 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Reinforcement Learning from Delayed Marketplace Feedback for Objective-Weight Adaptation in Three-Sided Dispatch
Jun 11, 2026Dispatch in three-sided marketplaces provides a natural setting for reinforcement learning from world feedback: decisions are evaluated by delayed operational outcomes such as delivery speed, courier utilization, and merchant congestion. We present a deployed reinforcement learning system at DoorDash that adapts dispatch objective weights in a large-scale food-delivery marketplace using delayed signals. Rather than replacing the combinatorial assignment optimizer, a store-level policy learned from logged marketplace data selects a discrete multiplier that shifts the dispatch optimizer's tradeoff between delivery quality and batching efficiency. This interface enables offline policy learning under noisy, delayed, and coupled feedback while preserving production feasibility constraints and operational safeguards. We train a shared value function using centralized offline data and decentralized store-level execution, with Double Q-learning targets and a conservative regularizer to reduce out-of-distribution value overestimation. In a production switchback experiment, the offline-trained policy increases batching and reduces courier-side time costs without degrading customer-facing delivery quality. Results illustrate how world feedback from a live economic and logistics system can be used to safely adapt decision policies online.
An Integrated Artificial Intelligence Operating System for Advanced Low-Altitude Aviation Applications
Nov 28, 2024This paper introduces a comprehensive artificial intelligence operating system tailored for low-altitude aviation applications, integrating cutting-edge technologies for enhanced performance, safety, and efficiency. The system comprises six core components: OrinFlight OS, a high-performance operating system optimized for real-time task execution; UnitedVision, a versatile visual processing module supporting advanced image analysis; UnitedSense, a multi-sensor fusion module providing precise environmental modeling; UnitedNavigator, a dynamic path-planning and navigation system; UnitedMatrix, enabling multi-drone coordination and task execution; and UnitedInSight, a ground station for monitoring