 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDOD-SA: Infrared-Visible Decoupled Object Detection with Single-Modality Annotations
Aug 14, 2025Infrared-visible object detection has shown great potential in real-world applications, enabling robust all-day perception by leveraging the complementary information of infrared and visible images. However, existing methods typically require dual-modality annotations to output detection results for both modalities during prediction, which incurs high annotation costs. To address this challenge, we propose a novel infrared-visible Decoupled Object Detection framework with Single-modality Annotations, called DOD-SA. The architecture of DOD-SA is built upon a Single- and Dual-Modality Collaborative Teacher-Student Network (CoSD-TSNet), which consists of a single-modality branch (SM-Branch) and a dual-modality decoupled branch (DMD-Branch). The teacher model generates pseudo-labels for the unlabeled modality, simultaneously supporting the training of the student model. The collaborative design enables cross-modality knowledge transfer from the labeled modality to the unlabeled modality, and facilitates effective SM-to-DMD branch supervision. To further improve the decoupling ability of the model and the pseudo-label quality, we introduce a Progressive and Self-Tuning Training Strategy (PaST) that trains the model in three stages: (1) pretraining SM-Branch, (2) guiding the learning of DMD-Branch by SM-Branch, and (3) refining DMD-Branch. In addition, we design a Pseudo Label Assigner (PLA) to align and pair labels across modalities, explicitly addressing modality misalignment during training. Extensive experiments on the DroneVehicle dataset demonstrate that our method outperforms state-of-the-art (SOTA).
CM-Diff: A Single Generative Network for Bidirectional Cross-Modality Translation Diffusion Model Between Infrared and Visible Images
Mar 12, 2025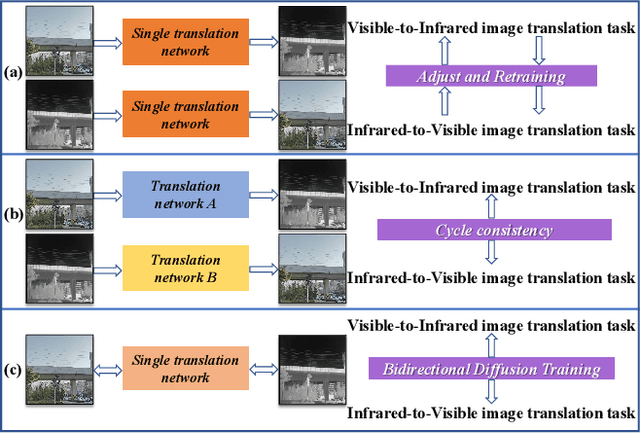
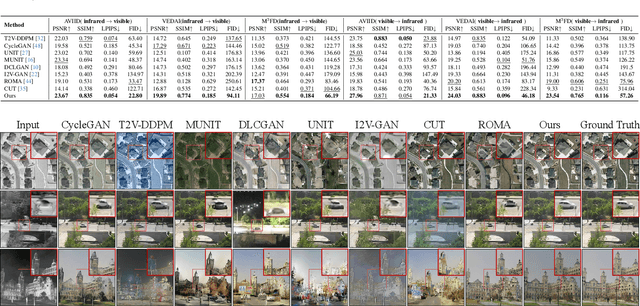
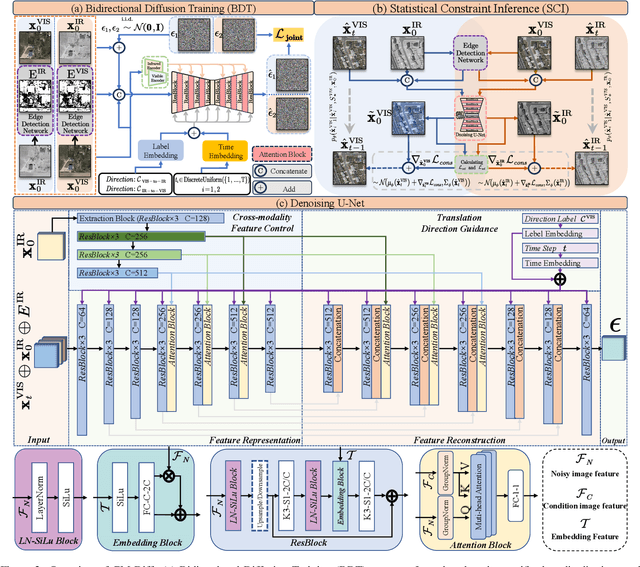

The image translation method represents a crucial approach for mitigating information deficiencies in the infrared and visible modalities, while also facilitating the enhancement of modality-specific datasets. However, existing methods for infrared and visible image translation either achieve unidirectional modality translation or rely on cycle consistency for bidirectional modality translation, which may result in suboptimal performance. In this work, we present the cross-modality translation diffusion model (CM-Diff) for simultaneously modeling data distributions in both the infrared and visible modalities. We address this challenge by combining translation direction labels for guidance during training with cross-modality feature control. Specifically, we view the establishment of the mapping relationship between the two modalities as the process of learning data distributions and understanding modality differences, achieved through a novel Bidirectional Diffusion Training (BDT) strategy. Additionally, we propose a Statistical Constraint Inference (SCI) strategy to ensure the generated image closely adheres to the data distribution of the target modality. Experimental results demonstrate the superiority of our CM-Diff over state-of-the-art methods, highlighting its potential for generating dual-modality datasets.
