 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Span Acoustic Modelling using Raw Waveform Signals
Paper and Code
Jun 21, 2019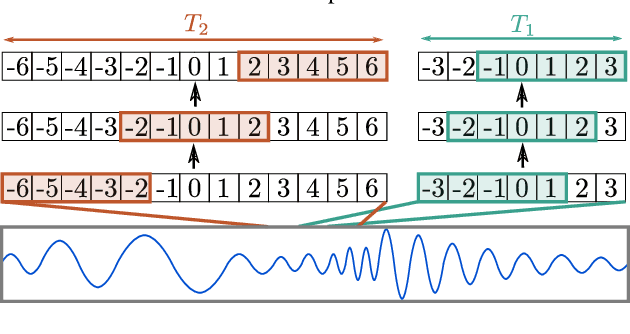

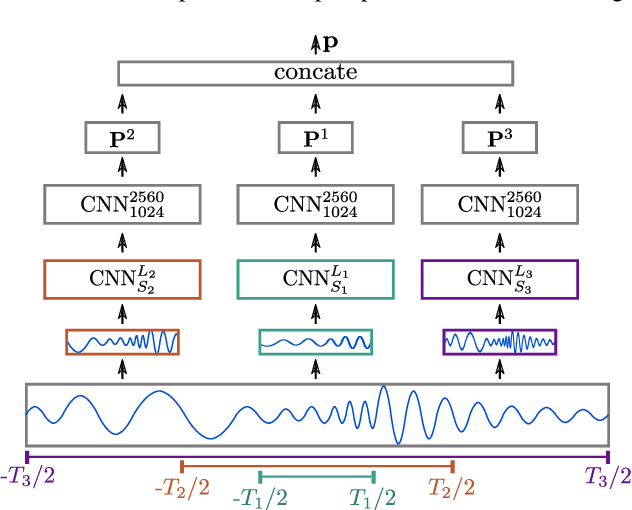
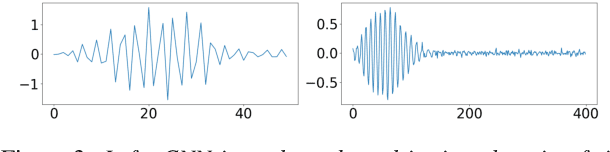
Traditional automatic speech recognition (ASR) systems often use an acoustic model (AM) built on handcrafted acoustic features, such as log Mel-filter bank (FBANK) values. Recent studies found that AMs with convolutional neural networks (CNNs) can directly use the raw waveform signal as input. Given sufficient training data, these AMs can yield a competitive word error rate (WER) to those built on FBANK features. This paper proposes a novel multi-span structure for acoustic modelling based on the raw waveform with multiple streams of CNN input layers, each processing a different span of the raw waveform signal. Evaluation on both the single channel CHiME4 and AMI data sets show that multi-span AMs give a lower WER than FBANK AMs by an average of about 5% (relative). Analysis of the trained multi-span model reveals that the CNNs can learn filters that are rather different to the log Mel filters. Furthermore, the paper shows that a widely used single span raw waveform AM can be improved by using a smaller CNN kernel size and increased stride to yield improved WERs.