and management. Complemented by the UA DevKit low-code platform, the system facilitates user-friendly customization and application development. Leveraging NVIDIA Orin's computational power and advanced AI algorithms, this system addresses complex challenges in modern aviation, offering robust solutions for navigation, perception, and collaborative operations. This work highlights the system's architecture, features, and potential applications, demonstrating its ability to meet the demands of intelligent aviation environments.
VoroNav: Voronoi-based Zero-shot Object Navigation with Large Language Model
Jan 05, 2024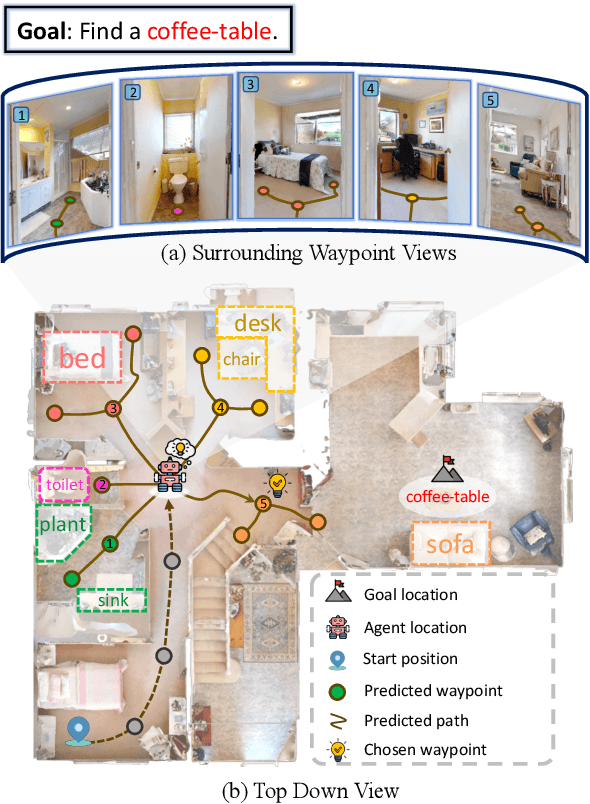
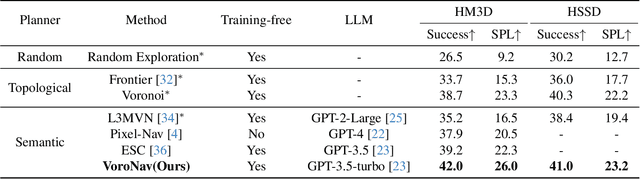
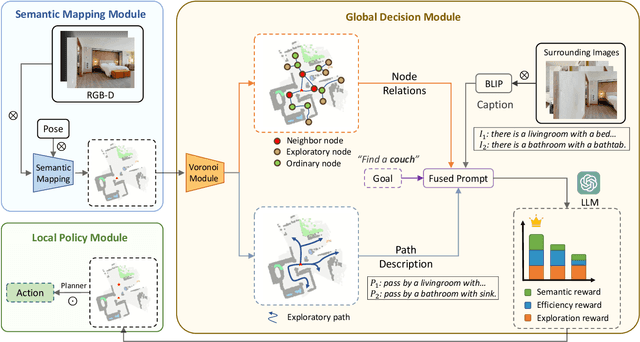
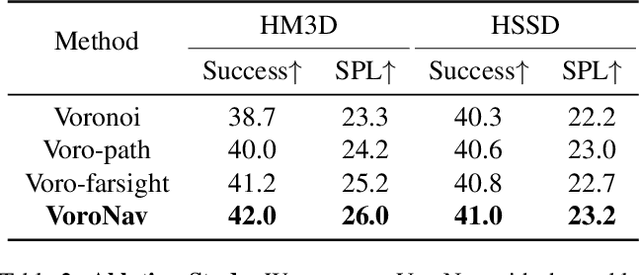
In the realm of household robotics, the Zero-Shot Object Navigation (ZSON) task empowers agents to adeptly traverse unfamiliar environments and locate objects from novel categories without prior explicit training. This paper introduces VoroNav, a novel semantic exploration framework that proposes the Reduced Voronoi Graph to extract exploratory paths and planning nodes from a semantic map constructed in real time. By harnessing topological and semantic information, VoroNav designs text-based descriptions of paths and images that are readily interpretable by a large language model (LLM). Our approach presents a synergy of path and farsight descriptions to represent the environmental context, enabling the LLM to apply commonsense reasoning to ascertain the optimal waypoints for navigation. Extensive evaluation on the HM3D and HSSD datasets validates that VoroNav surpasses existing ZSON benchmarks in both success rates and exploration efficiency (+2.8% Success and +3.7% SPL on HM3D, +2.6% Success and +3.8% SPL on HSSD). Additionally introduced metrics that evaluate obstacle avoidance proficiency and perceptual efficiency further corroborate the enhancements achieved by our method in ZSON planning.
Towards Blind Watermarking: Combining Invertible and Non-invertible Mechanisms
Dec 24, 2022
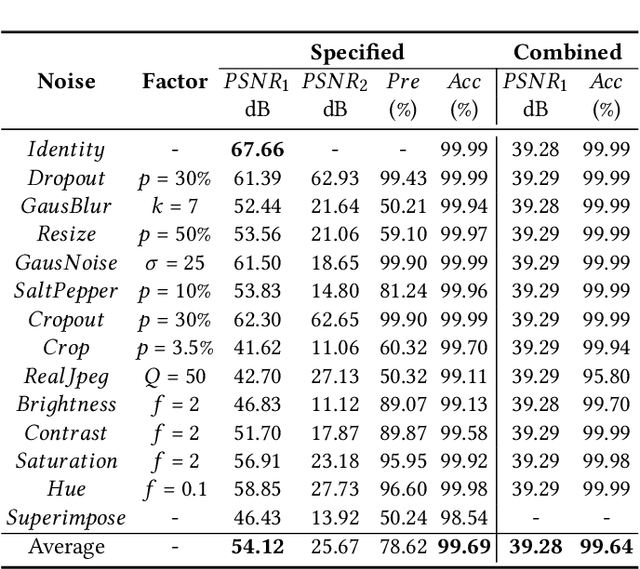
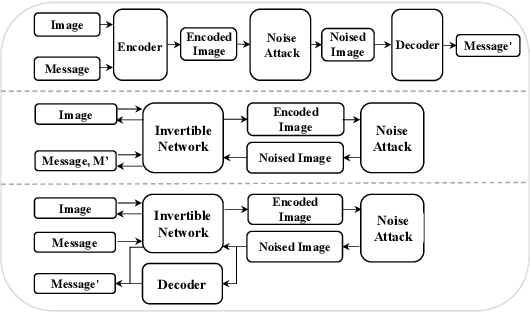
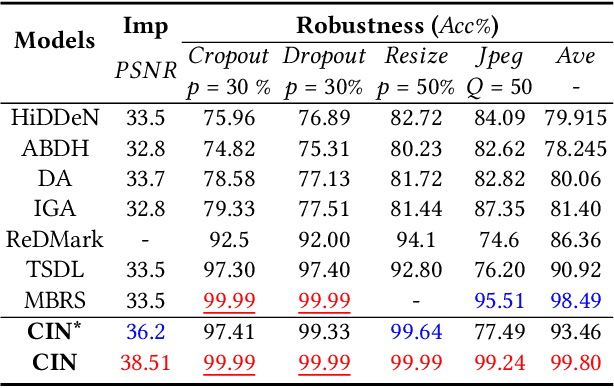
