 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemTrace: Tracing and Attributing Errors in Large Language Model Memory Systems
May 27, 2026Memory is essential for enabling large language models to support long-horizon reasoning, yet existing memory systems remain unreliable and difficult to debug. Tracing memory's dynamic evolution is crucial to understand how information is synthesized, propagated, or corrupted over time. In this work, we study the new problem of error tracing and attribution in LLM memory systems. We propose a novel framework that transforms memory pipelines into executable memory evolution graphs, enabling fine-grained tracing of operational information flow. We then construct MemTraceBench, a benchmark collected from representative memory systems such as Long-Context, RAG, Mem0, and EverMemOS, to systematically study memory failure modes. We further introduce an automatic attribution method that iteratively traces operation subgraphs to pinpoint the root cause of any failed case. Our analysis reveals that memory failures are systematic, stemming from operation-level issues like information loss and retrieval misalignment. Crucially, we leverage these fine-grained attribution signals to guide downstream prompt optimization, establishing a closed-loop system that automatically corrects faults and boosts end-task performance by up to 7.62%. Code will be released at https://github.com/zjunlp/MemTrace.
DOD-SA: Infrared-Visible Decoupled Object Detection with Single-Modality Annotations
Aug 14, 2025Infrared-visible object detection has shown great potential in real-world applications, enabling robust all-day perception by leveraging the complementary information of infrared and visible images. However, existing methods typically require dual-modality annotations to output detection results for both modalities during prediction, which incurs high annotation costs. To address this challenge, we propose a novel infrared-visible Decoupled Object Detection framework with Single-modality Annotations, called DOD-SA. The architecture of DOD-SA is built upon a Single- and Dual-Modality Collaborative Teacher-Student Network (CoSD-TSNet), which consists of a single-modality branch (SM-Branch) and a dual-modality decoupled branch (DMD-Branch). The teacher model generates pseudo-labels for the unlabeled modality, simultaneously supporting the training of the student model. The collaborative design enables cross-modality knowledge transfer from the labeled modality to the unlabeled modality, and facilitates effective SM-to-DMD branch supervision. To further improve the decoupling ability of the model and the pseudo-label quality, we introduce a Progressive and Self-Tuning Training Strategy (PaST) that trains the model in three stages: (1) pretraining SM-Branch, (2) guiding the learning of DMD-Branch by SM-Branch, and (3) refining DMD-Branch. In addition, we design a Pseudo Label Assigner (PLA) to align and pair labels across modalities, explicitly addressing modality misalignment during training. Extensive experiments on the DroneVehicle dataset demonstrate that our method outperforms state-of-the-art (SOTA).
ScalingNoise: Scaling Inference-Time Search for Generating Infinite Videos
Mar 20, 2025Video diffusion models (VDMs) facilitate the generation of high-quality videos, with current research predominantly concentrated on scaling efforts during training through improvements in data quality, computational resources, and model complexity. However, inference-time scaling has received less attention, with most approaches restricting models to a single generation attempt. Recent studies have uncovered the existence of "golden noises" that can enhance video quality during generation. Building on this, we find that guiding the scaling inference-time search of VDMs to identify better noise candidates not only evaluates the quality of the frames generated in the current step but also preserves the high-level object features by referencing the anchor frame from previous multi-chunks, thereby delivering long-term value. Our analysis reveals that diffusion models inherently possess flexible adjustments of computation by varying denoising steps, and even a one-step denoising approach, when guided by a reward signal, yields significant long-term benefits. Based on the observation, we proposeScalingNoise, a plug-and-play inference-time search strategy that identifies golden initial noises for the diffusion sampling process to improve global content consistency and visual diversity. Specifically, we perform one-step denoising to convert initial noises into a clip and subsequently evaluate its long-term value, leveraging a reward model anchored by previously generated content. Moreover, to preserve diversity, we sample candidates from a tilted noise distribution that up-weights promising noises. In this way, ScalingNoise significantly reduces noise-induced errors, ensuring more coherent and spatiotemporally consistent video generation. Extensive experiments on benchmark datasets demonstrate that the proposed ScalingNoise effectively improves long video generation.
