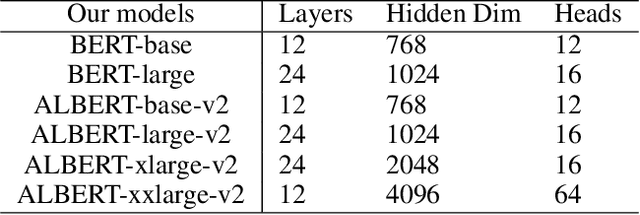
Audio ALBERT: A Lite BERT for Self-supervised Learning of Audio Representation
May 26, 2020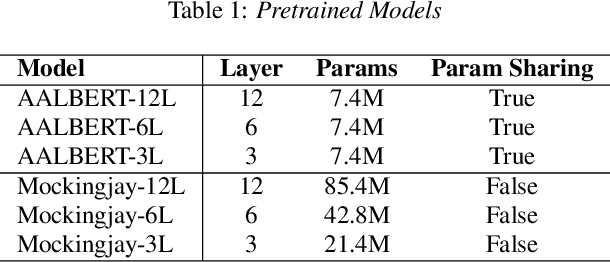
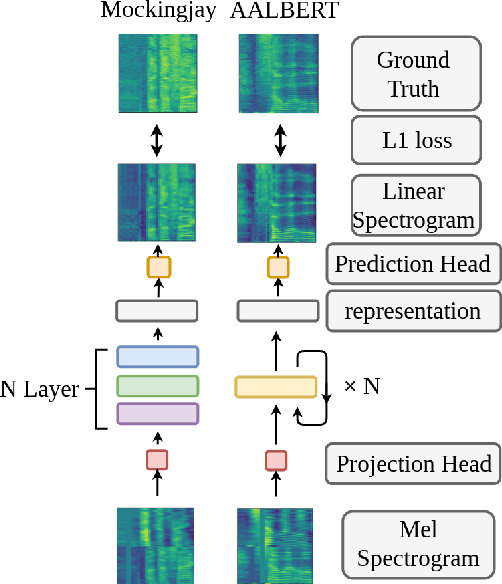
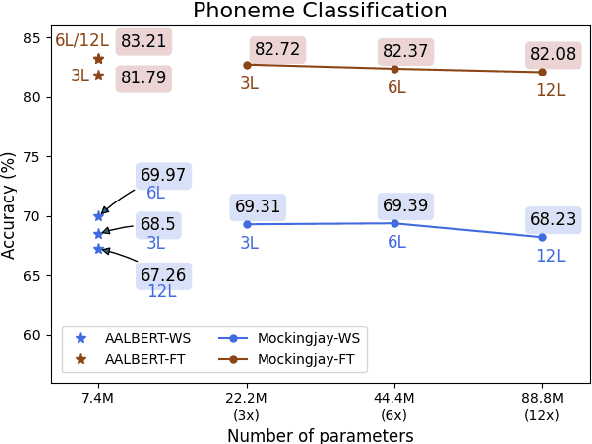
For self-supervised speech processing, it is crucial to use pretrained models as speech representation extractors. In recent works, increasing the size of the model has been utilized in acoustic model training in order to achieve better performance. In this paper, we propose Audio ALBERT, a lite version of the self-supervised speech representation model. We use the representations with two downstream tasks, speaker identification, and phoneme classification. We show that Audio ALBERT is capable of achieving competitive performance with those huge models in the downstream tasks while utilizing 91\% fewer parameters. Moreover, we use some simple probing models to measure how much the information of the speaker and phoneme is encoded in latent representations. In probing experiments, we find that the latent representations encode richer information of both phoneme and speaker than that of the last layer.
Further Boosting BERT-based Models by Duplicating Existing Layers: Some Intriguing Phenomena inside BERT
Jan 25, 2020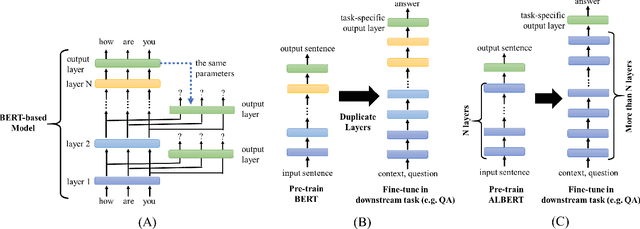


Although Bidirectional Encoder Representations from Transformers (BERT) have achieved tremendous success in many natural language processing (NLP) tasks, it remains a black box, so much previous work has tried to lift the veil of BERT and understand the functionality of each layer. In this paper, we found that removing or duplicating most layers in BERT would not change their outputs. This fact remains true across a wide variety of BERT-based models. Based on this observation, we propose a quite simple method to boost the performance of BERT. By duplicating some layers in the BERT-based models to make it deeper (no extra training required in this step), they obtain better performance in the down-stream tasks after fine-tuning.
