 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Close Look At World Model Recovery In Supervised Fine-Tuned LLM Planners
Jun 02, 2026Supervised fine-tuning (SFT) improves end-to-end classical planning in large language models (LLMs), but do these models also learn to represent and reason about the planning problems they are solving? Due to the relative complexity of classical planning problems and the challenge that end-to-end plan generation poses for LLMs, it has been difficult to explore this question. In our work, we devise and perform a series of interpretability experiments that holistically interrogate world model recovery by examining both internal representations and generative capabilities of fine-tuned LLMs. We find that: a) Supervised fine-tuning on valid action sequences enables LLMs to linearly encode action validity and some state predicates. b) Models that struggle to use output probabilities for classifying action validity may still learn internal representations that separate valid from invalid actions. c) Broader state space coverage during fine-tuning, such as from random walk data, yields more accurate recovery of the underlying world model. In summary, this work contributes a recipe for applying interpretability techniques to planning LLMs and generates insights that shed light on open questions about how knowledge is represented in LLMs.
Three Pathways to Neurosymbolic Reinforcement Learning with Interpretable Model and Policy Networks
Feb 07, 2024



Neurosymbolic AI combines the interpretability, parsimony, and explicit reasoning of classical symbolic approaches with the statistical learning of data-driven neural approaches. Models and policies that are simultaneously differentiable and interpretable may be key enablers of this marriage. This paper demonstrates three pathways to implementing such models and policies in a real-world reinforcement learning setting. Specifically, we study a broad class of neural networks that build interpretable semantics directly into their architecture. We reveal and highlight both the potential and the essential difficulties of combining logic, simulation, and learning. One lesson is that learning benefits from continuity and differentiability, but classical logic is discrete and non-differentiable. The relaxation to real-valued, differentiable representations presents a trade-off; the more learnable, the less interpretable. Another lesson is that using logic in the context of a numerical simulation involves a non-trivial mapping from raw (e.g., real-valued time series) simulation data to logical predicates. Some open questions this note exposes include: What are the limits of rule-based controllers, and how learnable are they? Do the differentiable interpretable approaches discussed here scale to large, complex, uncertain systems? Can we truly achieve interpretability? We highlight these and other themes across the three approaches.
BuildingsBench: A Large-Scale Dataset of 900K Buildings and Benchmark for Short-Term Load Forecasting
Jun 30, 2023Short-term forecasting of residential and commercial building energy consumption is widely used in power systems and continues to grow in importance. Data-driven short-term load forecasting (STLF), although promising, has suffered from a lack of open, large-scale datasets with high building diversity. This has hindered exploring the pretrain-then-finetune paradigm for STLF. To help address this, we present BuildingsBench, which consists of 1) Buildings-900K, a large-scale dataset of 900K simulated buildings representing the U.S. building stock, and 2) an evaluation platform with over 1,900 real residential and commercial buildings from 7 open datasets. BuildingsBench benchmarks two under-explored tasks: zero-shot STLF, where a pretrained model is evaluated on unseen buildings without fine-tuning, and transfer learning, where a pretrained model is fine-tuned on a target building. The main finding of our benchmark analysis is that synthetically pretrained models generalize surprisingly well to real commercial buildings. An exploration of the effect of increasing dataset size and diversity on zero-shot commercial building performance reveals a power-law with diminishing returns. We also show that fine-tuning pretrained models on real commercial and residential buildings improves performance for a majority of target buildings. We hope that BuildingsBench encourages and facilitates future research on generalizable STLF. All datasets and code can be accessed from \url{https://github.com/NREL/BuildingsBench}.