CM-Diff: A Single Generative Network for Bidirectional Cross-Modality Translation Diffusion Model Between Infrared and Visible Images
Mar 12, 2025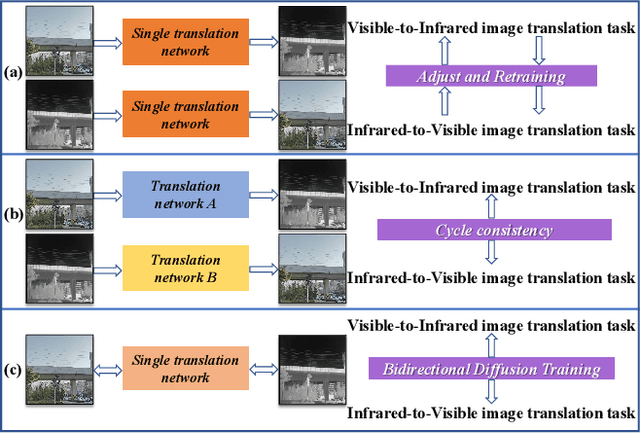
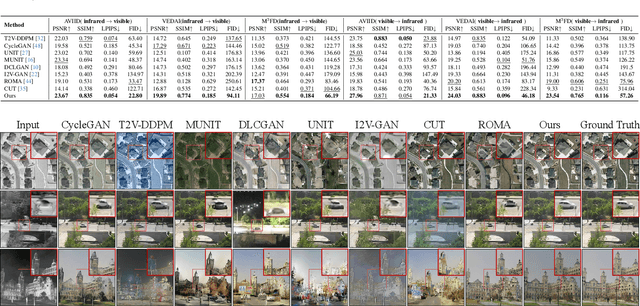
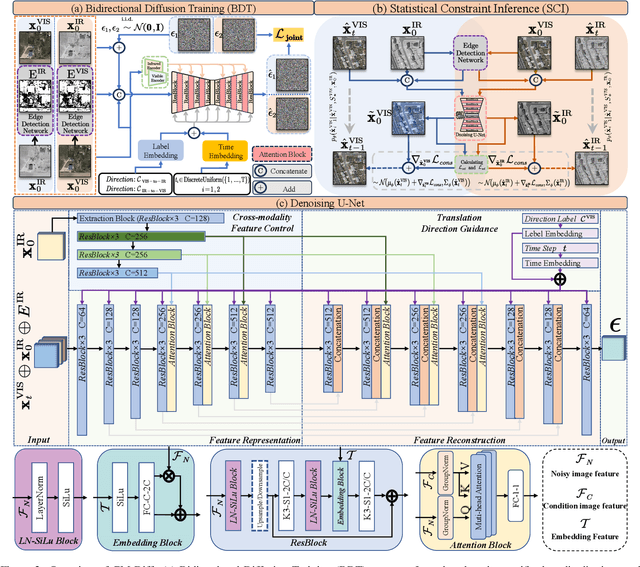

The image translation method represents a crucial approach for mitigating information deficiencies in the infrared and visible modalities, while also facilitating the enhancement of modality-specific datasets. However, existing methods for infrared and visible image translation either achieve unidirectional modality translation or rely on cycle consistency for bidirectional modality translation, which may result in suboptimal performance. In this work, we present the cross-modality translation diffusion model (CM-Diff) for simultaneously modeling data distributions in both the infrared and visible modalities. We address this challenge by combining translation direction labels for guidance during training with cross-modality feature control. Specifically, we view the establishment of the mapping relationship between the two modalities as the process of learning data distributions and understanding modality differences, achieved through a novel Bidirectional Diffusion Training (BDT) strategy. Additionally, we propose a Statistical Constraint Inference (SCI) strategy to ensure the generated image closely adheres to the data distribution of the target modality. Experimental results demonstrate the superiority of our CM-Diff over state-of-the-art methods, highlighting its potential for generating dual-modality datasets.
