 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIET: Learning to Distill Dataset Continually for Recommender Systems
Mar 26, 2026Modern deep recommender models are trained under a continual learning paradigm, relying on massive and continuously growing streaming behavioral logs. In large-scale platforms, retraining models on full historical data for architecture comparison or iteration is prohibitively expensive, severely slowing down model development. This challenge calls for data-efficient approaches that can faithfully approximate full-data training behavior without repeatedly processing the entire evolving data stream. We formulate this problem as \emph{streaming dataset distillation for recommender systems} and propose \textbf{DIET}, a unified framework that maintains a compact distilled dataset which evolves alongside streaming data while preserving training-critical signals. Unlike existing dataset distillation methods that construct a static distilled set, DIET models distilled data as an evolving training memory and updates it in a stage-wise manner to remain aligned with long-term training dynamics. DIET enables effective continual distillation through principled initialization from influential samples and selective updates guided by influence-aware memory addressing within a bi-level optimization framework. Experiments on large-scale recommendation benchmarks demonstrate that DIET compresses training data to as little as \textbf{1-2\%} of the original size while preserving performance trends consistent with full-data training, reducing model iteration cost by up to \textbf{60$\times$}. Moreover, the distilled datasets produced by DIET generalize well across different model architectures, highlighting streaming dataset distillation as a scalable and reusable data foundation for recommender system development.
Generative Data Transformation: From Mixed to Unified Data
Feb 26, 2026Recommendation model performance is intrinsically tied to the quality, volume, and relevance of their training data. To address common challenges like data sparsity and cold start, recent researchs have leveraged data from multiple auxiliary domains to enrich information within the target domain. However, inherent domain gaps can degrade the quality of mixed-domain data, leading to negative transfer and diminished model performance. Existing prevailing \emph{model-centric} paradigm -- which relies on complex, customized architectures -- struggles to capture the subtle, non-structural sequence dependencies across domains, leading to poor generalization and high demands on computational resources. To address these shortcomings, we propose \textsc{Taesar}, a \emph{data-centric} framework for \textbf{t}arget-\textbf{a}lign\textbf{e}d \textbf{s}equenti\textbf{a}l \textbf{r}egeneration, which employs a contrastive decoding mechanism to adaptively encode cross-domain context into target-domain sequences. It employs contrastive decoding to encode cross-domain context into target sequences, enabling standard models to learn intricate dependencies without complex fusion architectures. Experiments show \textsc{Taesar} outperforms model-centric solutions and generalizes to various sequential models. By generating enriched datasets, \textsc{Taesar} effectively combines the strengths of data- and model-centric paradigms. The code accompanying this paper is available at~ \textcolor{blue}{https://github.com/USTC-StarTeam/Taesar}.
Why Thinking Hurts? Diagnosing and Rectifying the Reasoning Shift in Foundation Recommender Models
Feb 18, 2026Integrating Chain-of-Thought (CoT) reasoning into Semantic ID-based recommendation foundation models (such as OpenOneRec) often paradoxically degrades recommendation performance. We identify the root cause as textual inertia from the General Subspace, where verbose reasoning dominates inference and causes the model to neglect critical Semantic ID. To address this, we propose a training-free Inference-Time Subspace Alignment framework. By compressing reasoning chains and applying bias-subtracted contrastive decoding, our approach mitigates ungrounded textual drift. Experiments show this effectively calibrates inference, allowing foundation models to leverage reasoning without sacrificing ID-grounded accuracy.
Can Recommender Systems Teach Themselves? A Recursive Self-Improving Framework with Fidelity Control
Feb 17, 2026The scarcity of high-quality training data presents a fundamental bottleneck to scaling machine learning models. This challenge is particularly acute in recommendation systems, where extreme sparsity in user interactions leads to rugged optimization landscapes and poor generalization. We propose the Recursive Self-Improving Recommendation (RSIR) framework, a paradigm in which a model bootstraps its own performance without reliance on external data or teacher models. RSIR operates in a closed loop: the current model generates plausible user interaction sequences, a fidelity-based quality control mechanism filters them for consistency with user's approximate preference manifold, and a successor model is augmented on the enriched dataset. Our theoretical analysis shows that RSIR acts as a data-driven implicit regularizer, smoothing the optimization landscape and guiding models toward more robust solutions. Empirically, RSIR yields consistent, cumulative gains across multiple benchmarks and architectures. Notably, even smaller models benefit, and weak models can generate effective training curricula for stronger ones. These results demonstrate that recursive self-improvement is a general, model-agnostic approach to overcoming data sparsity, suggesting a scalable path forward for recommender systems and beyond. Our anonymized code is available at https://anonymous.4open.science/r/RSIR-7C5B .
