Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs BERT a Cross-Disciplinary Knowledge Learner? A Surprising Finding of Pre-trained Models' Transferability
Paper and Code
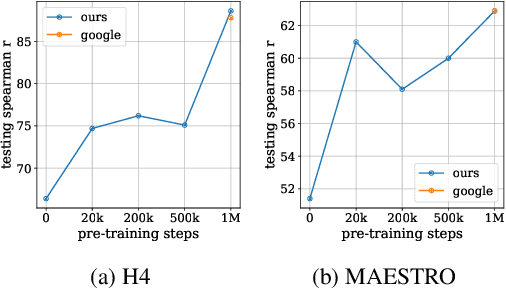
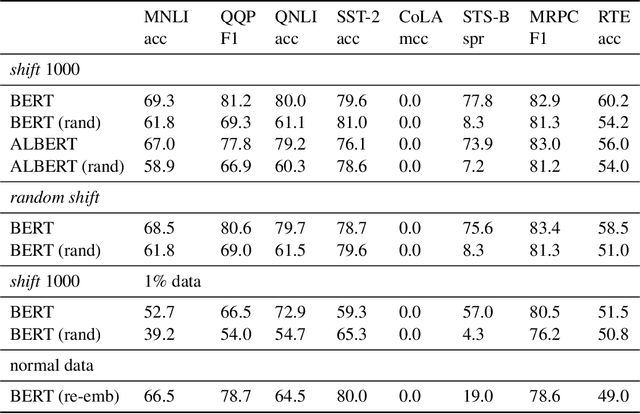
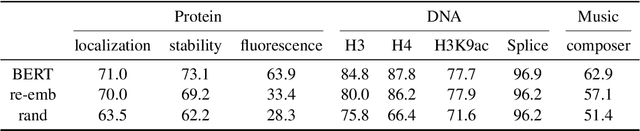
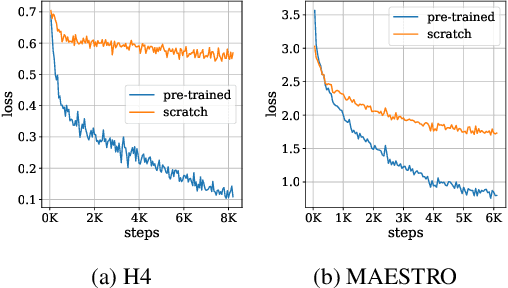
In this paper, we investigate whether the power of the models pre-trained on text data, such as BERT, can be transferred to general token sequence classification applications. To verify pre-trained models' transferability, we test the pre-trained models on (1) text classification tasks with meanings of tokens mismatches, and (2) real-world non-text token sequence classification data, including amino acid sequence, DNA sequence, and music. We find that even on non-text data, the models pre-trained on text converge faster than the randomly initialized models, and the testing performance of the pre-trained models is merely slightly worse than the models designed for the specific tasks.
* 9 pages, 7 figures
View paper on