 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Prompt Tuning
May 24, 2022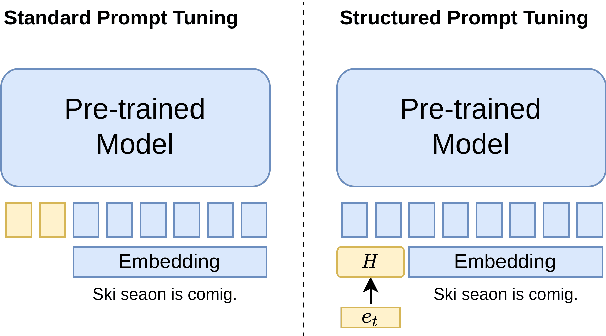
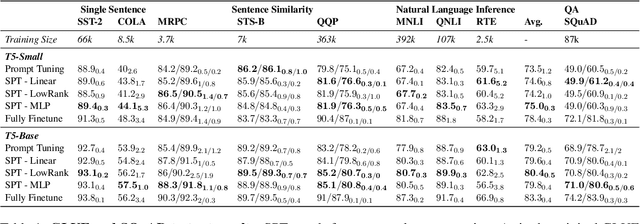

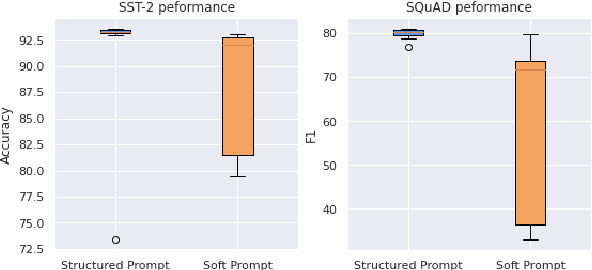
We propose structured prompt tuning, a simple and effective method to improve prompt tuning. Instead of prepending a sequence of tunable embeddings to the input, we generate the soft prompt embeddings through a hypernetwork. Our approach subsumes the standard prompt tuning, allows more flexibility in model design and can be applied to both single-task and multi-task training settings. Empirically, structured prompt tuning shows a gain of +1.2$~1.5 points on the GLUE benchmark and is less sensitive to the change of learning rate, compared to standard prompt tuning.
SpeechNet: A Universal Modularized Model for Speech Processing Tasks
May 31, 2021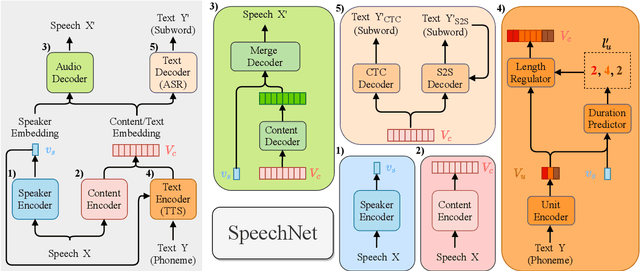
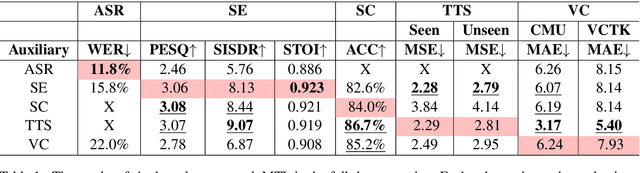
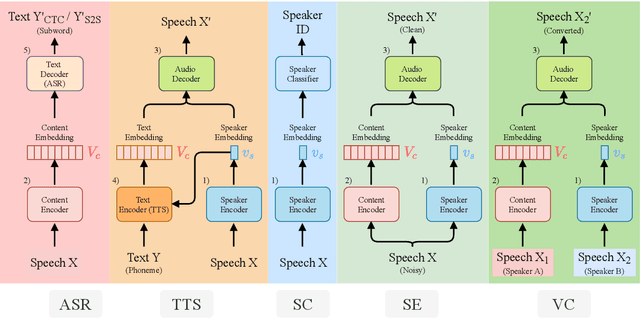
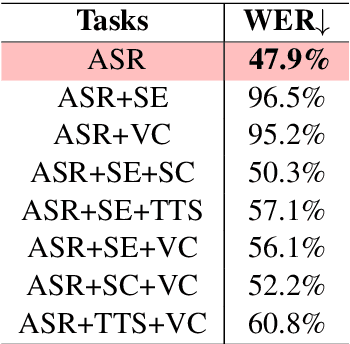
There is a wide variety of speech processing tasks ranging from extracting content information from speech signals to generating speech signals. For different tasks, model networks are usually designed and tuned separately. If a universal model can perform multiple speech processing tasks, some tasks might be improved with the related abilities learned from other tasks. The multi-task learning of a wide variety of speech processing tasks with a universal model has not been studied. This paper proposes a universal modularized model, SpeechNet, which treats all speech processing tasks into a speech/text input and speech/text output format. We select five essential speech processing tasks for multi-task learning experiments with SpeechNet. We show that SpeechNet learns all of the above tasks, and we further analyze which tasks can be improved by other tasks. SpeechNet is modularized and flexible for incorporating more modules, tasks, or training approaches in the future. We release the code and experimental settings to facilitate the research of modularized universal models and multi-task learning of speech processing tasks.