IV-tuning: Parameter-Efficient Transfer Learning for Infrared-Visible Tasks
Dec 21, 2024Infrared-visible (IR-VIS) tasks, such as semantic segmentation and object detection, greatly benefit from the advantage of combining infrared and visible modalities. To inherit the general representations of the Vision Foundation Models (VFMs), task-specific dual-branch networks are designed and fully fine-tuned on downstream datasets. Although effective, this manner lacks generality and is sub-optimal due to the scarcity of downstream infrared-visible datasets and limited transferability. In this paper, we propose a novel and general fine-tuning approach, namely "IV-tuning", to parameter-efficiently harness VFMs for various infrared-visible downstream tasks. At its core, IV-tuning freezes pre-trained visible-based VFMs and integrates modal-specific prompts with adapters within the backbone, bridging the gap between VFMs and downstream infrared-visible tasks while simultaneously learning the complementarity between different modalities. By fine-tuning approximately 3% of the backbone parameters, IV-tuning outperforms full fine-tuning across various baselines in infrared-visible semantic segmentation and object detection, as well as previous state-of-the-art methods. Extensive experiments across various settings demonstrate that IV-tuning achieves superior performance with fewer training parameters, providing a good alternative to full fine-tuning and a novel method of extending visible-based models for infrared-visible tasks. The code is available at https://github.com/Yummy198913/IV-tuning.
IVGF: The Fusion-Guided Infrared and Visible General Framework
Sep 02, 2024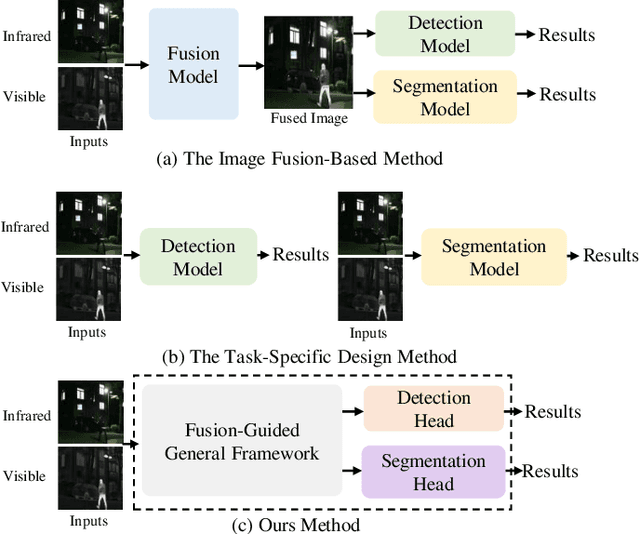
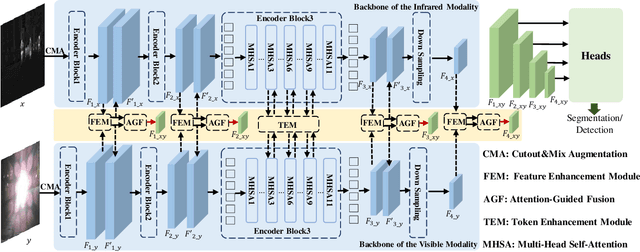
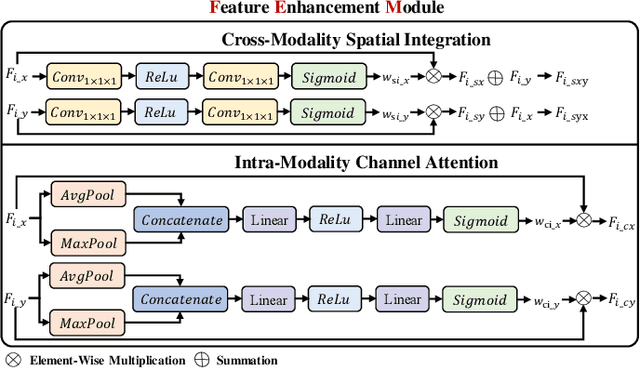

Infrared and visible dual-modality tasks such as semantic segmentation and object detection can achieve robust performance even in extreme scenes by fusing complementary information. Most current methods design task-specific frameworks, which are limited in generalization across multiple tasks. In this paper, we propose a fusion-guided infrared and visible general framework, IVGF, which can be easily extended to many high-level vision tasks. Firstly, we adopt the SOTA infrared and visible foundation models to extract the general representations. Then, to enrich the semantics information of these general representations for high-level vision tasks, we design the feature enhancement