 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Representation in Multilingual BERT and its applications to improve Cross-lingual Generalization
Oct 23, 2020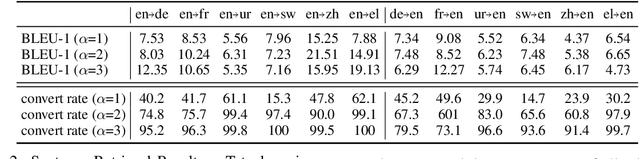
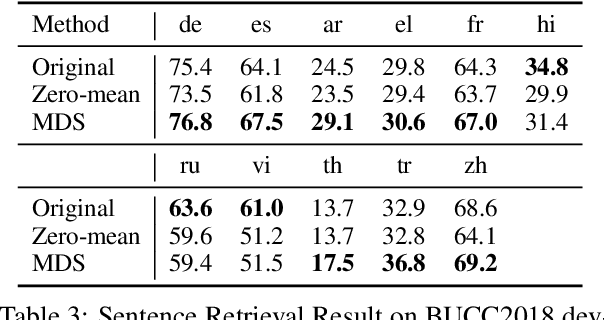
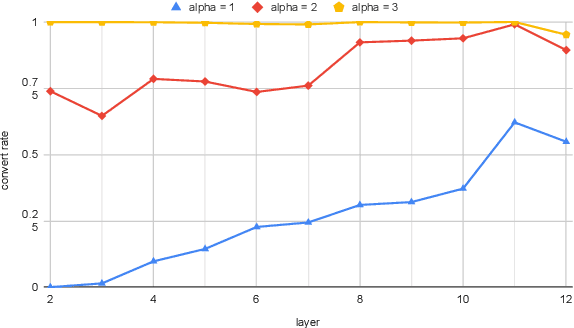
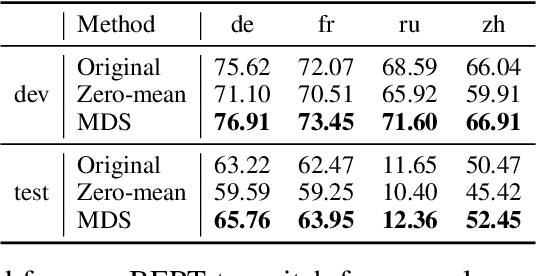
A token embedding in multilingual BERT (m-BERT) contains both language and semantic information. We find that representation of a language can be obtained by simply averaging the embeddings of the tokens of the language. With the language representation, we can control the output languages of multilingual BERT by manipulating the token embeddings and achieve unsupervised token translation. We further propose a computationally cheap but effective approach to improve the cross-lingual ability of m-BERT based on the observation.
What makes multilingual BERT multilingual?
Oct 20, 2020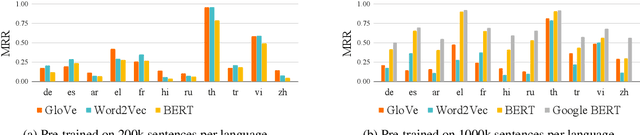
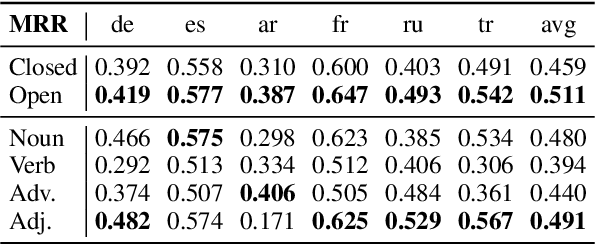
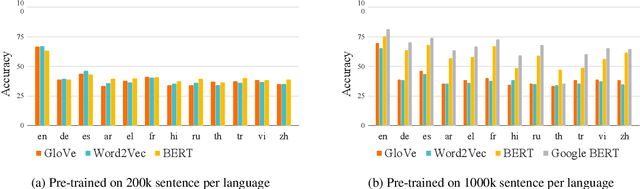
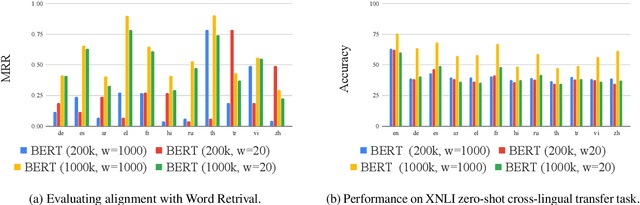
Recently, multilingual BERT works remarkably well on cross-lingual transfer tasks, superior to static non-contextualized word embeddings. In this work, we provide an in-depth experimental study to supplement the existing literature of cross-lingual ability. We compare the cross-lingual ability of non-contextualized and contextualized representation model with the same data. We found that datasize and context window size are crucial factors to the transferability.
