 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatCode: Rotary-based Unified Encoding Framework for Efficient Spatiotemporal Vector Retrieval
Jan 14, 2026Spatiotemporal vector retrieval has emerged as a critical paradigm in modern information retrieval, enabling efficient access to massive, heterogeneous data that evolve over both time and space. However, existing spatiotemporal retrieval methods are often extensions of conventional vector search systems that rely on external filters or specialized indices to incorporate temporal and spatial constraints, leading to inefficiency, architectural complexity, and limited flexibility in handling heterogeneous modalities. To overcome these challenges, we present a unified spatiotemporal vector retrieval framework that integrates temporal, spatial, and semantic cues within a coherent similarity space while maintaining scalability and adaptability to continuous data streams. Specifically, we propose (1) a Rotary-based Unified Encoding Method that embeds time and location into rotational position vectors for consistent spatiotemporal representation; (2) a Circular Incremental Update Mechanism that supports efficient sliding-window updates without global re-encoding or index reconstruction; and (3) a Weighted Interest-based Retrieval Algorithm that adaptively balances modality weights for context-aware and personalized retrieval. Extensive experiments across multiple real-world datasets demonstrate that our framework substantially outperforms state-of-the-art baselines in both retrieval accuracy and efficiency, while maintaining robustness under dynamic data evolution. These results highlight the effectiveness and practicality of the proposed approach for scalable spatiotemporal information retrieval in intelligent systems.
Dual-branch Spatial-Temporal Self-supervised Representation for Enhanced Road Network Learning
Nov 10, 2025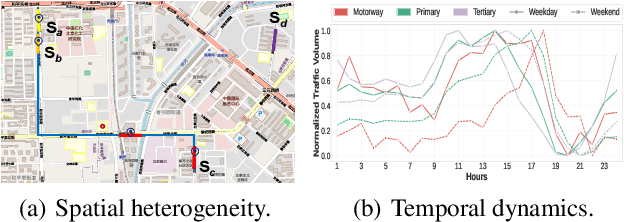



Road network representation learning (RNRL) has attracted increasing attention from both researchers and practitioners as various spatiotemporal tasks are emerging. Recent advanced methods leverage Graph Neural Networks (GNNs) and contrastive learning to characterize the spatial structure of road segments in a self-supervised paradigm. However, spatial heterogeneity and temporal dynamics of road networks raise severe challenges to the neighborhood smoothing mechanism of self-supervised GNNs. To address these issues, we propose a $\textbf{D}$ual-branch $\textbf{S}$patial-$\textbf{T}$emporal self-supervised representation framework for enhanced road representations, termed as DST. On one hand, DST designs a mix-hop transition matrix for graph convolution to incorporate dynamic relations of roads from trajectories. Besides, DST contrasts road representations of the vanilla road network against that of the hypergraph in a spatial self-supervised way. The hypergraph is newly built based on three types of hyperedges to capture long-range relations. On the other hand, DST performs next token prediction as the temporal self-supervised task on the sequences of traffic dynamics based on a causal Transformer, which is further regularized by differentiating traffic modes of weekdays from those of weekends. Extensive experiments against state-of-the-art methods verify the superiority of our proposed framework. Moreover, the comprehensive spatiotemporal modeling facilitates DST to excel in zero-shot learning scenarios.
Bridging the Gap: Self-Optimized Fine-Tuning for LLM-based Recommender Systems