Blind watermarking provides powerful evidence for copyright protection, image authentication, and tampering identification. However, it remains a challenge to design a watermarking model with high imperceptibility and robustness against strong noise attacks. To resolve this issue, we present a framework Combining the Invertible and Non-invertible (CIN) mechanisms. The CIN is composed of the invertible part to achieve high imperceptibility and the non-invertible part to strengthen the robustness against strong noise attacks. For the invertible part, we develop a diffusion and extraction module (DEM) and a fusion and split module (FSM) to embed and extract watermarks symmetrically in an invertible way. For the non-invertible part, we introduce a non-invertible attention-based module (NIAM) and the noise-specific selection module (NSM) to solve the asymmetric extraction under a strong noise attack. Extensive experiments demonstrate that our framework outperforms the current state-of-the-art methods of imperceptibility and robustness significantly. Our framework can achieve an average of 99.99% accuracy and 67.66 dB PSNR under noise-free conditions, while 96.64% and 39.28 dB combined strong noise attacks. The code will be available in https://github.com/rmpku/CIN.
Enhancing and Dissecting Crowd Counting By Synthetic Data
Jan 22, 2022
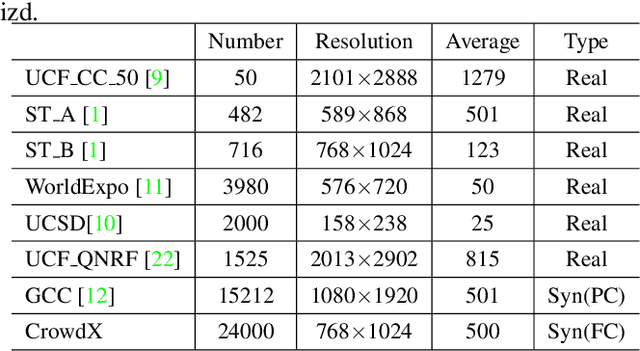

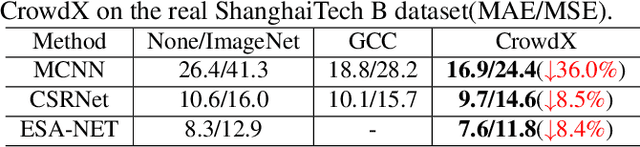
In this article, we propose a simulated crowd counting dataset CrowdX, which has a large scale, accurate labeling, parameterized realization, and high fidelity. The experimental results of using this dataset as data enhancement show that the performance of the proposed streamlined and efficient benchmark network ESA-Net can be improved by 8.4\%. The other two classic heterogeneous architectures MCNN and CSRNet pre-trained on CrowdX also show significant performance improvements. Considering many influencing factors determine performance, such as background, camera angle, human density, and resolution. Although these factors are important, there is still a lack of research on how they affect crowd counting. Thanks to the CrowdX dataset with rich annotation information, we conduct a large number of data-driven comparative experiments to analyze these factors. Our research provides a reference for a deeper understanding of the crowd counting problem and puts forward some useful suggestions in the actual deployment of the algorithm.