From Feature Interaction to Feature Generation: A Generative Paradigm of CTR Prediction Models
Dec 16, 2025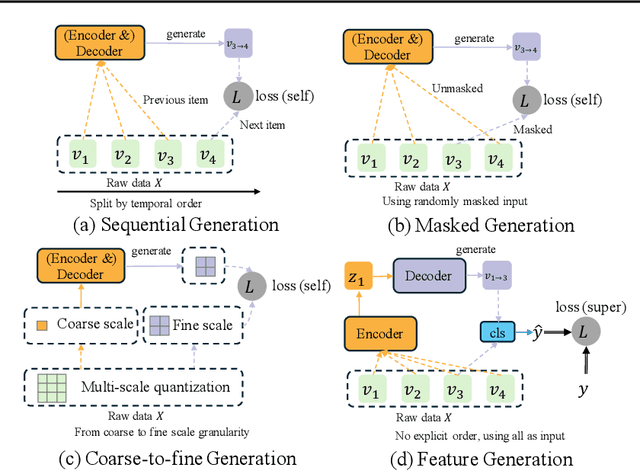
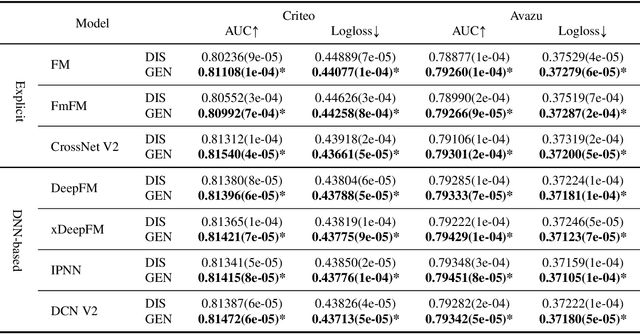
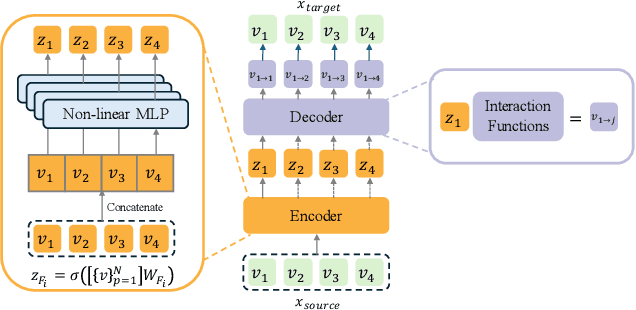
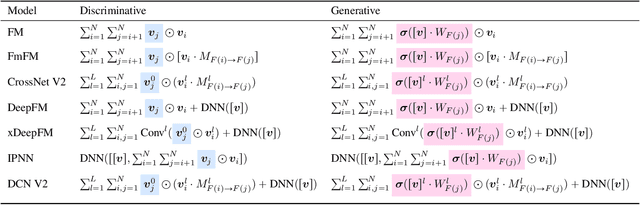
Click-Through Rate (CTR) prediction, a core task in recommendation systems, aims to estimate the probability of users clicking on items. Existing models predominantly follow a discriminative paradigm, which relies heavily on explicit interactions between raw ID embeddings. However, this paradigm inherently renders them susceptible to two critical issues: embedding dimensional collapse and information redundancy, stemming from the over-reliance on feature interactions \emph{over raw ID embeddings}. To address these limitations, we propose a novel \emph{Supervised Feature Generation (SFG)} framework, \emph{shifting the paradigm from discriminative ``feature interaction" to generative ``feature generation"}. Specifically, SFG comprises two key components: an \emph{Encoder} that constructs hidden embeddings for each feature, and a \emph{Decoder} tasked with regenerating the feature embeddings of all features from these hidden representations. Unlike existing generative approaches that adopt self-supervised losses, we introduce a supervised loss to utilize the supervised signal, \ie, click or not, in the CTR prediction task. This framework exhibits strong generalizability: it can be seamlessly integrated with most existing CTR models, reformulating them under the generative paradigm. Extensive experiments demonstrate that SFG consistently mitigates embedding collapse and reduces information redundancy, while yielding substantial performance gains across various datasets and base models. The code is available at https://github.com/USTC-StarTeam/GE4Rec.
Enhancing CTR Prediction with De-correlated Expert Networks
May 23, 2025Modeling feature interactions is essential for accurate click-through rate (CTR) prediction in advertising systems. Recent studies have adopted the Mixture-of-Experts (MoE) approach to improve performance by ensembling multiple feature interaction experts. These studies employ various strategies, such as learning independent embedding tables for each expert or utilizing heterogeneous expert architectures, to differentiate the experts, which we refer to expert \emph{de-correlation}. However, it remains unclear whether these strategies effectively achieve de-correlated experts. To address this, we propose a De-Correlated MoE (D-MoE) framework, which introduces a Cross-Expert De-Correlation loss to minimize expert correlations.Additionally, we propose a novel metric, termed Cross-Expert Correlation, to quantitatively evaluate the expert de-correlation degree. Based on this metric, we identify a key finding for MoE framework design: \emph{different de-correlation strategies are mutually compatible, and progressively employing them leads to reduced correlation and enhanced performance}.Extensive experiments have been conducted to validate the effectiveness of D-MoE and the de-correlation principle. Moreover, online A/B testing on Tencent's advertising platforms demonstrates that D-MoE achieves a significant 1.19\% Gross Merchandise Volume (GMV) lift compared to the Multi-Embedding MoE baseline.