module and token enhancement module for feature maps and tokens, respectively. Besides, the attention-guided fusion module is proposed for effectively fusing by exploring the complementary information of two modalities. Moreover, we also adopt the cutout&mix augmentation strategy to conduct the data augmentation, which further improves the ability of the model to mine the regional complementary between the two modalities. Extensive experiments show that the IVGF outperforms state-of-the-art dual-modality methods in the semantic segmentation and object detection tasks. The detailed ablation studies demonstrate the effectiveness of each module, and another experiment explores the anti-missing modality ability of the proposed method in the dual-modality semantic segmentation task.
DPDETR: Decoupled Position Detection Transformer for Infrared-Visible Object Detection
Aug 12, 2024
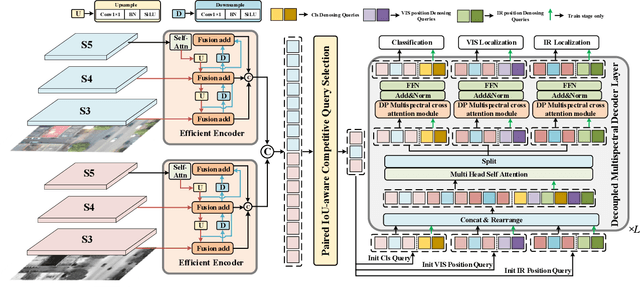
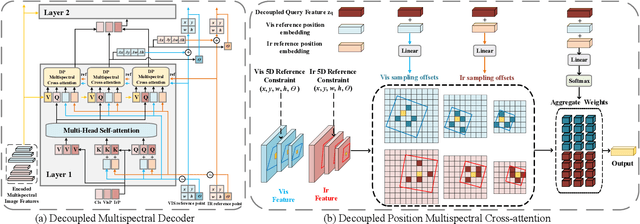
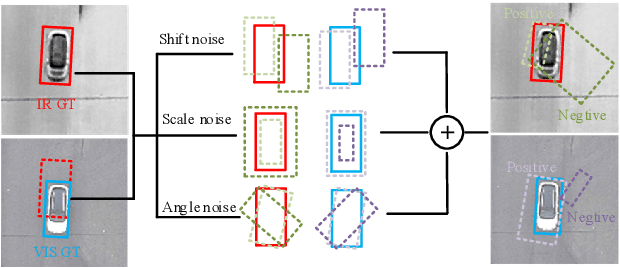
Infrared-visible object detection aims to achieve robust object detection by leveraging the complementary information of infrared and visible image pairs. However, the commonly existing modality misalignment problem presents two challenges: fusing misalignment complementary features is difficult, and current methods cannot accurately locate objects in both modalities under misalignment conditions. In this paper, we propose a Decoupled Position Detection Transformer (DPDETR) to address these problems. Specifically, we explicitly formulate the object category, visible modality position, and infrared modality position to enable the network to learn the intrinsic relationships and output accurate positions of objects in both modalities. To fuse misaligned object features accurately, we propose a Decoupled Position Multispectral Cross-attention module that adaptively samples and aggregates multispectral complementary features with the constraint of infrared and visible reference positions. Additionally, we design a query-decoupled Multispectral Decoder structure to address the optimization gap among the three kinds of object information in our task and propose a Decoupled Position Contrastive DeNosing Training strategy to enhance the DPDETR's ability to learn decoupled positions. Experiments on DroneVehicle and KAIST datasets demonstrate significant improvements compared to other state-of-the-art methods. The code will be released at https://github.com/gjj45/DPDETR.
