Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Representation in Multilingual BERT and its applications to improve Cross-lingual Generalization
Paper and Code
Oct 23, 2020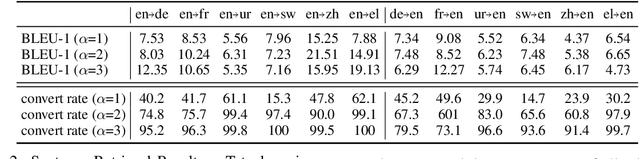
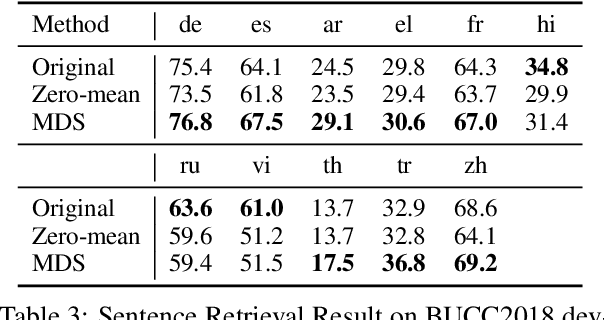
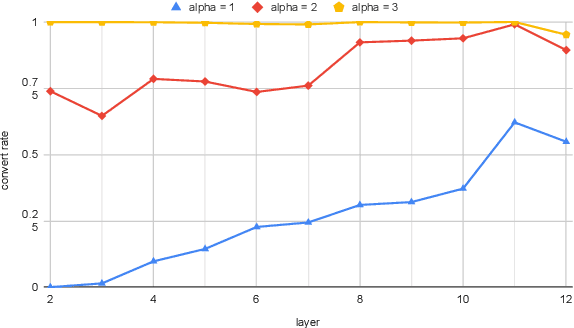
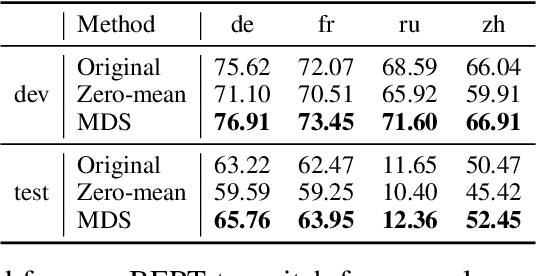
A token embedding in multilingual BERT (m-BERT) contains both language and semantic information. We find that representation of a language can be obtained by simply averaging the embeddings of the tokens of the language. With the language representation, we can control the output languages of multilingual BERT by manipulating the token embeddings and achieve unsupervised token translation. We further propose a computationally cheap but effective approach to improve the cross-lingual ability of m-BERT based on the observation.
* preprint
View paper on