Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpoken SQuAD: A Study of Mitigating the Impact of Speech Recognition Errors on Listening Comprehension
Apr 01, 2018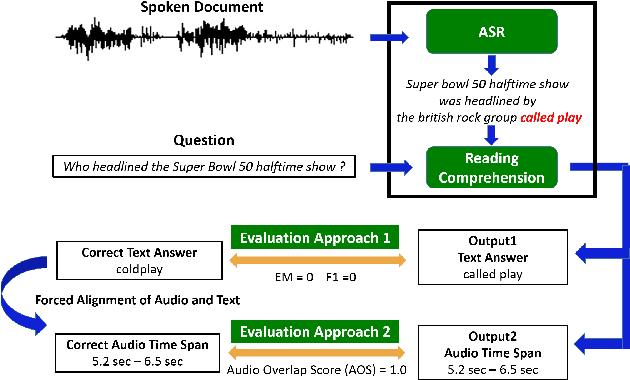
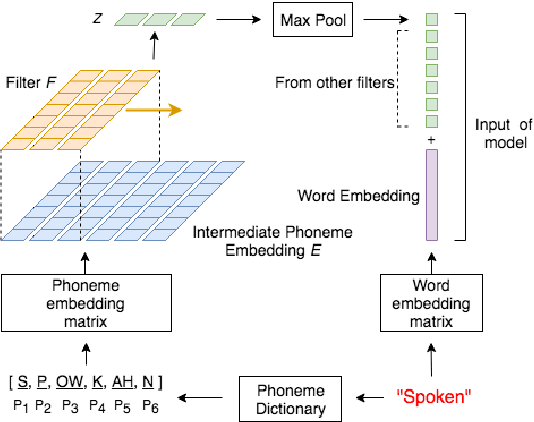


Reading comprehension has been widely studied. One of the most representative reading comprehension tasks is Stanford Question Answering Dataset (SQuAD), on which machine is already comparable with human. On the other hand, accessing large collections of multimedia or spoken content is much more difficult and time-consuming than plain text content for humans. It's therefore highly attractive to develop machines which can automatically understand spoken content. In this paper, we propose a new listening comprehension task - Spoken SQuAD. On the new task, we found that speech recognition errors have catastrophic impact on machine comprehension, and several approaches are proposed to mitigate the impact.
Via