 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignGPT: Multi-modal Large Language Models with Adaptive Alignment Capability
May 23, 2024

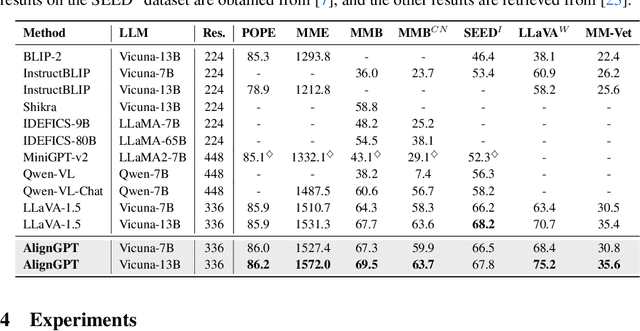
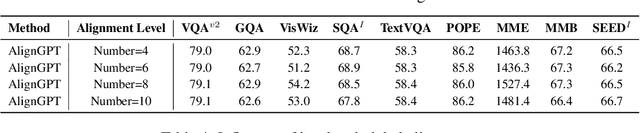
Multimodal Large Language Models (MLLMs) are widely regarded as crucial in the exploration of Artificial General Intelligence (AGI). The core of MLLMs lies in their capability to achieve cross-modal alignment. To attain this goal, current MLLMs typically follow a two-phase training paradigm: the pre-training phase and the instruction-tuning phase. Despite their success, there are shortcomings in the modeling of alignment capabilities within these models. Firstly, during the pre-training phase, the model usually assumes that all image-text pairs are uniformly aligned, but in fact the degree of alignment between different image-text pairs is inconsistent. Secondly, the instructions currently used for finetuning incorporate a variety of tasks, different tasks's instructions usually require different levels of alignment capabilities, but previous MLLMs overlook these differentiated alignment needs. To tackle these issues, we propose a new multimodal large language model AlignGPT. In the pre-training stage, instead of treating all image-text pairs equally, we assign different levels of alignment capabilities to different image-text pairs. Then, in the instruction-tuning phase, we adaptively combine these different levels of alignment capabilities to meet the dynamic alignment needs of different instructions. Extensive experimental results show that our model achieves competitive performance on 12 benchmarks.
Knowledge-aware Dual-side Attribute-enhanced Recommendation
Mar 24, 2024



\textit{Knowledge-aware} recommendation methods (KGR) based on \textit{graph neural networks} (GNNs) and \textit{contrastive learning} (CL) have achieved promising performance. However, they fall short in modeling fine-grained user preferences and further fail to leverage the \textit{preference-attribute connection} to make predictions, leading to sub-optimal performance. To address the issue, we propose a method named \textit{\textbf{K}nowledge-aware \textbf{D}ual-side \textbf{A}ttribute-enhanced \textbf{R}ecommendation} (KDAR). Specifically, we build \textit{user preference representations} and \textit{attribute fusion representations} upon the attribute information in knowledge graphs, which are utilized to enhance \textit{collaborative filtering} (CF) based user and item representations, respectively. To discriminate the contribution of each attribute in these two types of attribute-based representations, a \textit{multi-level collaborative alignment contrasting} mechanism is proposed to align the importance of attributes with CF signals. Experimental results on four benchmark datasets demonstrate the superiority of KDAR over several state-of-the-art baselines. Further analyses verify the effectiveness of our method. The code of KDAR is released at: \href{https://github.com/TJTP/KDAR}{https://github.com/TJTP/KDAR}.
Dynamic Demonstrations Controller for In-Context Learning
Sep 30, 2023


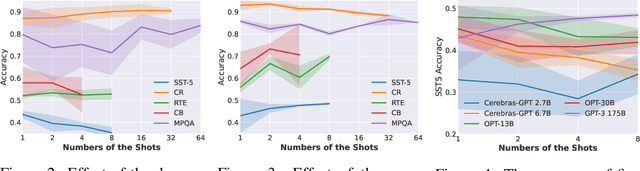
In-Context Learning (ICL) is a new paradigm for natural language processing (NLP), where a large language model (LLM) observes a small number of demonstrations and a test instance as its input, and directly makes predictions without updating model parameters. Previous studies have revealed that ICL is sensitive to the selection and the ordering of demonstrations. However, there are few studies regarding the impact of the demonstration number on the ICL performance within a limited input length of LLM, because it is commonly believed that the number of demonstrations is positively correlated with model performance. In this paper, we found this conclusion does not always hold true. Through pilot experiments, we discover that increasing the number of demonstrations does not necessarily lead to improved performance. Building upon this insight, we propose a Dynamic Demonstrations Controller (D$^2$Controller), which can improve the ICL performance by adjusting the number of demonstrations dynamically. The experimental results show that D$^2$Controller yields a 5.4% relative improvement on eight different sizes of LLMs across ten datasets. Moreover, we also extend our method to previous ICL models and achieve competitive results.