 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Improved Empirical Fisher Approximation for Natural Gradient Descent
Jun 10, 2024Approximate Natural Gradient Descent (NGD) methods are an important family of optimisers for deep learning models, which use approximate Fisher information matrices to pre-condition gradients during training. The empirical Fisher (EF) method approximates the Fisher information matrix empirically by reusing the per-sample gradients collected during back-propagation. Despite its ease of implementation, the EF approximation has its theoretical and practical limitations. This paper first investigates the inversely-scaled projection issue of EF, which is shown to be a major cause of the poor empirical approximation quality. An improved empirical Fisher (iEF) method, motivated as a generalised NGD method from a loss reduction perspective, is proposed to address this issue, meanwhile retaining the practical convenience of EF. The exact iEF and EF methods are experimentally evaluated using practical deep learning setups, including widely-used setups for parameter-efficient fine-tuning of pre-trained models (T5-base with LoRA and Prompt-Tuning on GLUE tasks, and ViT with LoRA for CIFAR100). Optimisation experiments show that applying exact iEF as an optimiser provides strong convergence and generalisation. It achieves the best test performance and the lowest training loss for majority of the tasks, even when compared with well-tuned AdamW/Adafactor baselines. Additionally, under a novel empirical evaluation framework, the proposed iEF method shows consistently better approximation quality to the exact Natural Gradient updates than both EF and the more expensive sampled Fisher (SF). Further investigation also shows that the superior approximation quality of iEF is robust to damping across tasks and training stages. Improving existing approximate NGD optimisers with iEF is expected to lead to better convergence ability and stronger robustness to choice of damping.
Multi-Span Acoustic Modelling using Raw Waveform Signals
Jun 21, 2019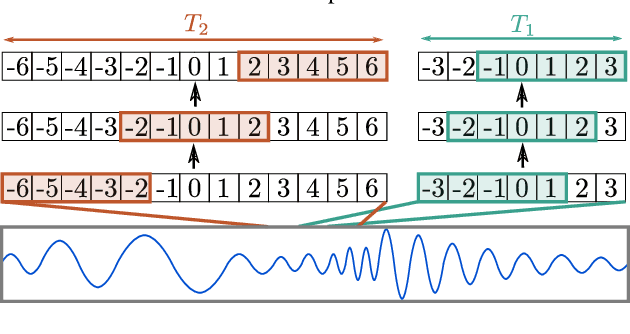

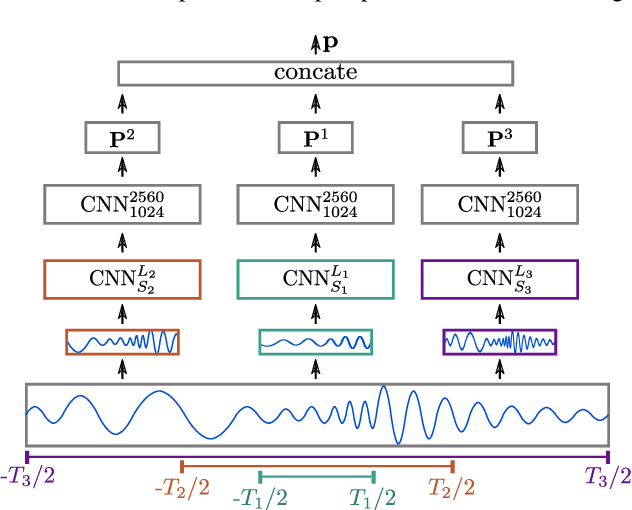
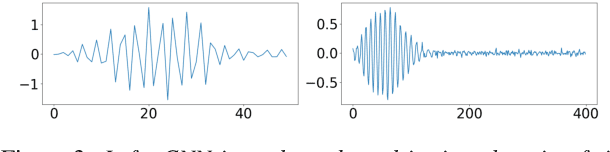
Traditional automatic speech recognition (ASR) systems often use an acoustic model (AM) built on handcrafted acoustic features, such as log Mel-filter bank (FBANK) values. Recent studies found that AMs with convolutional neural networks (CNNs) can directly use the raw waveform signal as input. Given sufficient training data, these AMs can yield a competitive word error rate (WER) to those built on FBANK features. This paper proposes a novel multi-span structure for acoustic modelling based on the raw waveform with multiple streams of CNN input layers, each processing a different span of the raw waveform signal. Evaluation on both the single channel CHiME4 and AMI data sets show that multi-span AMs give a lower WER than FBANK AMs by an average of about 5% (relative). Analysis of the trained multi-span model reveals that the CNNs can learn filters that are rather different to the log Mel filters. Furthermore, the paper shows that a widely used single span raw waveform AM can be improved by using a smaller CNN kernel size and increased stride to yield improved WERs.
