 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvolutional Neural Network-Based Image Representation for Visual Loop Closure Detection
Paper and Code
Apr 20, 2015
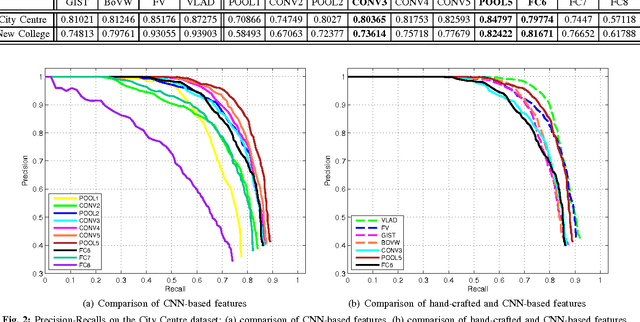
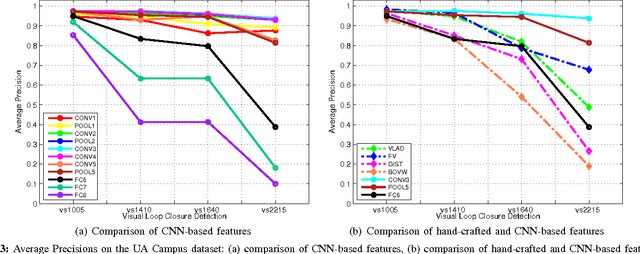

Deep convolutional neural networks (CNN) have recently been shown in many computer vision and pattern recog- nition applications to outperform by a significant margin state- of-the-art solutions that use traditional hand-crafted features. However, this impressive performance is yet to be fully exploited in robotics. In this paper, we focus one specific problem that can benefit from the recent development of the CNN technology, i.e., we focus on using a pre-trained CNN model as a method of generating an image representation appropriate for visual loop closure detection in SLAM (simultaneous localization and mapping). We perform a comprehensive evaluation of the outputs at the intermediate layers of a CNN as image descriptors, in comparison with state-of-the-art image descriptors, in terms of their ability to match images for detecting loop closures. The main conclusions of our study include: (a) CNN-based image representations perform comparably to state-of-the-art hand- crafted competitors in environments without significant lighting change, (b) they outperform state-of-the-art competitors when lighting changes significantly, and (c) they are also significantly faster to extract than the state-of-the-art hand-crafted features even on a conventional CPU and are two orders of magnitude faster on an entry-level GPU.