BBA-net: A bi-branch attention network for crowd counting
Jan 22, 2022
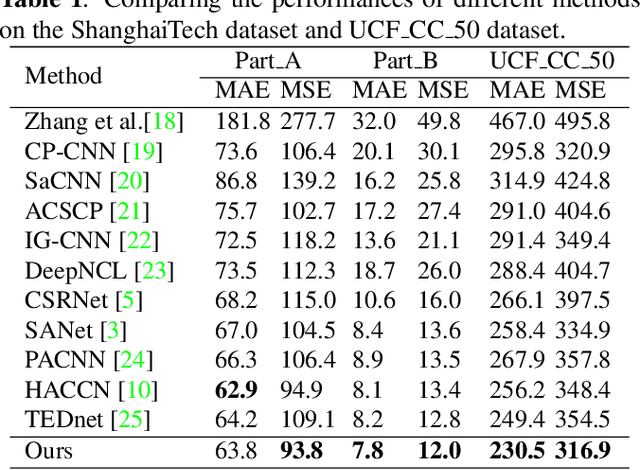
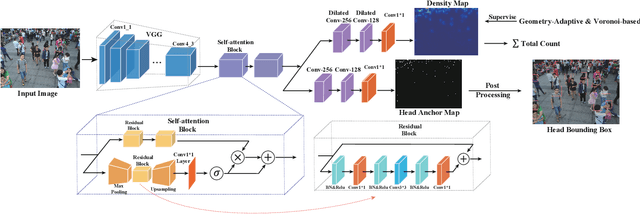

In the field of crowd counting, the current mainstream CNN-based regression methods simply extract the density information of pedestrians without finding the position of each person. This makes the output of the network often found to contain incorrect responses, which may erroneously estimate the total number and not conducive to the interpretation of the algorithm. To this end, we propose a Bi-Branch Attention Network (BBA-NET) for crowd counting, which has three innovation points. i) A two-branch architecture is used to estimate the density information and location information separately. ii) Attention mechanism is used to facilitate feature extraction, which can reduce false responses. iii) A new density map generation method combining geometric adaptation and Voronoi split is introduced. Our method can integrate the pedestrian's head and body information to enhance the feature expression ability of the density map. Extensive experiments performed on two public datasets show that our method achieves a lower crowd counting error compared to other state-of-the-art methods.
Decentralized Cooperative Lane Changing at Freeway Weaving Areas Using Multi-Agent Deep Reinforcement Learning
Oct 05, 2021
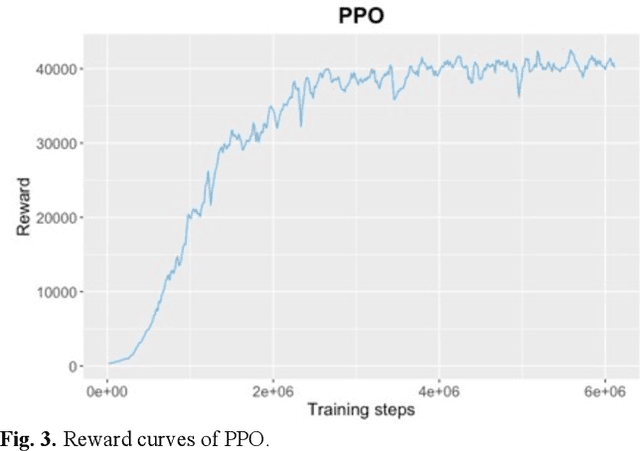
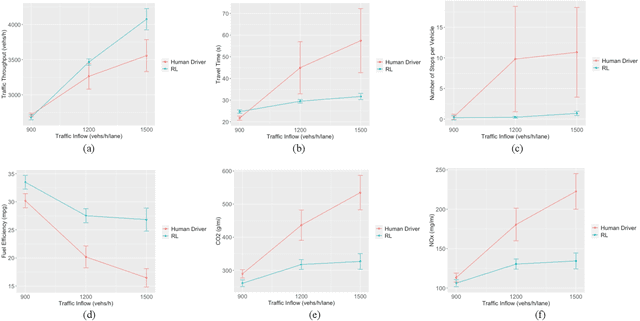
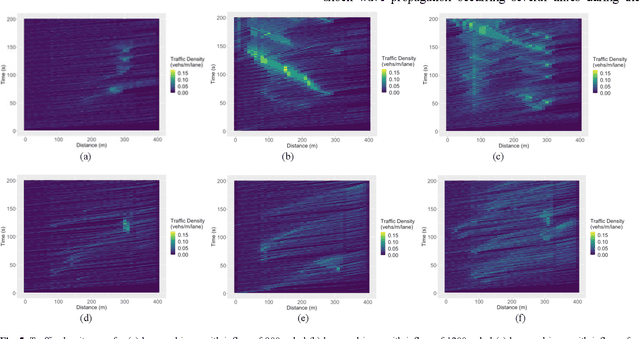
Frequent lane changes during congestion at freeway bottlenecks such as merge and weaving areas further reduce roadway capacity. The emergence of deep reinforcement learning (RL) and connected and automated vehicle technology provides a possible solution to improve mobility and energy efficiency at freeway bottlenecks through cooperative lane changing. Deep RL is a collection of machine-learning methods that enables an agent to improve its performance by learning from the environment. In this study, a decentralized cooperative lane-changing controller was developed using proximal policy optimization by adopting a multi-agent deep RL paradigm. In the decentralized control strategy, policy learning and action reward are evaluated locally, with