Mockingjay: Unsupervised Speech Representation Learning with Deep Bidirectional Transformer Encoders
Oct 25, 2019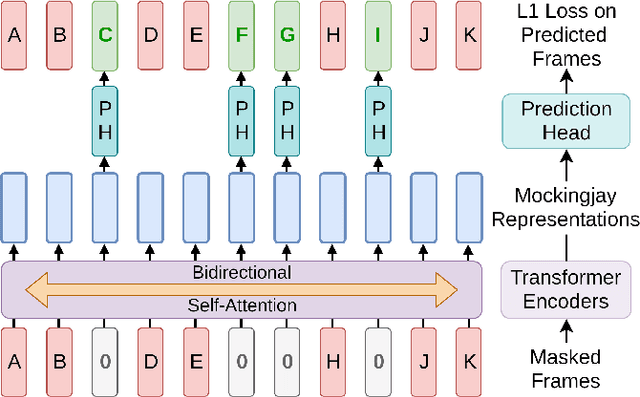

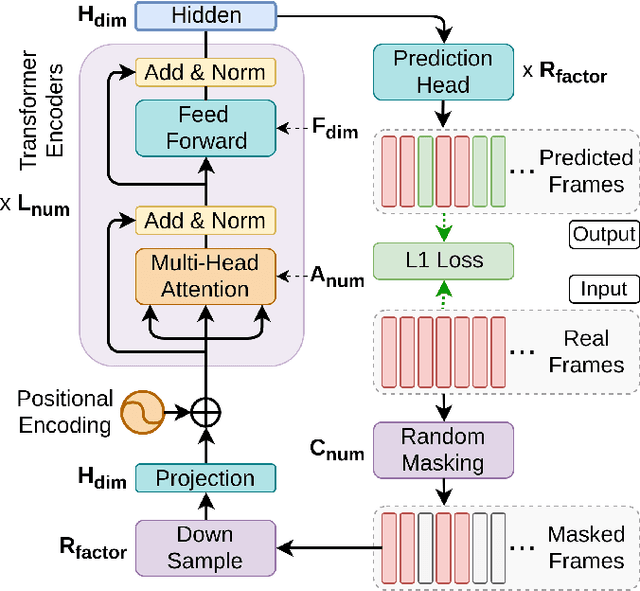
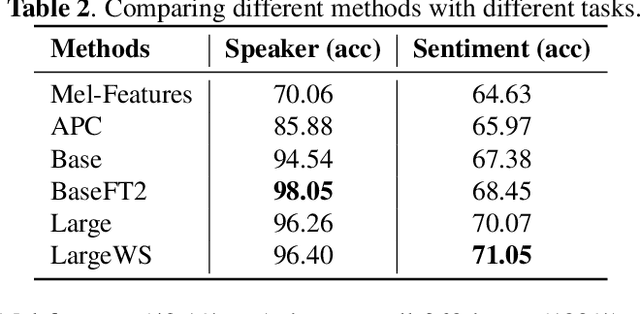
We present Mockingjay as a new speech representation learning approach, where bidirectional Transformer encoders are pre-trained on a large amount of unlabeled speech. Previous speech representation methods learn through conditioning on past frames and predicting information about future frames. Whereas Mockingjay is designed to predict the current frame through jointly conditioning on both past and future contexts. The Mockingjay representation improves performance for a wide range of downstream tasks, including phoneme classification, speaker recognition, and sentiment classification on spoken content, while outperforming other approaches. Mockingjay is empirically powerful and can be fine-tuned with downstream models, with only 2 epochs we further improve performance dramatically. In a low resource setting with only 0.1% of labeled data, we outperform the result of Mel-features that uses all 100% labeled data.