Language Representation in Multilingual BERT and its applications to improve Cross-lingual Generalization
Oct 23, 2020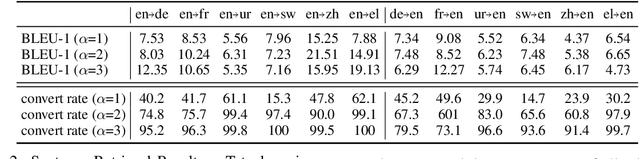
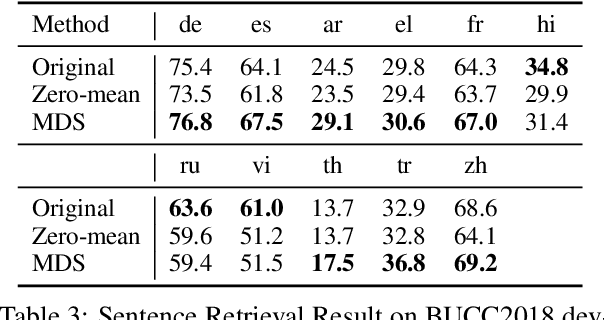
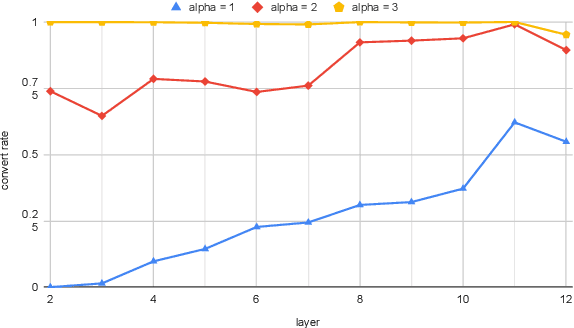
A token embedding in multilingual BERT (m-BERT) contains both language and semantic information. We find that representation of a language can be obtained by simply averaging the embeddings of the tokens of the language. With the language representation, we can control the output languages of multilingual BERT by manipulating the token embeddings and achieve unsupervised token translation. We further propose a computationally cheap but effective approach to improve the cross-lingual ability of m-BERT based on the observation.