A Comparison of Model-Free and Model Predictive Control for Price Responsive Water Heaters
Nov 08, 2021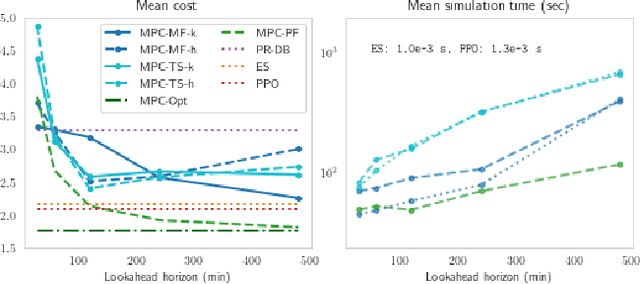
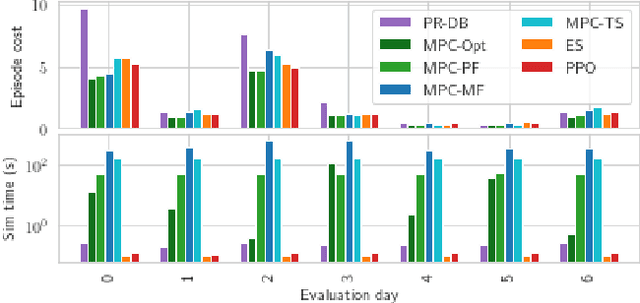
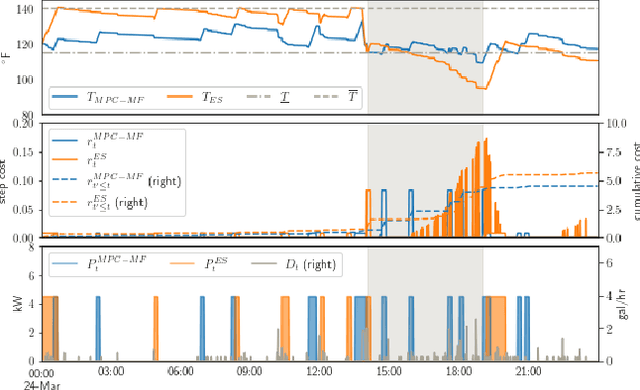
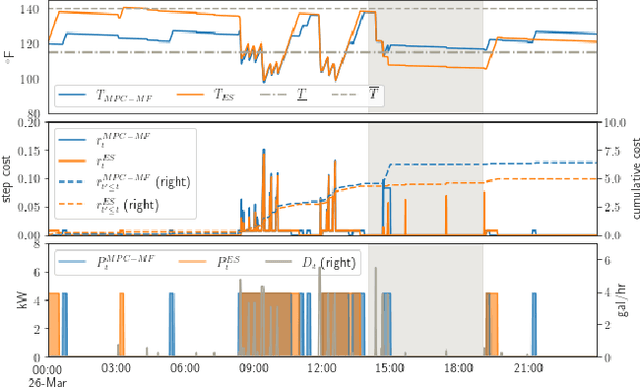
We present a careful comparison of two model-free control algorithms, Evolution Strategies (ES) and Proximal Policy Optimization (PPO), with receding horizon model predictive control (MPC) for operating simulated, price responsive water heaters. Four MPC variants are considered: a one-shot controller with perfect forecasting yielding optimal control; a limited-horizon controller with perfect forecasting; a mean forecasting-based controller; and a two-stage stochastic programming controller using historical scenarios. In all cases, the MPC model for water temperature and electricity price are exact; only water demand is uncertain. For comparison, both ES and PPO learn neural network-based policies by directly interacting with the simulated environment under the same scenarios used by MPC. All methods are then evaluated on a separate one-week continuation of the demand time series. We demonstrate that optimal control for this problem is challenging, requiring more than 8-hour lookahead for MPC with perfect forecasting to attain the minimum cost. Despite this challenge, both ES and PPO learn good general purpose policies that outperform mean forecast and two-stage stochastic MPC controllers in terms of average cost and are more than two orders of magnitude faster at computing actions. We show that ES in particular can leverage parallelism to learn a policy in under 90 seconds using 1150 CPU cores.