Semi-tied Units for Efficient Gating in LSTM and Highway Networks
Jun 18, 2018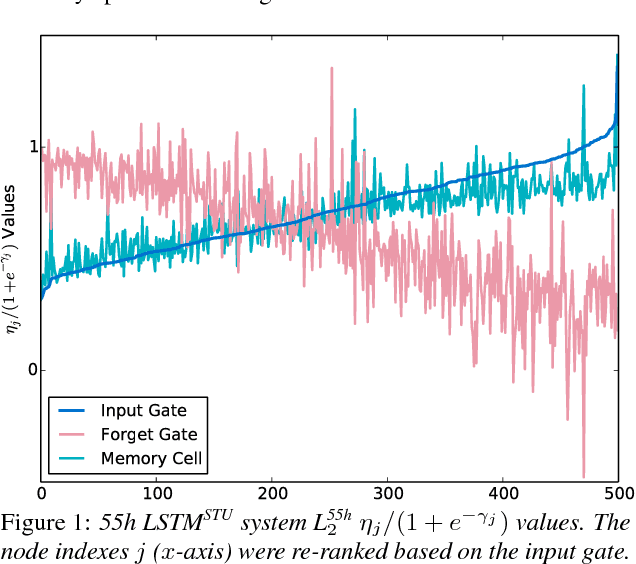

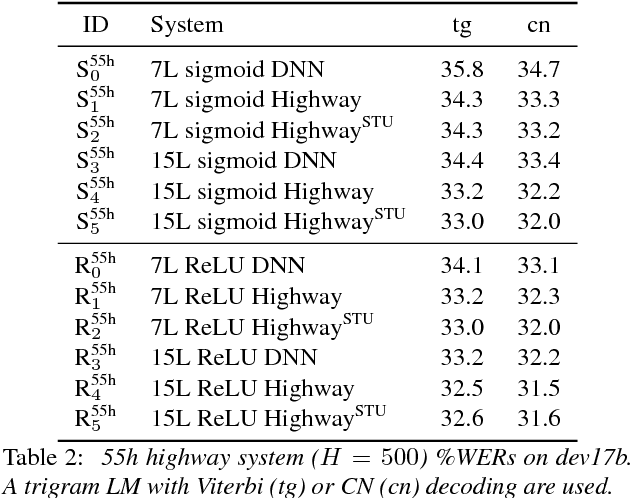
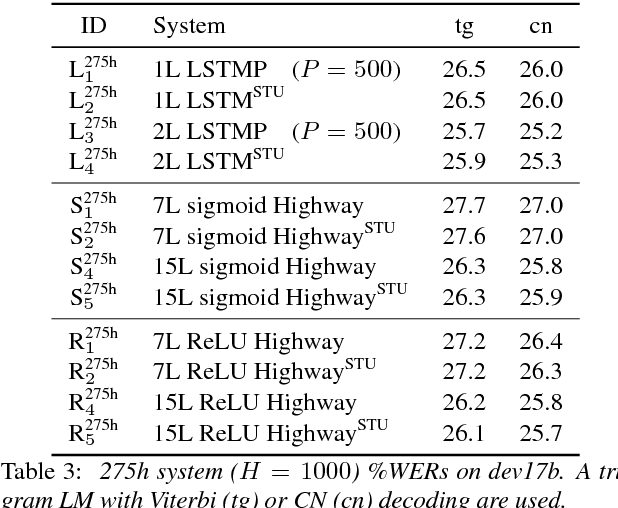
Gating is a key technique used for integrating information from multiple sources by long short-term memory (LSTM) models and has recently also been applied to other models such as the highway network. Although gating is powerful, it is rather expensive in terms of both computation and storage as each gating unit uses a separate full weight matrix. This issue can be severe since several gates can be used together in e.g. an LSTM cell. This paper proposes a semi-tied unit (STU) approach to solve this efficiency issue, which uses one shared weight matrix to replace those in all the units in the same layer. The approach is termed "semi-tied" since extra parameters are used to separately scale each of the shared output values. These extra scaling factors are associated with the network activation functions and result in the use of parameterised sigmoid, hyperbolic tangent, and rectified linear unit functions. Speech recognition experiments using British English multi-genre broadcast data showed that using STUs can reduce the calculation and storage cost by a factor of three for highway networks and four for LSTMs, while giving similar word error rates to the original models.