Unsupervised Deep Learning based Multiple Choices Question Answering: Start Learning from Basic Knowledge
Oct 21, 2020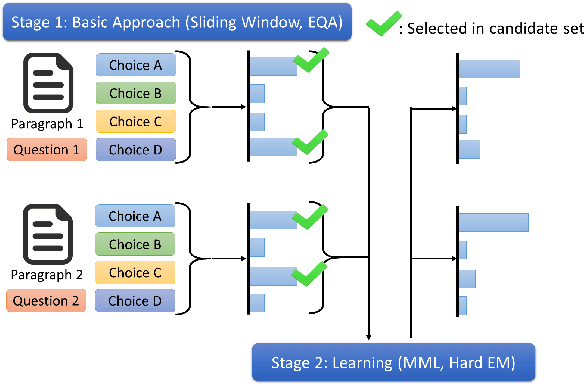
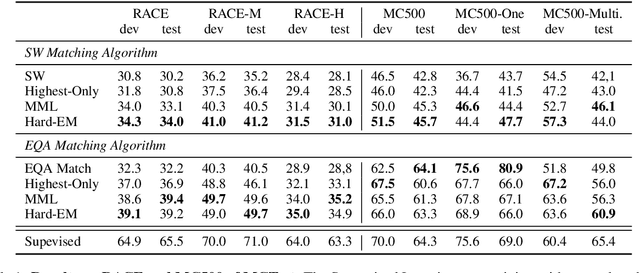
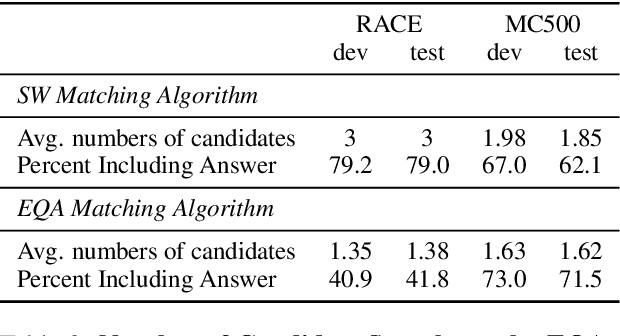

In this paper, we study the possibility of almost unsupervised Multiple Choices Question Answering (MCQA). Starting from very basic knowledge, MCQA model knows that some choices have higher probabilities of being correct than the others. The information, though very noisy, guides the training of an MCQA model. The proposed method is shown to outperform the baseline approaches on RACE and even comparable with some supervised learning approaches on MC500.
What makes multilingual BERT multilingual?
Oct 20, 2020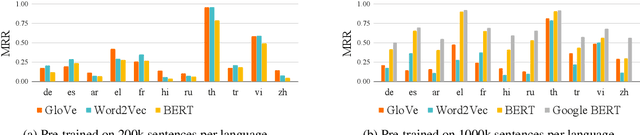
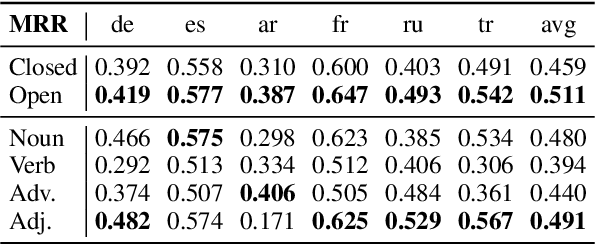
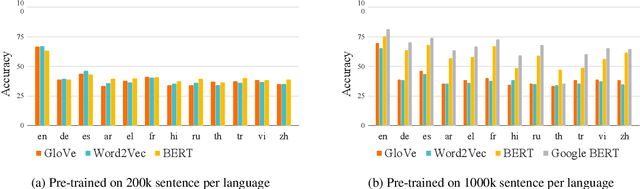
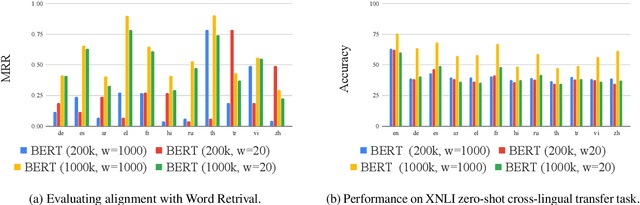
Recently, multilingual BERT works remarkably well on cross-lingual transfer tasks, superior to static non-contextualized word embeddings. In this work, we provide an in-depth experimental study to supplement the existing literature of cross-lingual ability. We compare the cross-lingual ability of non-contextualized and contextualized representation model with the same data. We found that datasize and context window size are crucial factors to the transferability.
