Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHand-crafted Attention is All You Need? A Study of Attention on Self-supervised Audio Transformer
Paper and Code
Jun 09, 2020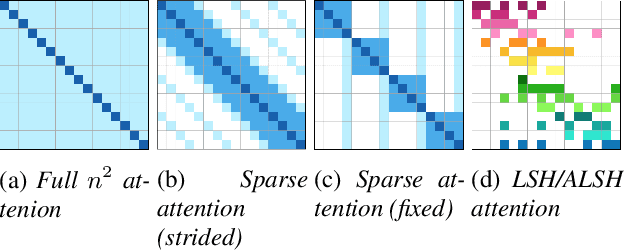


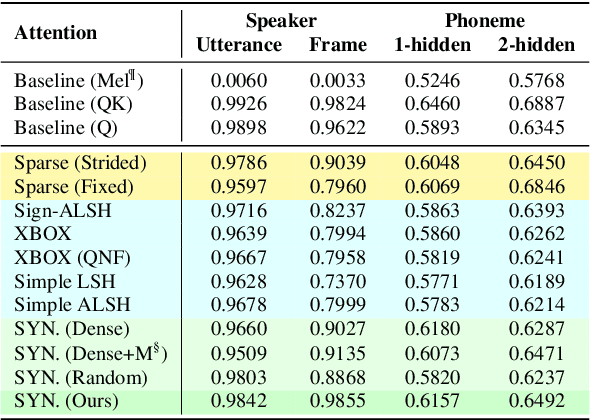
In this paper, we seek to reduce the computation complexity of transformer-based models for speech representation learning. We evaluate 10 attention mechanisms; then, we pre-train the transformer-based model with those attentions in a self-supervised fashion and use them as feature extractors on downstream tasks, including phoneme classification and speaker classification. We find that the proposed approach, which only uses hand-crafted and learnable attentions, is comparable with the full self-attention.
View paper on