 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Integrated Artificial Intelligence Operating System for Advanced Low-Altitude Aviation Applications
Nov 28, 2024This paper introduces a comprehensive artificial intelligence operating system tailored for low-altitude aviation applications, integrating cutting-edge technologies for enhanced performance, safety, and efficiency. The system comprises six core components: OrinFlight OS, a high-performance operating system optimized for real-time task execution; UnitedVision, a versatile visual processing module supporting advanced image analysis; UnitedSense, a multi-sensor fusion module providing precise environmental modeling; UnitedNavigator, a dynamic path-planning and navigation system; UnitedMatrix, enabling multi-drone coordination and task execution; and UnitedInSight, a ground station for monitoring and management. Complemented by the UA DevKit low-code platform, the system facilitates user-friendly customization and application development. Leveraging NVIDIA Orin's computational power and advanced AI algorithms, this system addresses complex challenges in modern aviation, offering robust solutions for navigation, perception, and collaborative operations. This work highlights the system's architecture, features, and potential applications, demonstrating its ability to meet the demands of intelligent aviation environments.
Extract and Diffuse: Latent Integration for Improved Diffusion-based Speech and Vocal Enhancement
Sep 15, 2024Diffusion-based generative models have recently achieved remarkable results in speech and vocal enhancement due to their ability to model complex speech data distributions. While these models generalize well to unseen acoustic environments, they may not achieve the same level of fidelity as the discriminative models specifically trained to enhance particular acoustic conditions. In this paper, we propose Ex-Diff, a novel score-based diffusion model that integrates the latent representations produced by a discriminative model to improve speech and vocal enhancement, which combines the strengths of both generative and discriminative models. Experimental results on the widely used MUSDB dataset show relative improvements of 3.7% in SI-SDR and 10.0% in SI-SIR compared to the baseline diffusion model for speech and vocal enhancement tasks, respectively. Additionally, case studies are provided to further illustrate and analyze the complementary nature of generative and discriminative models in this context.
GE-Grasp: Efficient Target-Oriented Grasping in Dense Clutter
Jul 25, 2022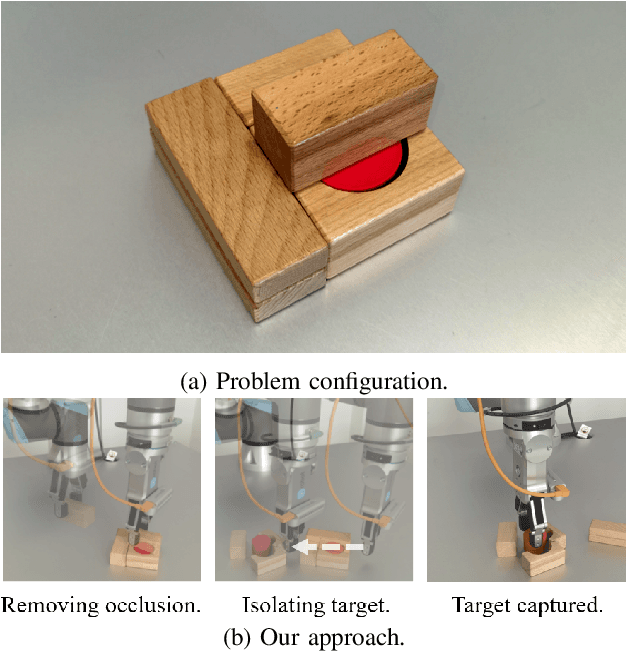
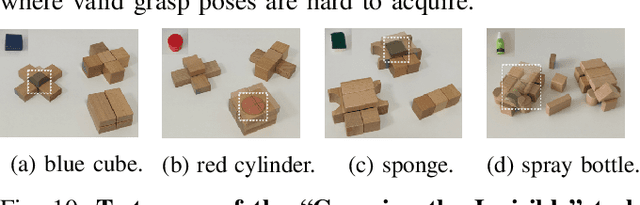

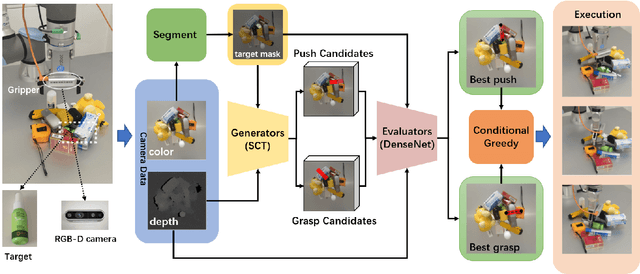
Grasping in dense clutter is a fundamental skill for autonomous robots. However, the crowdedness and occlusions in the cluttered scenario cause significant difficulties to generate valid grasp poses without collisions, which results in low efficiency and high failure rates. To address these, we present a generic framework called GE-Grasp for robotic motion planning in dense clutter, where we leverage diverse action primitives for occluded object removal and present the generator-evaluator architecture to avoid spatial collisions. Therefore, our GE-Grasp is capable of grasping objects in dense clutter efficiently with promising success rates. Specifically, we define three action primitives: target-oriented grasping for target capturing, pushing, and nontarget-oriented grasping to reduce the crowdedness and occlusions. The generators effectively provide various action candidates referring to the spatial information. Meanwhile, the evaluators assess the selected action primitive candidates, where the optimal action is implemented by the robot. Extensive experiments in simulated and real-world environments show that our approach outperforms the state-of-the-art methods of grasping in clutter with respect to motion efficiency and success rates. Moreover, we achieve comparable performance in the real world as that in the simulation environment, which indicates the strong generalization ability of our GE-Grasp. Supplementary material is available at: https://github.com/CaptainWuDaoKou/GE-Grasp.