 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Stationary Policy Learning for Multi-Timescale Multi-Agent Reinforcement Learning
Jul 17, 2023
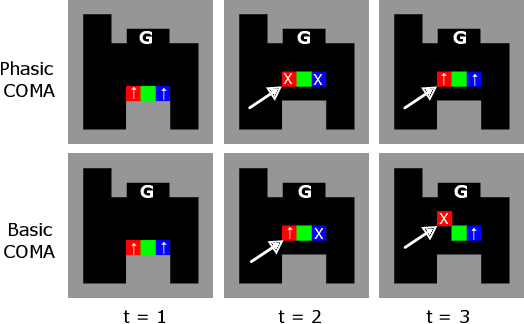

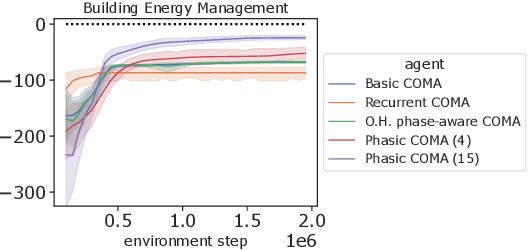
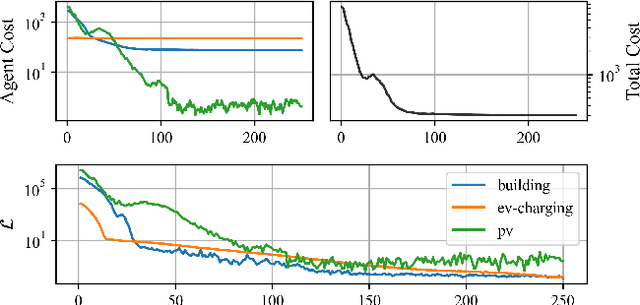
In multi-timescale multi-agent reinforcement learning (MARL), agents interact across different timescales. In general, policies for time-dependent behaviors, such as those induced by multiple timescales, are non-stationary. Learning non-stationary policies is challenging and typically requires sophisticated or inefficient algorithms. Motivated by the prevalence of this control problem in real-world complex systems, we introduce a simple framework for learning non-stationary policies for multi-timescale MARL. Our approach uses available information about agent timescales to define a periodic time encoding. In detail, we theoretically demonstrate that the effects of non-stationarity introduced by multiple timescales can be learned by a periodic multi-agent policy. To learn such policies, we propose a policy gradient algorithm that parameterizes the actor and critic with phase-functioned neural networks, which provide an inductive bias for periodicity. The framework's ability to effectively learn multi-timescale policies is validated on a gridworld and building energy management environment.
Plug & Play Directed Evolution of Proteins with Gradient-based Discrete MCMC
Dec 20, 2022A long-standing goal of machine-learning-based protein engineering is to accelerate the discovery of novel mutations that improve the function of a known protein. We introduce a sampling framework for evolving proteins in silico that supports mixing and matching a variety of unsupervised models, such as protein language models, and supervised models that predict protein function from sequence. By composing these models, we aim to improve our ability to evaluate unseen mutations and constrain search to regions of sequence space likely to contain functional proteins. Our framework achieves this without any model fine-tuning or re-training by constructing a product of experts distribution directly in discrete protein space. Instead of resorting to brute force search or random sampling, which is typical of classic directed evolution, we introduce a fast MCMC sampler that uses gradients to propose promising mutations. We conduct in silico directed evolution experiments on wide fitness landscapes and across a range of different pre-trained unsupervised models, including a 650M parameter protein language model. Our results demonstrate an ability to efficiently discover variants with high evolutionary likelihood as well as estimated activity multiple mutations away from a wild type protein, suggesting our sampler provides a practical and effective new paradigm for machine-learning-based protein engineering.