each agent (vehicle) getting access to global state information. Multi-agent deep RL requires lower computational resources and is more scalable than single-agent deep RL, making it a powerful tool for time-sensitive applications such as cooperative lane changing. The results of this study show that cooperative lane changing enabled by multi-agent deep RL yields superior performance to human drivers in term of traffic throughput, vehicle speed, number of stops per vehicle, vehicle fuel efficiency, and emissions. The trained RL policy is transferable and can be generalized to uncongested, moderately congested, and extremely congested traffic conditions.
A Modular and Transferable Reinforcement Learning Framework for the Fleet Rebalancing Problem
May 27, 2021
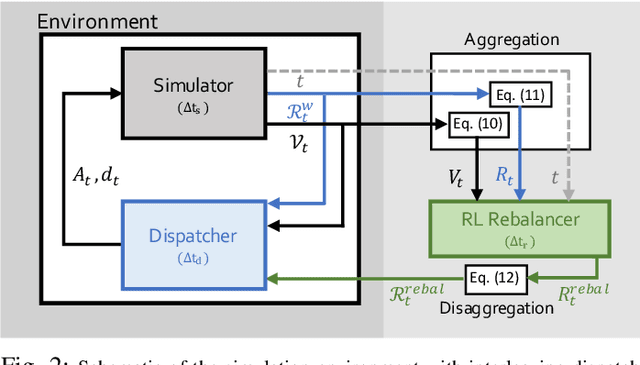
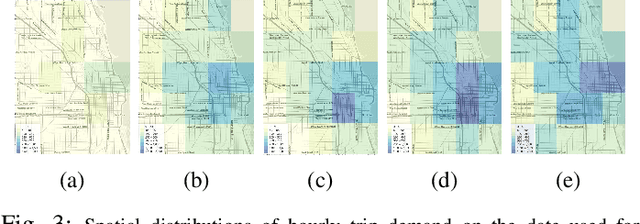
Mobility on demand (MoD) systems show great promise in realizing flexible and efficient urban transportation. However, significant technical challenges arise from operational decision making associated with MoD vehicle dispatch and fleet rebalancing. For this reason, operators tend to employ simplified algorithms that have been demonstrated to work well in a particular setting. To help bridge the gap between novel and existing methods, we propose a modular framework for fleet rebalancing based on model-free reinforcement learning (RL) that can leverage an existing dispatch method to minimize system cost. In particular, by treating dispatch as part of the environment dynamics, a centralized agent can learn to intermittently direct the dispatcher to reposition free vehicles and mitigate against fleet imbalance. We formulate RL state and action spaces as distributions over a grid partitioning of the operating area, making the framework scalable and avoiding the complexities associated with multiagent RL. Numerical experiments, using real-world trip and network data, demonstrate that this approach has several distinct advantages over baseline methods including: improved system cost; high degree of adaptability to the selected dispatch method; and the ability to perform scale-invariant transfer learning between problem instances with similar vehicle and request distributions.