* All authors are with the Computational Science Center at the National Renewable Energy Laboratory. Corresponding author: David Biagioni (dave.biagioni@nrel.gov)
Decentralized Cooperative Lane Changing at Freeway Weaving Areas Using Multi-Agent Deep Reinforcement Learning
Oct 05, 2021
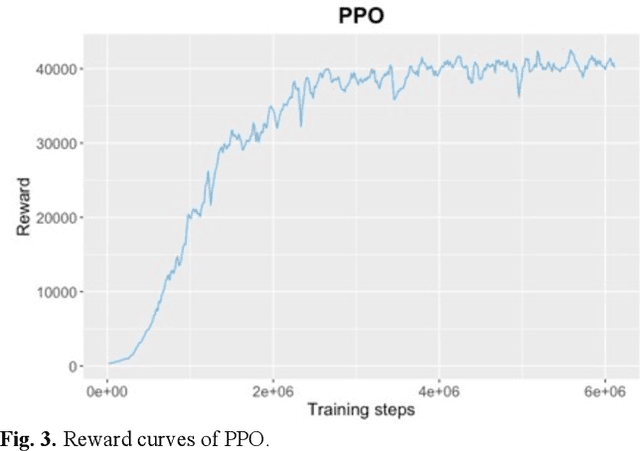
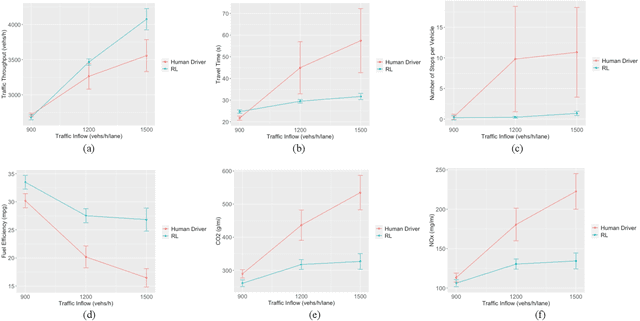
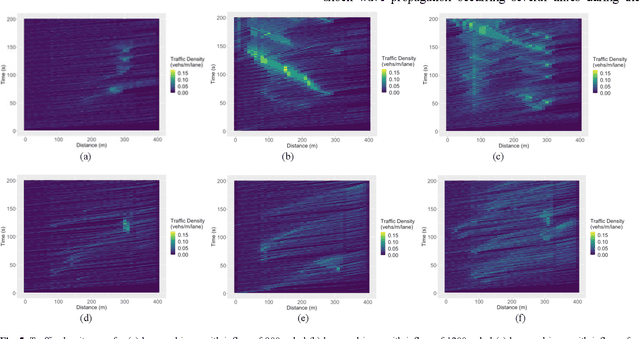
Frequent lane changes during congestion at freeway bottlenecks such as merge and weaving areas further reduce roadway capacity. The emergence of deep reinforcement learning (RL) and connected and automated vehicle technology provides a possible solution to improve mobility and energy efficiency at freeway bottlenecks through cooperative lane changing. Deep RL is a collection of machine-learning methods that enables an agent to improve its performance by learning from the environment. In this study, a decentralized cooperative lane-changing controller was developed using proximal policy optimization by adopting a multi-agent deep RL paradigm. In the decentralized control strategy, policy learning and action reward are evaluated locally, with each agent (vehicle) getting access to global state information. Multi-agent deep RL requires lower computational resources and is more scalable than single-agent deep RL, making it a powerful tool for time-sensitive applications such as cooperative lane changing. The results of this study show that cooperative lane changing enabled by multi-agent deep RL yields superior performance to human drivers in term of traffic throughput, vehicle speed, number of stops per vehicle, vehicle fuel efficiency, and emissions. The trained RL policy is transferable and can be generalized to uncongested, moderately congested, and extremely congested traffic conditions.
