 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTalos: Optimizing Top-$K$ Accuracy in Recommender Systems
Jan 27, 2026Recommender systems (RS) aim to retrieve a small set of items that best match individual user preferences. Naturally, RS place primary emphasis on the quality of the Top-$K$ results rather than performance across the entire item set. However, estimating Top-$K$ accuracy (e.g., Precision@$K$, Recall@$K$) requires determining the ranking positions of items, which imposes substantial computational overhead and poses significant challenges for optimization. In addition, RS often suffer from distribution shifts due to evolving user preferences or data biases, further complicating the task. To address these issues, we propose Talos, a loss function that is specifically designed to optimize the Talos recommendation accuracy. Talos leverages a quantile technique that replaces the complex ranking-dependent operations into simpler comparisons between predicted scores and learned score thresholds. We further develop a sampling-based regression algorithm for efficient and accurate threshold estimation, and introduce a constraint term to maintain optimization stability by preventing score inflation. Additionally, we incorporate a tailored surrogate function to address discontinuity and enhance robustness against distribution shifts. Comprehensive theoretical analyzes and empirical experiments are conducted to demonstrate the effectiveness, efficiency, convergence, and distributional robustness of Talos. The code is available at https://github.com/cynthia-shengjia/WWW-2026-Talos.
Bridging the Gap: Self-Optimized Fine-Tuning for LLM-based Recommender Systems
May 27, 2025Recent years have witnessed extensive exploration of Large Language Models (LLMs) on the field of Recommender Systems (RS). There are currently two commonly used strategies to enable LLMs to have recommendation capabilities: 1) The "Guidance-Only" strategy uses in-context learning to exploit and amplify the inherent semantic understanding and item recommendation capabilities of LLMs; 2) The "Tuning-Only" strategy uses supervised fine-tuning (SFT) to fine-tune LLMs with the aim of fitting them to real recommendation data. However, neither of these strategies can effectively bridge the gap between the knowledge space of LLMs and recommendation, and their performance do not meet our expectations. To better enable LLMs to learn recommendation knowledge, we combine the advantages of the above two strategies and proposed a novel "Guidance+Tuning" method called Self-Optimized Fine-Tuning (SOFT), which adopts the idea of curriculum learning. It first employs self-distillation to construct an auxiliary easy-to-learn but meaningful dataset from a fine-tuned LLM. Then it further utilizes a self-adaptive curriculum scheduler to enable LLMs to gradually learn from simpler data (self-distilled data) to more challenging data (real RS data). Extensive experiments demonstrate that SOFT significantly enhances the recommendation accuracy (37.59\% on average) of LLM-based methods. The code is available via https://anonymous.4open.science/r/Self-Optimized-Fine-Tuning-264E
Field Matters: A lightweight LLM-enhanced Method for CTR Prediction
May 20, 2025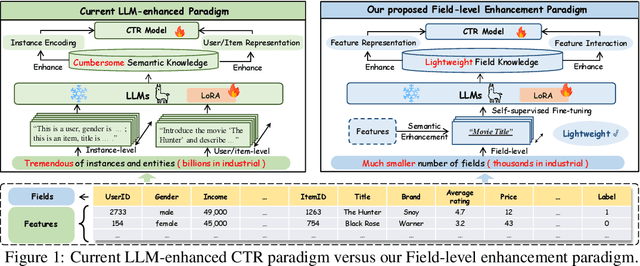
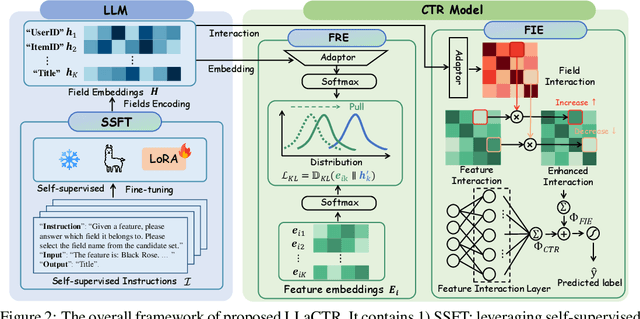
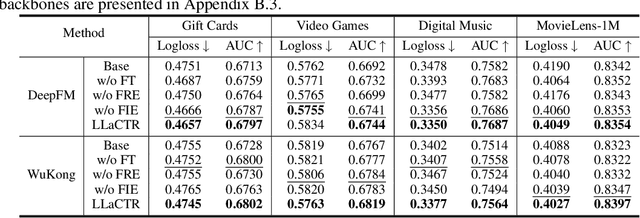

Click-through rate (CTR) prediction is a fundamental task in modern recommender systems. In recent years, the integration of large language models (LLMs) has been shown to effectively enhance the performance of traditional CTR methods. However, existing LLM-enhanced methods often require extensive processing of detailed textual descriptions for large-scale instances or user/item entities, leading to substantial computational overhead. To address this challenge, this work introduces LLaCTR, a novel and lightweight LLM-enhanced CTR method that employs a field-level enhancement paradigm. Specifically, LLaCTR first utilizes LLMs to distill crucial and lightweight semantic knowledge from small-scale feature fields through self-supervised field-feature fine-tuning. Subsequently, it leverages this field-level semantic knowledge to enhance both feature representation and feature interactions. In our experiments, we integrate LLaCTR with six representative CTR models across four datasets, demonstrating its superior performance in terms of both effectiveness and efficiency compared to existing LLM-enhanced methods. Our code is available at https://anonymous.4open.science/r/LLaCTR-EC46.
MSL: Not All Tokens Are What You Need for Tuning LLM as a Recommender
Apr 05, 2025Large language models (LLMs), known for their comprehension capabilities and extensive knowledge, have been increasingly applied to recommendation systems (RS). Given the fundamental gap between the mechanism of LLMs and the requirement of RS, researchers have focused on fine-tuning LLMs with recommendation-specific data to enhance their performance. Language Modeling Loss (LML), originally designed for language generation tasks, is commonly adopted. However, we identify two critical limitations of LML: 1) it exhibits significant divergence from the recommendation objective; 2) it erroneously treats all fictitious item descriptions as negative samples, introducing misleading training signals. To address these limitations, we propose a novel Masked Softmax Loss (MSL) tailored for fine-tuning LLMs on recommendation. MSL improves LML by identifying and masking invalid tokens that could lead to fictitious item descriptions during loss computation. This strategy can effectively avoid the interference from erroneous negative signals and ensure well alignment with the recommendation objective supported by theoretical guarantees. During implementation, we identify a potential challenge related to gradient vanishing of MSL. To overcome this, we further introduce the temperature coefficient and propose an Adaptive Temperature Strategy (ATS) that adaptively adjusts the temperature without requiring extensive hyperparameter tuning. Extensive experiments conducted on four public datasets further validate the effectiveness of MSL, achieving an average improvement of 42.24% in NDCG@10. The code is available at https://github.com/WANGBohaO-jpg/MSL.