 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study of Cross-Lingual Ability and Language-specific Information in Multilingual BERT
Paper and Code
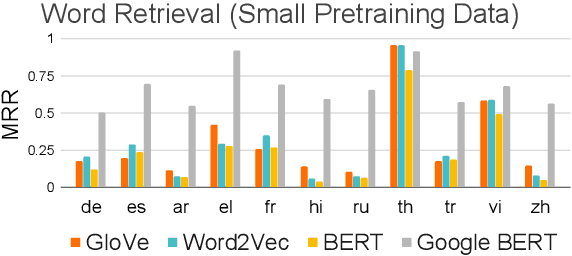

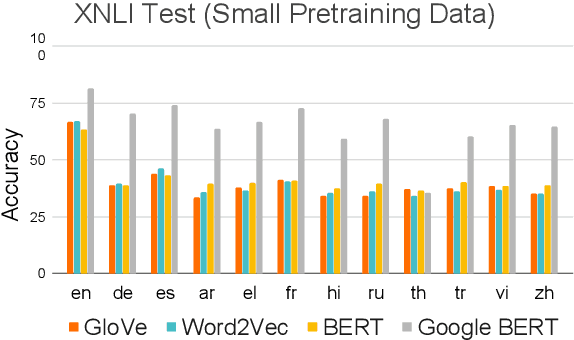
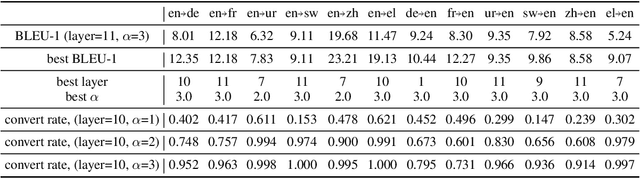
Recently, multilingual BERT works remarkably well on cross-lingual transfer tasks, superior to static non-contextualized word embeddings. In this work, we provide an in-depth experimental study to supplement the existing literature of cross-lingual ability. We compare the cross-lingual ability of non-contextualized and contextualized representation model with the same data. We found that datasize and context window size are crucial factors to the transferability. We also observe the language-specific information in multilingual BERT. By manipulating the latent representations, we can control the output languages of multilingual BERT, and achieve unsupervised token translation. We further show that based on the observation, there is a computationally cheap but effective approach to improve the cross-lingual ability of multilingual BERT.