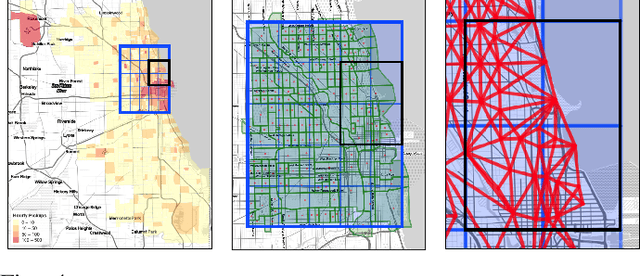
Arbitrary-Oriented Ship Detection through Center-Head Point Extraction
Feb 25, 2021
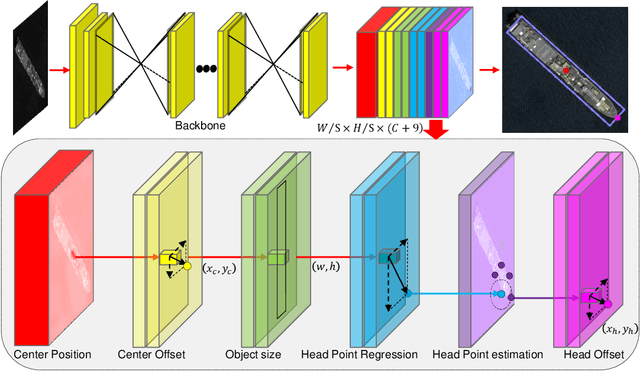
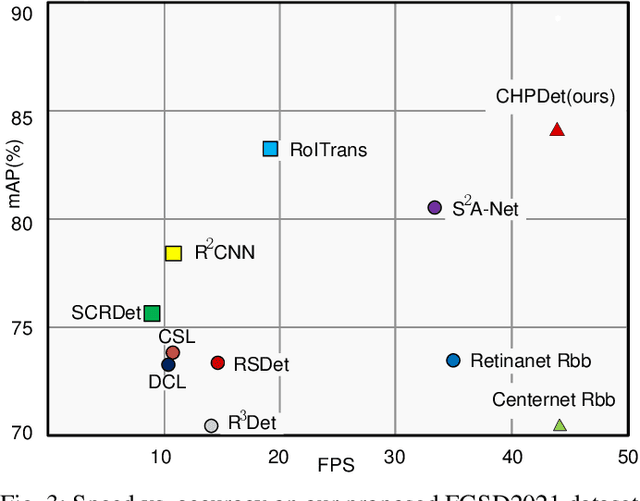

Ship detection in remote sensing images plays a crucial role in various applications and has drawn increasing attention in recent years. However, existing multi-oriented ship detection methods are generally developed on a set of predefined rotated anchor boxes. These predefined boxes not only lead to inaccurate angle predictions but also introduce extra hyper-parameters and high computational cost. Moreover, the prior knowledge of ship size has not been fully exploited by existing methods, which hinders the improvement of their detection accuracy. Aiming at solving the above issues, in this paper, we propose a \emph{center-head point extraction based detector} (named CHPDet) to achieve arbitrary-oriented ship detection in remote sensing images. Our CHPDet formulates arbitrary-oriented ships as rotated boxes with head points which are used to determine the direction. The orientation-invariant model (OIM) is used to produce orientation-invariant feature maps. Keypoint estimation is performed to find the center of ships. Then, the size and head point of the ships are regressed. Finally, we use the target size as prior to finetune the results. Moreover, we introduce a new dataset for multi-class arbitrary-oriented ship detection in remote sensing images at a fixed ground sample distance (GSD) which is named FGSD2021. Experimental results on two ship detection datasets (i.e., FGSD2021 and HRSC2016) demonstrate that our CHPDet achieves state-of-the-art performance and can well distinguish between bow and stern. The code and dataset will be made publicly available.