Advanced Financial Fraud Detection Using GNN-CL Model
Jul 09, 2024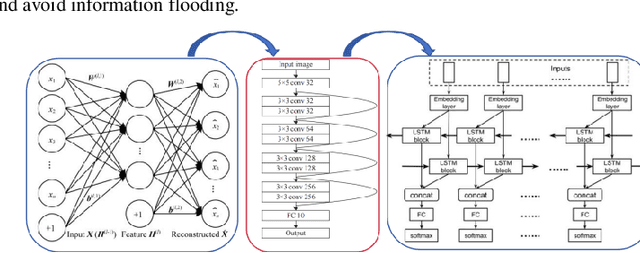
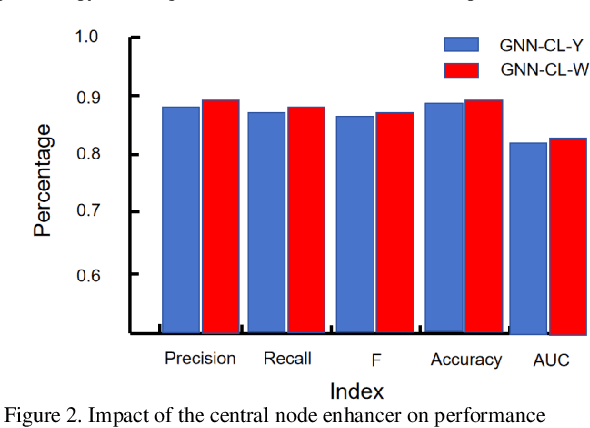
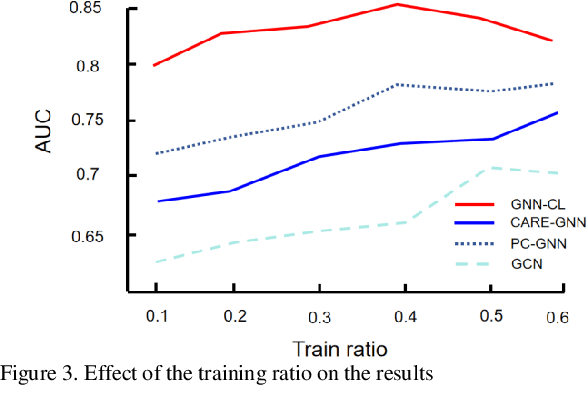
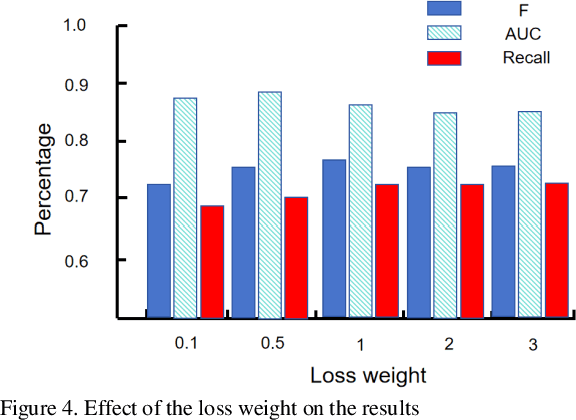
The innovative GNN-CL model proposed in this paper marks a breakthrough in the field of financial fraud detection by synergistically combining the advantages of graph neural networks (gnn), convolutional neural networks (cnn) and long short-term memory (LSTM) networks. This convergence enables multifaceted analysis of complex transaction patterns, improving detection accuracy and resilience against complex fraudulent activities. A key novelty of this paper is the use of multilayer perceptrons (MLPS) to estimate node similarity, effectively filtering out neighborhood noise that can lead to false positives. This intelligent purification mechanism ensures that only the most relevant information is considered, thereby improving the model's understanding of the network structure. Feature weakening often plagues graph-based models due to the dilution of key signals. In order to further address the challenge of feature weakening, GNN-CL adopts reinforcement learning strategies. By dynamically adjusting the weights assigned to central nodes, it reinforces the importance of these influential entities to retain important clues of fraud even in less informative data. Experimental evaluations on Yelp datasets show that the results highlight the superior performance of GNN-CL compared to existing methods.