High Order Recurrent Neural Networks for Acoustic Modelling
Feb 22, 2018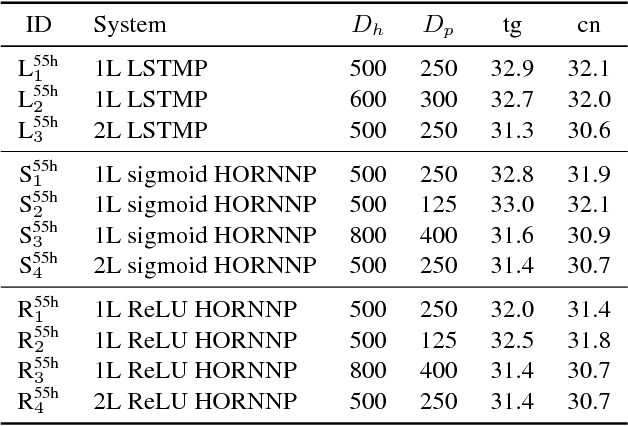

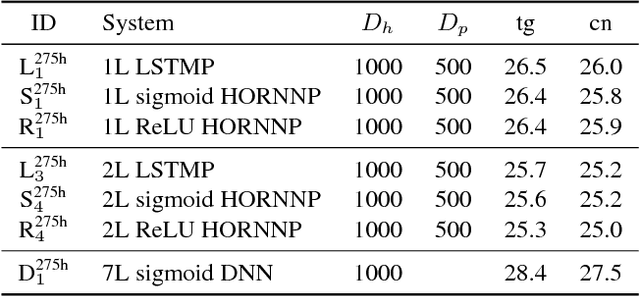
Vanishing long-term gradients are a major issue in training standard recurrent neural networks (RNNs), which can be alleviated by long short-term memory (LSTM) models with memory cells. However, the extra parameters associated with the memory cells mean an LSTM layer has four times as many parameters as an RNN with the same hidden vector size. This paper addresses the vanishing gradient problem using a high order RNN (HORNN) which has additional connections from multiple previous time steps. Speech recognition experiments using British English multi-genre broadcast (MGB3) data showed that the proposed HORNN architectures for rectified linear unit and sigmoid activation functions reduced word error rates (WER) by 4.2% and 6.3% over the corresponding RNNs, and gave similar WERs to a (projected) LSTM while using only 20%--50% of the recurrent layer parameters and computation.
Improved TDNNs using Deep Kernels and Frequency Dependent Grid-RNNs
Feb 20, 2018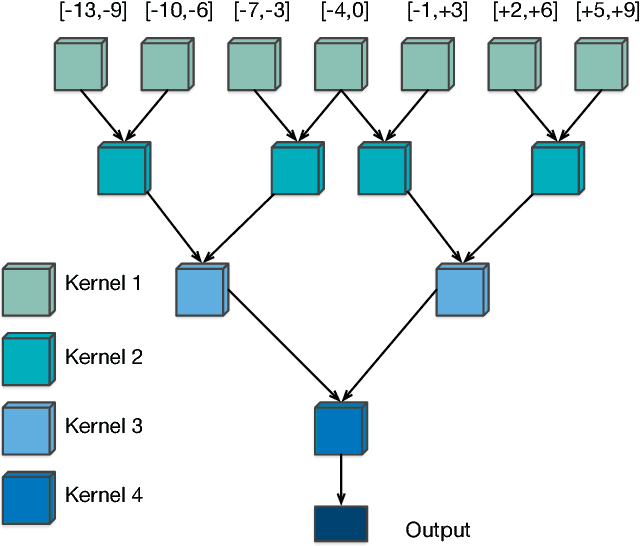
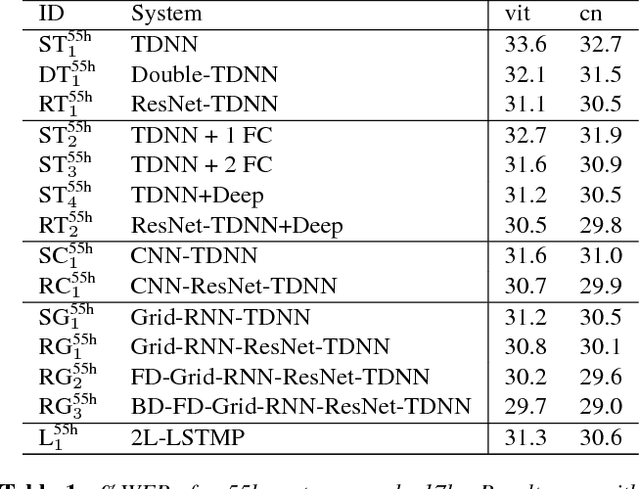


Time delay neural networks (TDNNs) are an effective acoustic model for large vocabulary speech recognition. The strength of the model can be attributed to its ability to effectively model long temporal contexts. However, current TDNN models are relatively shallow, which limits the modelling capability. This paper proposes a method of increasing the network depth by deepening the kernel used in the TDNN temporal convolutions. The best performing kernel consists of three fully connected layers with a residual (ResNet) connection from the output of the first to the output of the third. The addition of spectro-temporal processing as the input to the TDNN in the form of a convolutional neural network (CNN) and a newly designed Grid-RNN was investigated. The Grid-RNN strongly outperforms a CNN if different sets of parameters for different frequency bands are used and can be further enhanced by using a bi-directional Grid-RNN. Experiments using the multi-genre broadcast (MGB3) English data (275h) show that deep kernel TDNNs reduces the word error rate (WER) by 6% relative and when combined with the frequency dependent Grid-RNN gives a relative WER reduction of 9%.