 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural machine translation of clinical procedure codes for medical diagnosis and uncertainty quantification
Feb 07, 2024A Clinical Decision Support System (CDSS) is designed to enhance clinician decision-making by combining system-generated recommendations with medical expertise. Given the high costs, intensive labor, and time-sensitive nature of medical treatments, there is a pressing need for efficient decision support, especially in complex emergency scenarios. In these scenarios, where information can be limited, an advanced CDSS framework that leverages AI (artificial intelligence) models to effectively reduce diagnostic uncertainty has utility. Such an AI-enabled CDSS framework with quantified uncertainty promises to be practical and beneficial in the demanding context of real-world medical care. In this study, we introduce the concept of Medical Entropy, quantifying uncertainties in patient outcomes predicted by neural machine translation based on the ICD-9 code of procedures. Our experimental results not only show strong correlations between procedure and diagnosis sequences based on the simple ICD-9 code but also demonstrate the promising capacity to model trends of uncertainties during hospitalizations through a data-driven approach.
Audio ALBERT: A Lite BERT for Self-supervised Learning of Audio Representation
May 26, 2020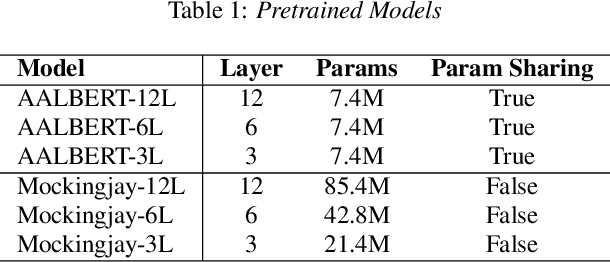
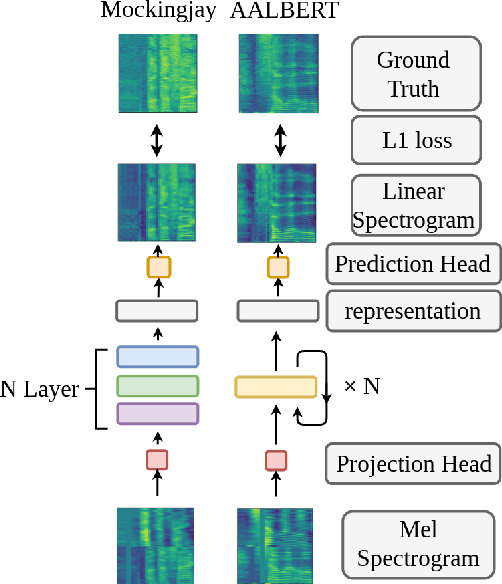
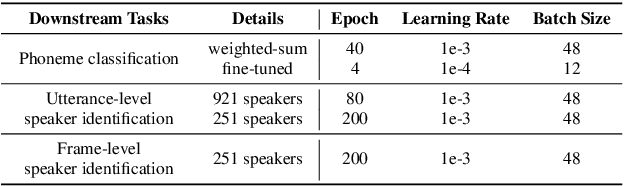
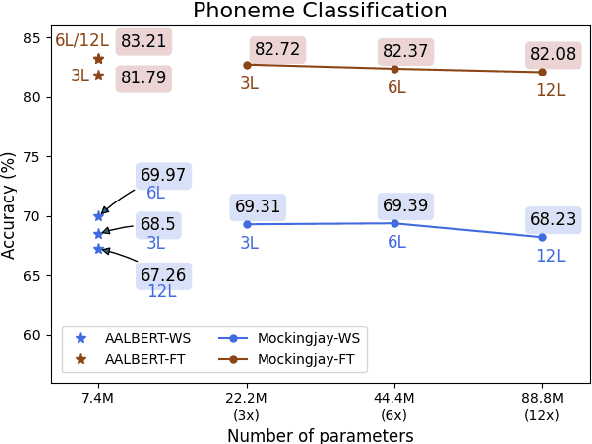
For self-supervised speech processing, it is crucial to use pretrained models as speech representation extractors. In recent works, increasing the size of the model has been utilized in acoustic model training in order to achieve better performance. In this paper, we propose Audio ALBERT, a lite version of the self-supervised speech representation model. We use the representations with two downstream tasks, speaker identification, and phoneme classification. We show that Audio ALBERT is capable of achieving competitive performance with those huge models in the downstream tasks while utilizing 91\% fewer parameters. Moreover, we use some simple probing models to measure how much the information of the speaker and phoneme is encoded in latent representations. In probing experiments, we find that the latent representations encode richer information of both phoneme and speaker than that of the last layer.