Extroversion or Introversion? Controlling The Personality of Your Large Language Models
Jun 07, 2024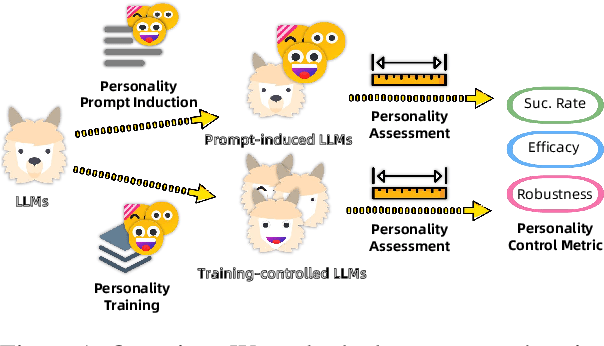
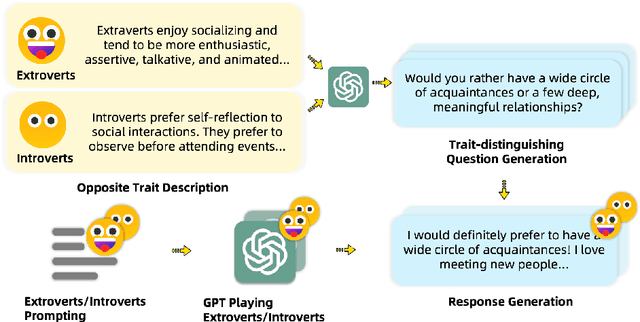

Large language models (LLMs) exhibit robust capabilities in text generation and comprehension, mimicking human behavior and exhibiting synthetic personalities. However, some LLMs have displayed offensive personality, propagating toxic discourse. Existing literature neglects the origin and evolution of LLM personalities, as well as the effective personality control. To fill these gaps, our study embarked on a comprehensive investigation into LLM personality control. We investigated several typical methods to influence LLMs, including three training methods: Continual Pre-training, Supervised Fine-Tuning (SFT), and Reinforcement Learning from Human Feedback (RLHF), along with inference phase considerations (prompts). Our investigation revealed a hierarchy of effectiveness in control: Prompt > SFT > RLHF > Continual Pre-train. Notably, SFT exhibits a higher control success rate compared to prompt induction. While prompts prove highly effective, we found that prompt-induced personalities are less robust than those trained, making them more prone to showing conflicting personalities under reverse personality prompt induction. Besides, harnessing the strengths of both SFT and prompt, we proposed $\underline{\text{P}}$rompt $\underline{\text{I}}$nduction post $\underline{\text{S}}$upervised $\underline{\text{F}}$ine-tuning (PISF), which emerges as the most effective and robust strategy for controlling LLMs' personality, displaying high efficacy, high success rates, and high robustness. Even under reverse personality prompt induction, LLMs controlled by PISF still exhibit stable and robust personalities.
Advancing Financial Risk Prediction Through Optimized LSTM Model Performance and Comparative Analysis
May 31, 2024This paper focuses on the application and optimization of LSTM model in financial risk prediction. The study starts with an overview of the architecture and algorithm foundation of LSTM, and then details the model training process and hyperparameter tuning strategy, and adjusts network parameters through experiments to improve performance. Comparative experiments show that the optimized LSTM model shows significant advantages in AUC index compared with random forest, BP neural network and XGBoost, which verifies its efficiency and practicability in the field of financial risk prediction, especially its ability to deal with complex time series data, which lays a solid foundation for the application of the model in the actual production environment.