A Modular and Transferable Reinforcement Learning Framework for the Fleet Rebalancing Problem
May 27, 2021
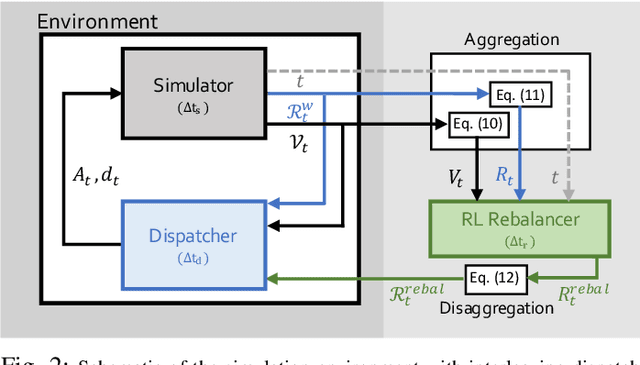
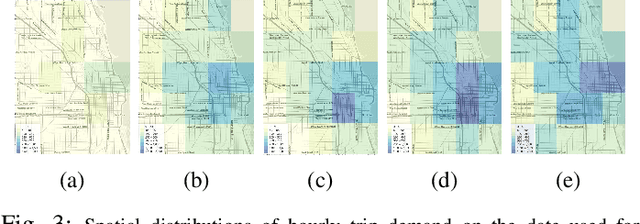
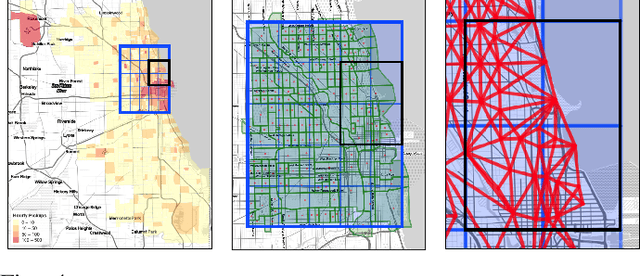
Mobility on demand (MoD) systems show great promise in realizing flexible and efficient urban transportation. However, significant technical challenges arise from operational decision making associated with MoD vehicle dispatch and fleet rebalancing. For this reason, operators tend to employ simplified algorithms that have been demonstrated to work well in a particular setting. To help bridge the gap between novel and existing methods, we propose a modular framework for fleet rebalancing based on model-free reinforcement learning (RL) that can leverage an existing dispatch method to minimize system cost. In particular, by treating dispatch as part of the environment dynamics, a centralized agent can learn to intermittently direct the dispatcher to reposition free vehicles and mitigate against fleet imbalance. We formulate RL state and action spaces as distributions over a grid partitioning of the operating area, making the framework scalable and avoiding the complexities associated with multiagent RL. Numerical experiments, using real-world trip and network data, demonstrate that this approach has several distinct advantages over baseline methods including: improved system cost; high degree of adaptability to the selected dispatch method; and the ability to perform scale-invariant transfer learning between problem instances with similar vehicle and request distributions.
K-spin Hamiltonian for quantum-resolvable Markov decision processes
Apr 13, 2020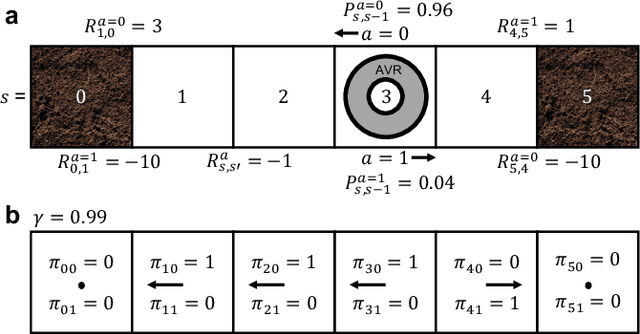
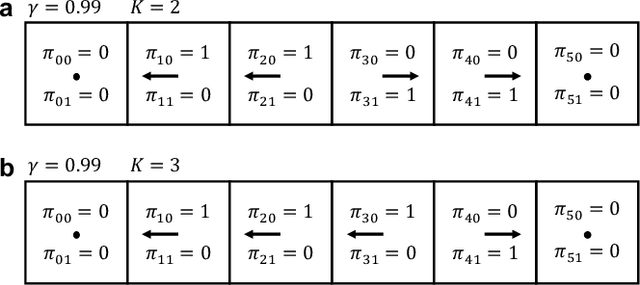
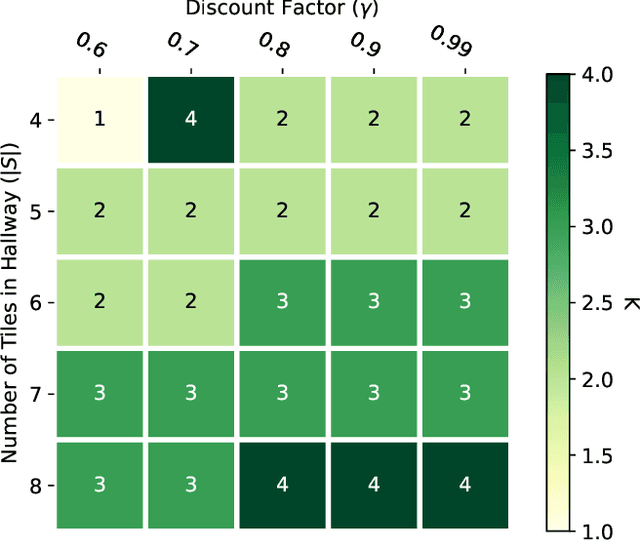
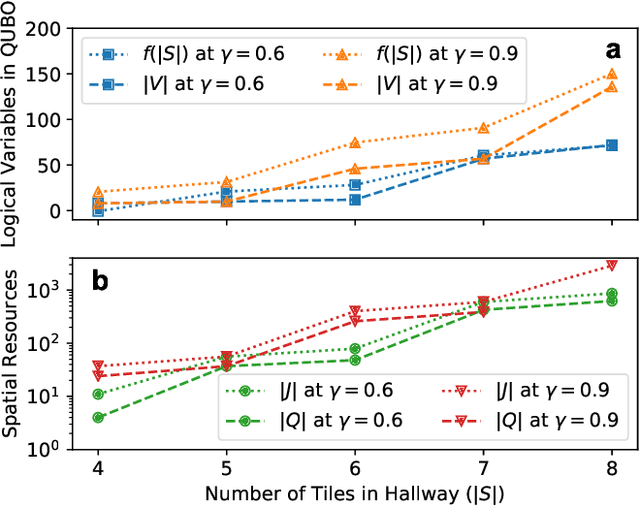
The Markov decision process is the mathematical formalization underlying the modern field of reinforcement learning when transition and reward functions are unknown. We derive a pseudo-Boolean cost function that is equivalent to a K-spin Hamiltonian representation of the discrete, finite, discounted Markov decision process with infinite horizon. This K-spin Hamiltonian furnishes a starting point from which to solve for an optimal policy using heuristic quantum algorithms