TD3: Tucker Decomposition Based Dataset Distillation Method for Sequential Recommendation
Feb 06, 2025



In the era of data-centric AI, the focus of recommender systems has shifted from model-centric innovations to data-centric approaches. The success of modern AI models is built on large-scale datasets, but this also results in significant training costs. Dataset distillation has emerged as a key solution, condensing large datasets to accelerate model training while preserving model performance. However, condensing discrete and sequentially correlated user-item interactions, particularly with extensive item sets, presents considerable challenges. This paper introduces \textbf{TD3}, a novel \textbf{T}ucker \textbf{D}ecomposition based \textbf{D}ataset \textbf{D}istillation method within a meta-learning framework, designed for sequential recommendation. TD3 distills a fully expressive \emph{synthetic sequence summary} from original data. To efficiently reduce computational complexity and extract refined latent patterns, Tucker decomposition decouples the summary into four factors: \emph{synthetic user latent factor}, \emph{temporal dynamics latent factor}, \emph{shared item latent factor}, and a \emph{relation core} that models their interconnections. Additionally, a surrogate objective in bi-level optimization is proposed to align feature spaces extracted from models trained on both original data and synthetic sequence summary beyond the na\"ive performance matching approach. In the \emph{inner-loop}, an augmentation technique allows the learner to closely fit the synthetic summary, ensuring an accurate update of it in the \emph{outer-loop}. To accelerate the optimization process and address long dependencies, RaT-BPTT is employed for bi-level optimization. Experiments and analyses on multiple public datasets have confirmed the superiority and cross-architecture generalizability of the proposed designs. Codes are released at https://github.com/USTC-StarTeam/TD3.
MDAP: A Multi-view Disentangled and Adaptive Preference Learning Framework for Cross-Domain Recommendation
Oct 08, 2024



Cross-domain Recommendation systems leverage multi-domain user interactions to improve performance, especially in sparse data or new user scenarios. However, CDR faces challenges such as effectively capturing user preferences and avoiding negative transfer. To address these issues, we propose the Multi-view Disentangled and Adaptive Preference Learning (MDAP) framework. Our MDAP framework uses a multiview encoder to capture diverse user preferences. The framework includes a gated decoder that adaptively combines embeddings from different views to generate a comprehensive user representation. By disentangling representations and allowing adaptive feature selection, our model enhances adaptability and effectiveness. Extensive experiments on benchmark datasets demonstrate that our method significantly outperforms state-of-the-art CDR and single-domain models, providing more accurate recommendations and deeper insights into user behavior across different domains.
Entropy Law: The Story Behind Data Compression and LLM Performance
Jul 11, 2024



Data is the cornerstone of large language models (LLMs), but not all data is useful for model learning. Carefully selected data can better elicit the capabilities of LLMs with much less computational overhead. Most methods concentrate on evaluating the quality of individual samples in data selection, while the combinatorial effects among samples are neglected. Even if each sample is of perfect quality, their combinations may be suboptimal in teaching LLMs due to their intrinsic homogeneity or contradiction. In this paper, we aim to uncover the underlying relationships between LLM performance and data selection. Inspired by the information compression nature of LLMs, we uncover an ``entropy law'' that connects LLM performance with data compression ratio and first-epoch training loss, which reflect the information redundancy of a dataset and the mastery of inherent knowledge encoded in this dataset, respectively. Through both theoretical deduction and empirical evaluation, we find that model performance is negatively correlated to the compression ratio of training data, which usually yields a lower training loss. Based on the findings of the entropy law, we propose a quite efficient and universal data selection method named \textbf{ZIP} for training LLMs, which aim to prioritize data subsets exhibiting a low compression ratio. Based on a multi-stage algorithm that selects diverse data in a greedy manner, we can obtain a good data subset with satisfactory diversity. Extensive experiments have been conducted to validate the entropy law and the superiority of ZIP across different LLM backbones and alignment stages. We also present an interesting application of entropy law that can detect potential performance risks at the beginning of model training.
Dataset Regeneration for Sequential Recommendation
May 28, 2024The sequential recommender (SR) system is a crucial component of modern recommender systems, as it aims to capture the evolving preferences of users. Significant efforts have been made to enhance the capabilities of SR systems. These methods typically follow the \textbf{model-centric} paradigm, which involves developing effective models based on fixed datasets. However, this approach often overlooks potential quality issues and flaws inherent in the data. Driven by the potential of \textbf{data-centric} AI, we propose a novel data-centric paradigm for developing an ideal training dataset using a model-agnostic dataset regeneration framework called DR4SR. This framework enables the regeneration of a dataset with exceptional cross-architecture generalizability. Additionally, we introduce the DR4SR+ framework, which incorporates a model-aware dataset personalizer to tailor the regenerated dataset specifically for a target model. To demonstrate the effectiveness of the data-centric paradigm, we integrate our framework with various model-centric methods and observe significant performance improvements across four widely adopted datasets. Furthermore, we conduct in-depth analyses to explore the potential of the data-centric paradigm and provide valuable insights. The code can be found at \textcolor{blue}{\url{https://anonymous.4open.science/r/KDD2024-86EA/}}