May 27, 2025Recent years have witnessed extensive exploration of Large Language Models (LLMs) on the field of Recommender Systems (RS). There are currently two commonly used strategies to enable LLMs to have recommendation capabilities: 1) The "Guidance-Only" strategy uses in-context learning to exploit and amplify the inherent semantic understanding and item recommendation capabilities of LLMs; 2) The "Tuning-Only" strategy uses supervised fine-tuning (SFT) to fine-tune LLMs with the aim of fitting them to real recommendation data. However, neither of these strategies can effectively bridge the gap between the knowledge space of LLMs and recommendation, and their performance do not meet our expectations. To better enable LLMs to learn recommendation knowledge, we combine the advantages of the above two strategies and proposed a novel "Guidance+Tuning" method called Self-Optimized Fine-Tuning (SOFT), which adopts the idea of curriculum learning. It first employs self-distillation to construct an auxiliary easy-to-learn but meaningful dataset from a fine-tuned LLM. Then it further utilizes a self-adaptive curriculum scheduler to enable LLMs to gradually learn from simpler data (self-distilled data) to more challenging data (real RS data). Extensive experiments demonstrate that SOFT significantly enhances the recommendation accuracy (37.59\% on average) of LLM-based methods. The code is available via https://anonymous.4open.science/r/Self-Optimized-Fine-Tuning-264E
Dataset Ownership Verification in Contrastive Pre-trained Models
Feb 11, 2025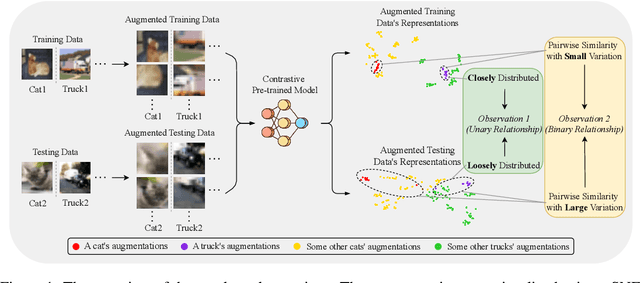
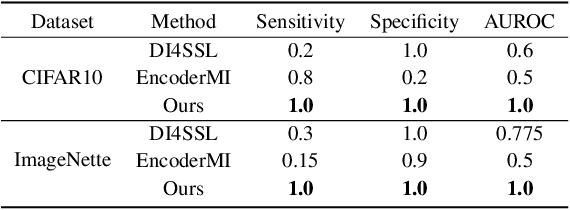
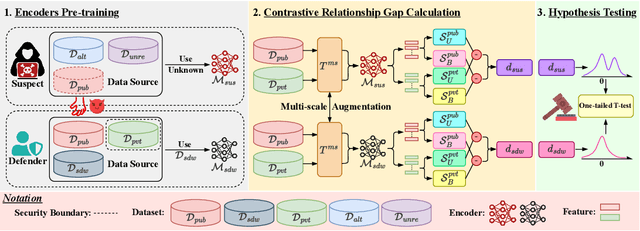
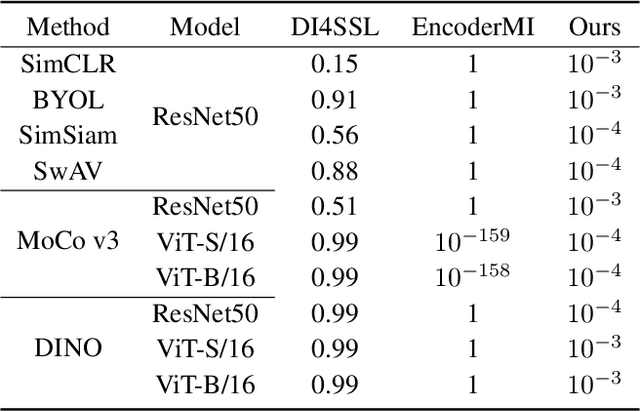
High-quality open-source datasets, which necessitate substantial efforts for curation, has become the primary catalyst for the swift progress of deep learning. Concurrently, protecting these datasets is paramount for the well-being of the data owner. Dataset ownership verification emerges as a crucial method in this domain, but existing approaches are often limited to supervised models and cannot be directly extended to increasingly popular unsupervised pre-trained models. In this work, we propose the first dataset ownership verification method tailored specifically for self-supervised pre-trained models by contrastive learning. Its primary objective is to ascertain whether a suspicious black-box backbone has been pre-trained on a specific unlabeled dataset, aiding dataset owners in upholding their rights. The proposed approach is motivated by our empirical insights that when models are trained with the target dataset, the unary and binary instance relationships within the embedding space exhibit significant variations compared to models trained without the target dataset. We validate the efficacy of this approach across multiple contrastive pre-trained models including SimCLR, BYOL, SimSiam, MOCO v3, and DINO. The results demonstrate that our method rejects the null hypothesis with a $p$-value markedly below $0.05$, surpassing all previous methodologies. Our code is available at https://github.com/xieyc99/DOV4CL.
LG-CAV: Train Any Concept Activation Vector with Language Guidance
Oct 14, 2024



Concept activation vector (CAV) has attracted broad research interest in explainable AI, by elegantly attributing model predictions to specific concepts. However, the training of CAV often necessitates a large number of high-quality images, which are expensive to curate and thus limited to a predefined set of concepts. To address this issue, we propose Language-Guided CAV (LG-CAV) to harness the abundant concept knowledge within the certain pre-trained vision-language models (e.g., CLIP). This method allows training any CAV without labeled data, by utilizing the corresponding concept descriptions as guidance. To bridge the gap between vision-language model and the target model, we calculate the activation values of concept descriptions on a common pool of images (probe images) with vision-language model and utilize them as language guidance to train the LG-CAV. Furthermore, after training high-quality LG-CAVs related to all the predicted classes in the target model, we propose the activation sample reweighting (ASR), serving as a model correction technique, to improve the performance of the target model in return. Experiments on four datasets across nine architectures demonstrate that LG-CAV achieves significantly superior quality to previous CAV methods given any concept, and our model correction method achieves state-of-the-art performance compared to existing concept-based methods. Our code is available at https://github.com/hqhQAQ/LG-CAV.