PowerGridworld: A Framework for Multi-Agent Reinforcement Learning in Power Systems
Nov 10, 2021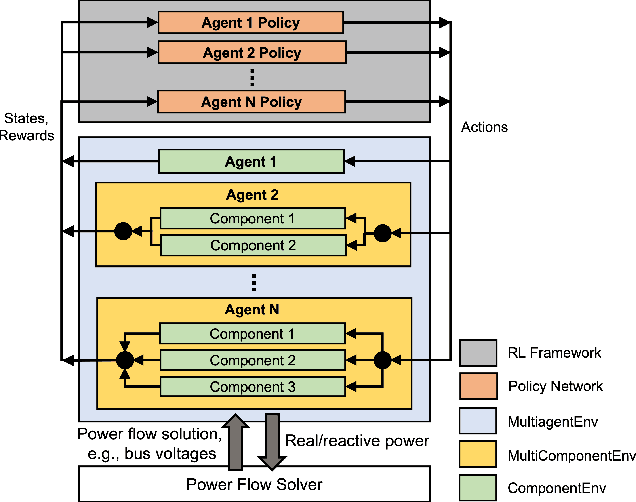
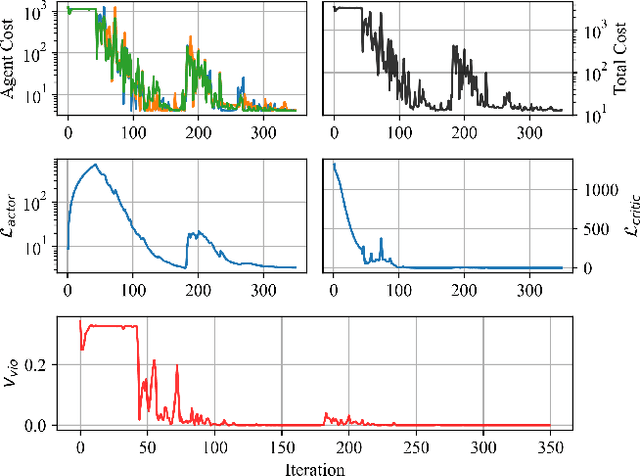
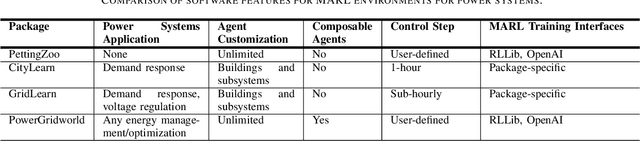
We present the PowerGridworld software package to provide users with a lightweight, modular, and customizable framework for creating power-systems-focused, multi-agent Gym environments that readily integrate with existing training frameworks for reinforcement learning (RL). Although many frameworks exist for training multi-agent RL (MARL) policies, none can rapidly prototype and develop the environments themselves, especially in the context of heterogeneous (composite, multi-device) power systems where power flow solutions are required to define grid-level variables and costs. PowerGridworld is an open-source software package that helps to fill this gap. To highlight PowerGridworld's key features, we present two case studies and demonstrate learning MARL policies using both OpenAI's multi-agent deep deterministic policy gradient (MADDPG) and RLLib's proximal policy optimization (PPO) algorithms. In both cases, at least some subset of agents incorporates elements of the power flow solution at each time step as part of their reward (negative cost) structures.
A Modular and Transferable Reinforcement Learning Framework for the Fleet Rebalancing Problem
May 27, 2021
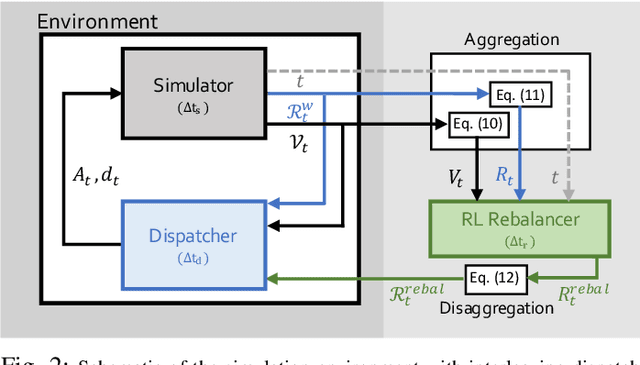
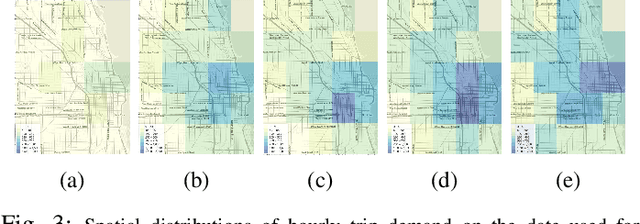
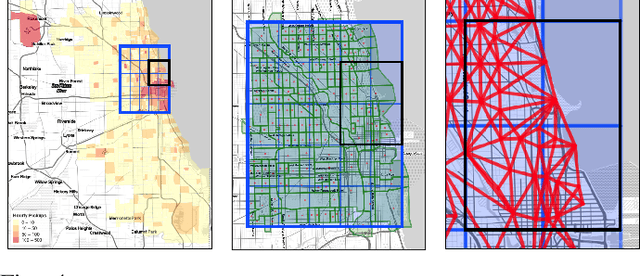
Mobility on demand (MoD) systems show great promise in realizing flexible and efficient urban transportation. However, significant technical challenges arise from operational decision making associated with MoD vehicle dispatch and fleet rebalancing. For this reason, operators tend to employ simplified algorithms that have been demonstrated to work well in a particular setting. To help bridge the gap between novel and existing methods, we propose a modular framework for fleet rebalancing based on model-free reinforcement learning (RL) that can leverage an existing dispatch method to minimize system cost. In particular, by treating dispatch as part of the environment dynamics, a centralized agent can learn to intermittently direct the dispatcher to reposition free vehicles and mitigate against fleet imbalance. We formulate RL state and action spaces as distributions over a grid partitioning of the operating area, making the framework scalable and avoiding the complexities associated with multiagent RL. Numerical experiments, using real-world trip and network data, demonstrate that this approach has several distinct advantages over baseline methods including: improved system cost; high degree of adaptability to the selected dispatch method; and the ability to perform scale-invariant transfer learning between problem instances with similar vehicle and request distributions.