such as adiabatic quantum annealing and the quantum approximate optimization algorithm on near-term quantum hardware. In proving that the variational minimization of our Hamiltonian is equivalent to the Bellman optimality condition we establish an interesting analogy with classical field theory. Along with proof-of-concept calculations to corroborate our formulation by simulated and quantum annealing against classical Q-Learning, we analyze the scaling of physical resources required to solve our Hamiltonian on quantum hardware.
Learning-Accelerated ADMM for Distributed Optimal Power Flow
Nov 08, 2019
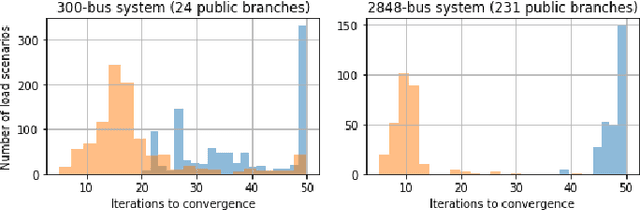

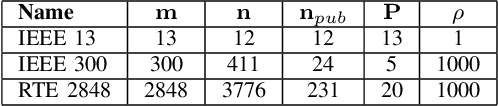
We propose a novel data-driven method to accelerate the convergence of Alternating Direction Method of Multipliers (ADMM) for solving distributed DC optimal power flow (DC-OPF) where lines are shared between independent network partitions. Using previous observations of ADMM trajectories for a given system under varying load, the method trains a recurrent neural network (RNN) to predict the converged values of dual and consensus variables. Given a new realization of system load, a small number of initial ADMM iterations is taken as input to infer the converged values and directly inject them into the iteration. For this purpose, we utilize a recently proposed RNN architecture called antisymmetric RNN (aRNN) that avoids vanishing and exploding gradients via network weights designed to have the spectral properties of a convergent numerical integration scheme. We demonstrate empirically that the online injection of these values into the ADMM iteration accelerates convergence by a factor of 2-50x for partitioned 13-, 300- and 2848-bus test systems under differing load scenarios. The proposed method has several advantages: it can be easily integrated around an existing software framework, requiring no changes to underlying physical models; it maintains the security of private decision variables inherent in consensus ADMM; inference is fast and so may be used in online settings; historical data is leveraged to improve performance instead of being discarded or ignored. While we focus on the ADMM formulation of distributed DC-OPF in this paper, the ideas presented are naturally extended to other iterative optimization schemes.