A Study of Cross-Lingual Ability and Language-specific Information in Multilingual BERT
Apr 20, 2020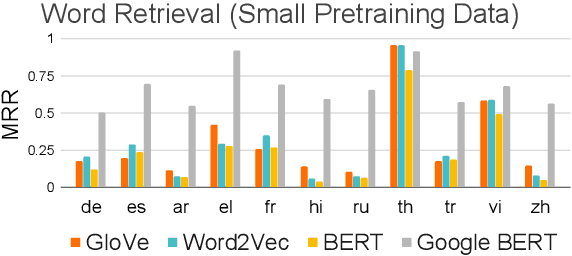

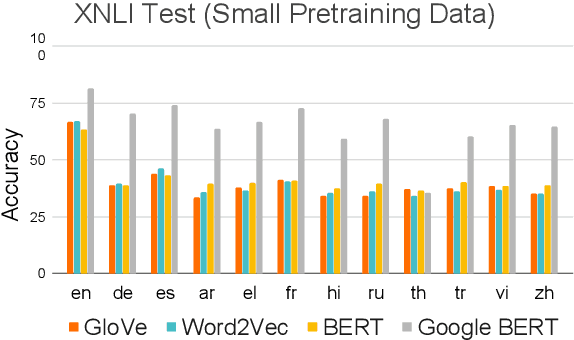
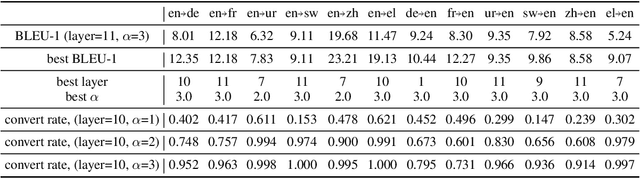
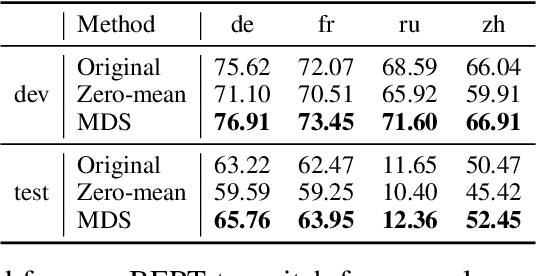
Recently, multilingual BERT works remarkably well on cross-lingual transfer tasks, superior to static non-contextualized word embeddings. In this work, we provide an in-depth experimental study to supplement the existing literature of cross-lingual ability. We compare the cross-lingual ability of non-contextualized and contextualized representation model with the same data. We found that datasize and context window size are crucial factors to the transferability. We also observe the language-specific information in multilingual BERT. By manipulating the latent representations, we can control the output languages of multilingual BERT, and achieve unsupervised token translation. We further show that based on the observation, there is a computationally cheap but effective approach to improve the cross-lingual ability of multilingual BERT.
SpeechBERT: Cross-Modal Pre-trained Language Model for End-to-end Spoken Question Answering
Oct 25, 2019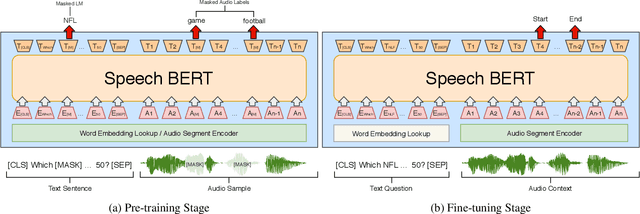
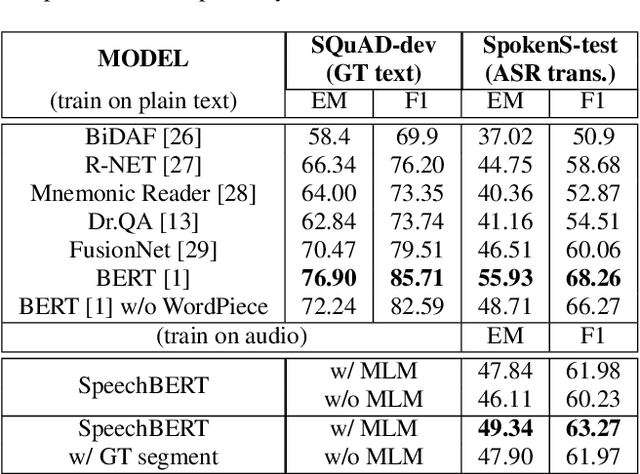
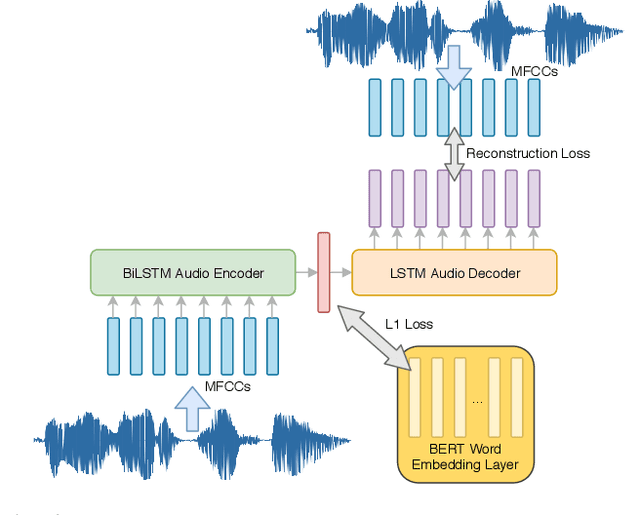
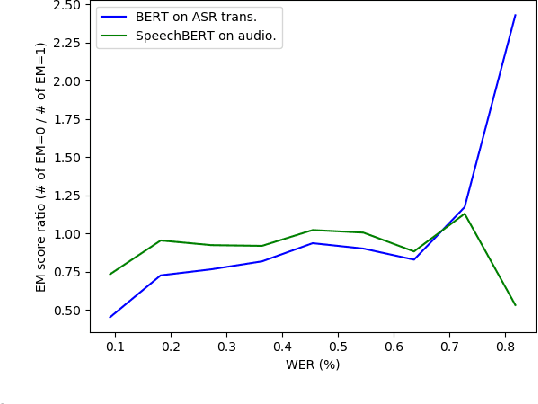