Data-Driven Multi-step Demand Prediction for Ride-hailing Services Using Convolutional Neural Network
Nov 08, 2019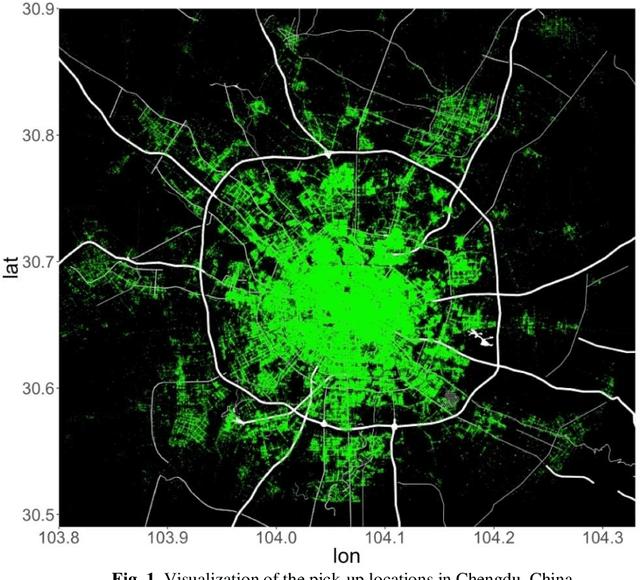

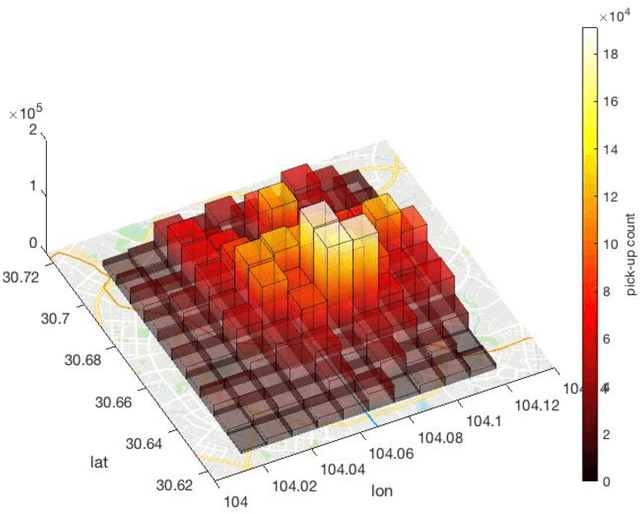
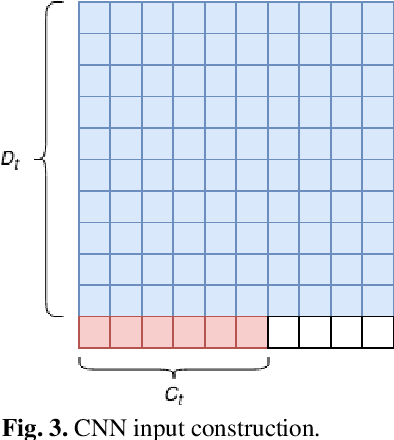
Ride-hailing services are growing rapidly and becoming one of the most disruptive technologies in the transportation realm. Accurate prediction of ride-hailing trip demand not only enables cities to better understand people's activity patterns, but also helps ride-hailing companies and drivers make informed decisions to reduce deadheading vehicle miles traveled, traffic congestion, and energy consumption. In this study, a convolutional neural network (CNN)-based deep learning model is proposed for multi-step ride-hailing demand prediction using the trip request data in Chengdu, China, offered by DiDi Chuxing. The CNN model is capable of accurately predicting the ride-hailing pick-up demand at each 1-km by 1-km zone in the city of Chengdu for every 10 minutes. Compared with another deep learning model based on long short-term memory, the CNN model is 30% faster for the training and predicting process. The proposed model can also be easily extended to make multi-step predictions, which would benefit the on-demand shared autonomous vehicles applications and fleet operators in terms of supply-demand rebalancing. The prediction error attenuation analysis shows that the accuracy stays acceptable as the model predicts more steps.