 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePowerGridworld: A Framework for Multi-Agent Reinforcement Learning in Power Systems
Nov 10, 2021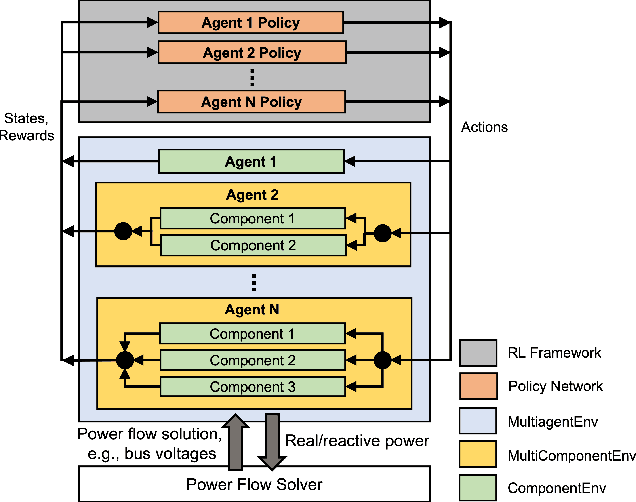
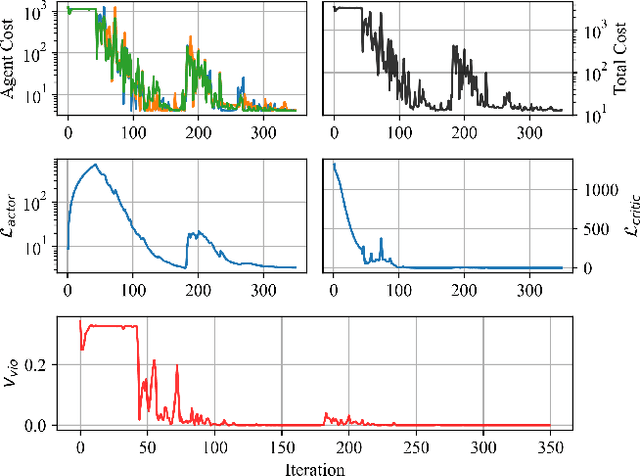
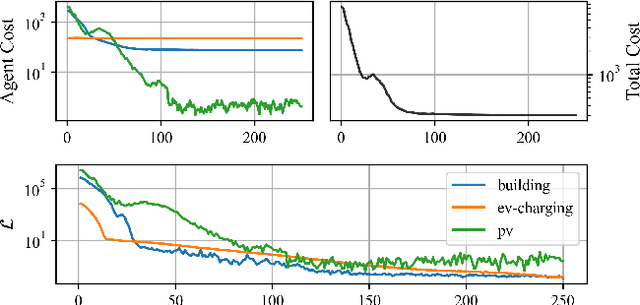
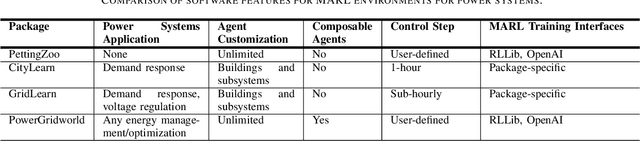
We present the PowerGridworld software package to provide users with a lightweight, modular, and customizable framework for creating power-systems-focused, multi-agent Gym environments that readily integrate with existing training frameworks for reinforcement learning (RL). Although many frameworks exist for training multi-agent RL (MARL) policies, none can rapidly prototype and develop the environments themselves, especially in the context of heterogeneous (composite, multi-device) power systems where power flow solutions are required to define grid-level variables and costs. PowerGridworld is an open-source software package that helps to fill this gap. To highlight PowerGridworld's key features, we present two case studies and demonstrate learning MARL policies using both OpenAI's multi-agent deep deterministic policy gradient (MADDPG) and RLLib's proximal policy optimization (PPO) algorithms. In both cases, at least some subset of agents incorporates elements of the power flow solution at each time step as part of their reward (negative cost) structures.
Learning-Accelerated ADMM for Distributed Optimal Power Flow
Nov 08, 2019
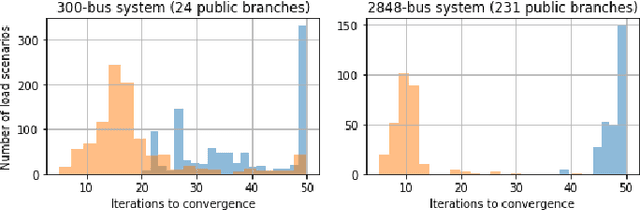

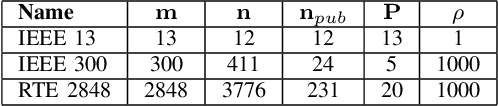
We propose a novel data-driven method to accelerate the convergence of Alternating Direction Method of Multipliers (ADMM) for solving distributed DC optimal power flow (DC-OPF) where lines are shared between independent network partitions. Using previous observations of ADMM trajectories for a given system under varying load, the method trains a recurrent neural network (RNN) to predict the converged values of dual and consensus variables. Given a new realization of system load, a small number of initial ADMM iterations is taken as input to infer the converged values and directly inject them into the iteration. For this purpose, we utilize a recently proposed RNN architecture called antisymmetric RNN (aRNN) that avoids vanishing and exploding gradients via network weights designed to have the spectral properties of a convergent numerical integration scheme. We demonstrate empirically that the online injection of these values into the ADMM iteration accelerates convergence by a factor of 2-50x for partitioned 13-, 300- and 2848-bus test systems under differing load scenarios. The proposed method has several advantages: it can be easily integrated around an existing software framework, requiring no changes to underlying physical models; it maintains the security of private decision variables inherent in consensus ADMM; inference is fast and so may be used in online settings; historical data is leveraged to improve performance instead of being discarded or ignored. While we focus on the ADMM formulation of distributed DC-OPF in this paper, the ideas presented are naturally extended to other iterative optimization schemes.