While end-to-end models for spoken language understanding tasks have been explored recently, there is still no end-to-end model for spoken question answering (SQA) tasks, which would be catastrophically influenced by speech recognition errors. Meanwhile, pre-trained language models, such as BERT, have performed successfully in text question answering. To bring this advantage of pre-trained language models into spoken question answering, we propose SpeechBERT, a cross-modal transformer-based pre-trained language model. As the first exploration in end-to-end SQA models, our results matched the performance of conventional approaches that fed with output text from ASR and only slightly fell behind pre-trained language models, showing the potential of end-to-end SQA models.
Spoken SQuAD: A Study of Mitigating the Impact of Speech Recognition Errors on Listening Comprehension
Apr 01, 2018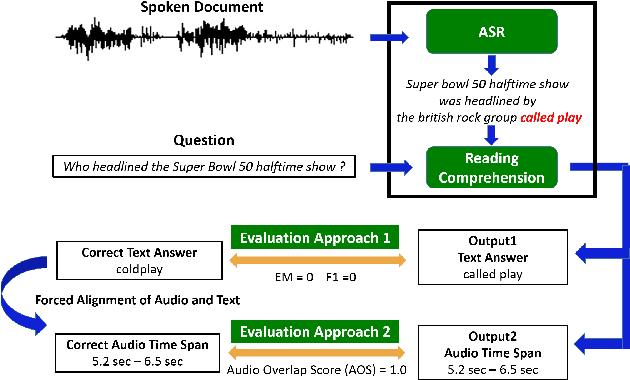


Reading comprehension has been widely studied. One of the most representative reading comprehension tasks is Stanford Question Answering Dataset (SQuAD), on which machine is already comparable with human. On the other hand, accessing large collections of multimedia or spoken content is much more difficult and time-consuming than plain text content for humans. It's therefore highly attractive to develop machines which can automatically understand spoken content. In this paper, we propose a new listening comprehension task - Spoken SQuAD. On the new task, we found that speech recognition errors have catastrophic impact on machine comprehension, and several approaches are proposed to mitigate the impact.