Joint Learning of Interactive Spoken Content Retrieval and Trainable User Simulator
Apr 01, 2018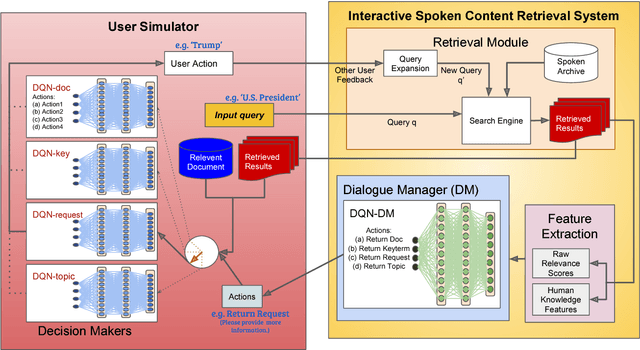
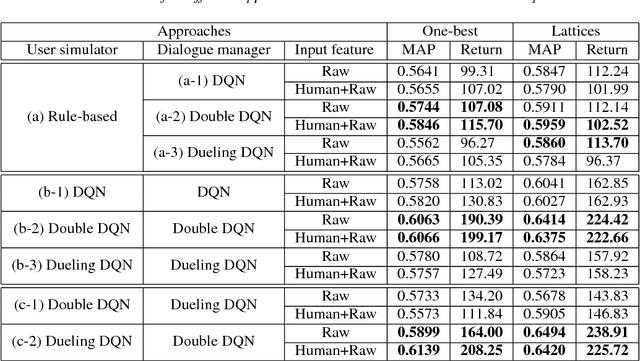
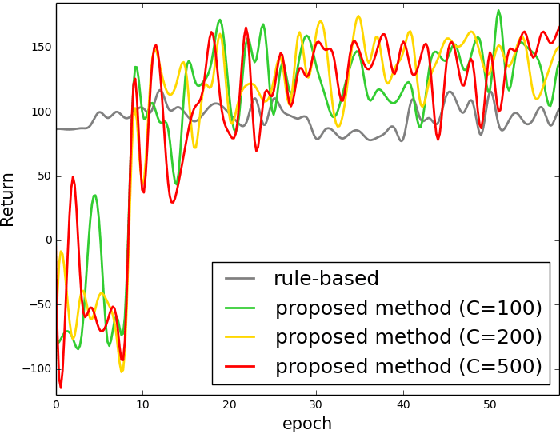

User-machine interaction is crucial for information retrieval, especially for spoken content retrieval, because spoken content is difficult to browse, and speech recognition has a high degree of uncertainty. In interactive retrieval, the machine takes different actions to interact with the user to obtain better retrieval results; here it is critical to select the most efficient action. In previous work, deep Q-learning techniques were proposed to train an interactive retrieval system but rely on a hand-crafted user simulator; building a reliable user simulator is difficult. In this paper, we further improve the interactive spoken content retrieval framework by proposing a learnable user simulator which is jointly trained with interactive retrieval system, making the hand-crafted user simulator unnecessary. The experimental results show that the learned simulated users not only achieve larger rewards than the hand-crafted ones but act more like real users.