Investigation of Sentiment Controllable Chatbot
Jul 11, 2020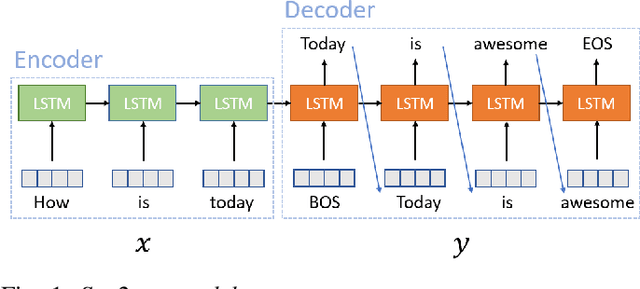
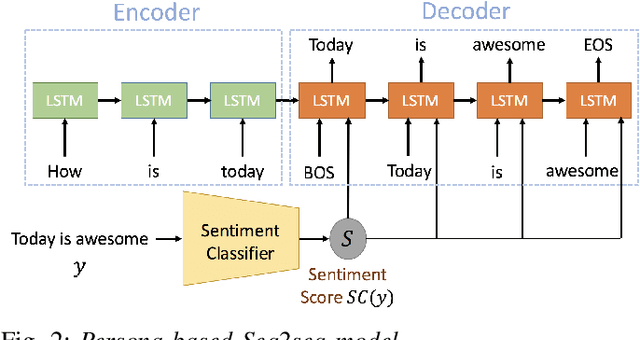
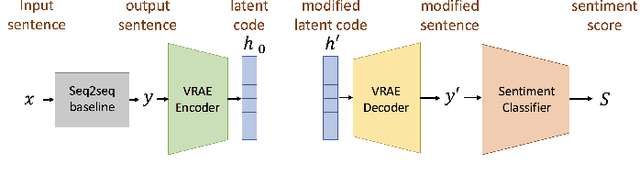
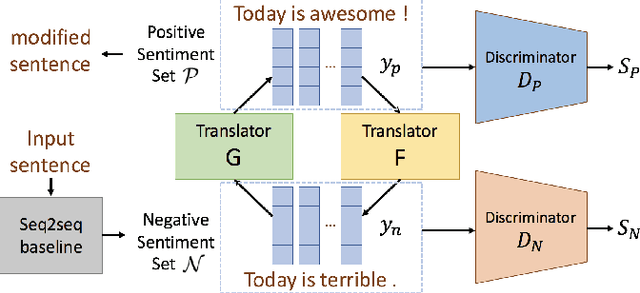
Conventional seq2seq chatbot models attempt only to find sentences with the highest probabilities conditioned on the input sequences, without considering the sentiment of the output sentences. In this paper, we investigate four models to scale or adjust the sentiment of the chatbot response: a persona-based model, reinforcement learning, a plug and play model, and CycleGAN, all based on the seq2seq model. We also develop machine-evaluated metrics to estimate whether the responses are reasonable given the input. These metrics, together with human evaluation, are used to analyze the performance of the four models in terms of different aspects; reinforcement learning and CycleGAN are shown to be very attractive.
A Study of Cross-Lingual Ability and Language-specific Information in Multilingual BERT
Apr 20, 2020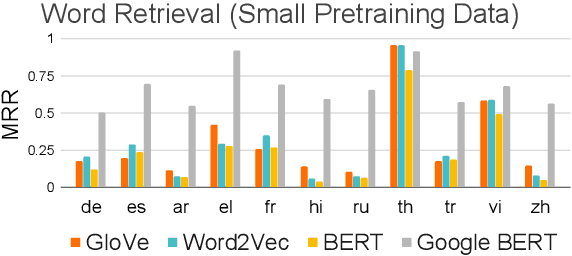

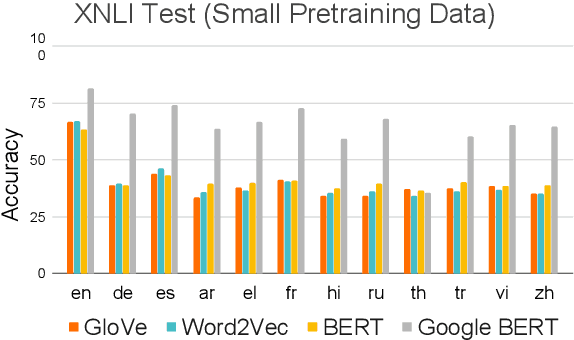
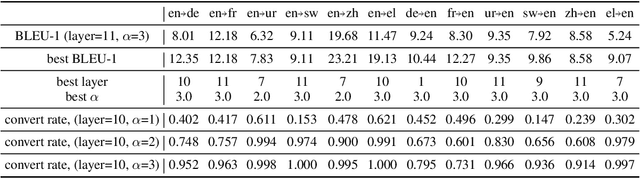
Recently, multilingual BERT works remarkably well on cross-lingual transfer tasks, superior to static non-contextualized word embeddings. In this work, we provide an in-depth experimental study to supplement the existing literature of cross-lingual ability. We compare the cross-lingual ability of non-contextualized and contextualized representation model with the same data. We found that datasize and context window size are crucial factors to the transferability. We also observe the language-specific information in multilingual BERT. By manipulating the latent representations, we can control the output languages of multilingual BERT, and achieve unsupervised token translation. We further show that based on the observation, there is a computationally cheap but effective approach to improve the cross-lingual ability of multilingual BERT.
Scalable Sentiment for Sequence-to-sequence Chatbot Response with Performance Analysis
Apr 07, 2018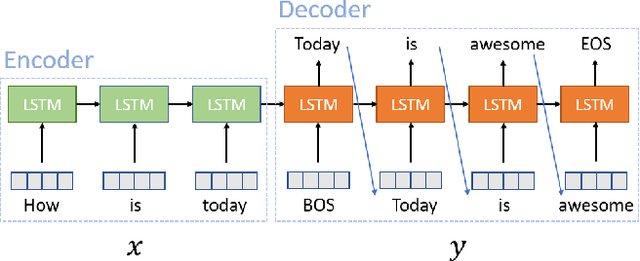
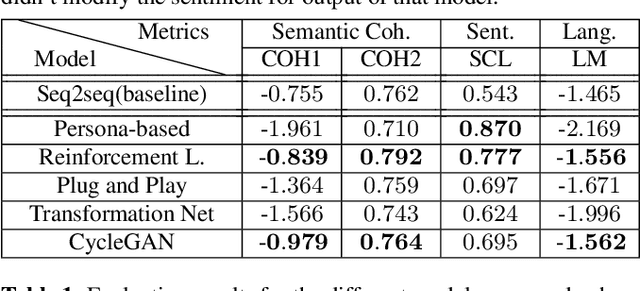
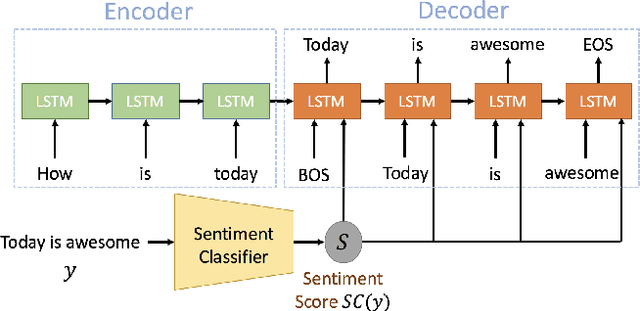
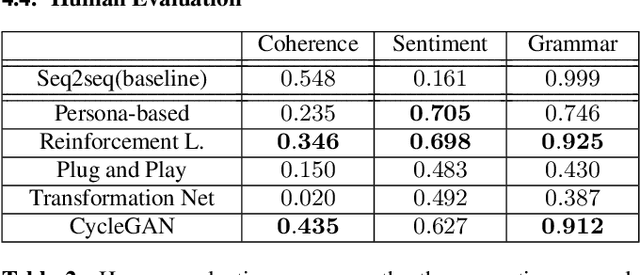
Conventional seq2seq chatbot models only try to find the sentences with the highest probabilities conditioned on the input sequences, without considering the sentiment of the output sentences. Some research works trying to modify the sentiment of the output sequences were reported. In this paper, we propose five models to scale or adjust the sentiment of the chatbot response: persona-based model, reinforcement learning, plug and play model, sentiment transformation network and cycleGAN, all based on the conventional seq2seq model. We also develop two evaluation metrics to estimate if the responses are reasonable given the input. These metrics together with other two popularly used metrics were used to analyze the performance of the five proposed models on different aspects, and reinforcement learning and cycleGAN were shown to be very attractive. The evaluation metrics were also found to be well correlated with human evaluation.