IV-tuning: Parameter-Efficient Transfer Learning for Infrared-Visible Tasks
Dec 21, 2024Infrared-visible (IR-VIS) tasks, such as semantic segmentation and object detection, greatly benefit from the advantage of combining infrared and visible modalities. To inherit the general representations of the Vision Foundation Models (VFMs), task-specific dual-branch networks are designed and fully fine-tuned on downstream datasets. Although effective, this manner lacks generality and is sub-optimal due to the scarcity of downstream infrared-visible datasets and limited transferability. In this paper, we propose a novel and general fine-tuning approach, namely "IV-tuning", to parameter-efficiently harness VFMs for various infrared-visible downstream tasks. At its core, IV-tuning freezes pre-trained visible-based VFMs and integrates modal-specific prompts with adapters within the backbone, bridging the gap between VFMs and downstream infrared-visible tasks while simultaneously learning the complementarity between different modalities. By fine-tuning approximately 3% of the backbone parameters, IV-tuning outperforms full fine-tuning across various baselines in infrared-visible semantic segmentation and object detection, as well as previous state-of-the-art methods. Extensive experiments across various settings demonstrate that IV-tuning achieves superior performance with fewer training parameters, providing a good alternative to full fine-tuning and a novel method of extending visible-based models for infrared-visible tasks. The code is available at https://github.com/Yummy198913/IV-tuning.
IVGF: The Fusion-Guided Infrared and Visible General Framework
Sep 02, 2024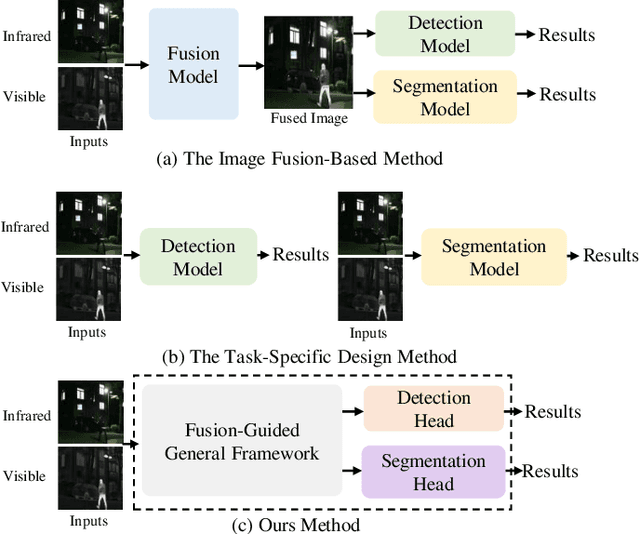
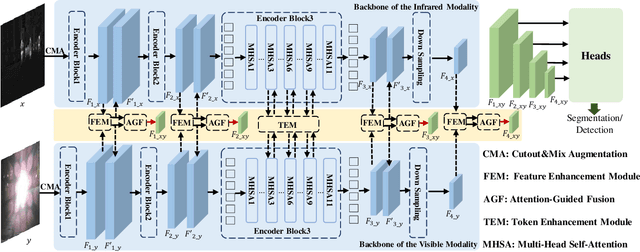
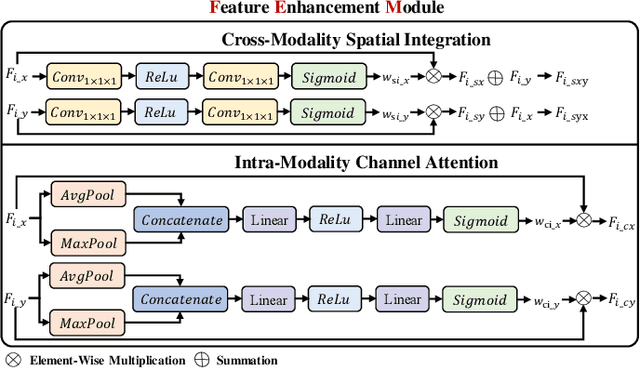

Infrared and visible dual-modality tasks such as semantic segmentation and object detection can achieve robust performance even in extreme scenes by fusing complementary information. Most current methods design task-specific frameworks, which are limited in generalization across multiple tasks. In this paper, we propose a fusion-guided infrared and visible general framework, IVGF, which can be easily extended to many high-level vision tasks. Firstly, we adopt the SOTA infrared and visible foundation models to extract the general representations. Then, to enrich the semantics information of these general representations for high-level vision tasks, we design the feature enhancement module and token enhancement module for feature maps and tokens, respectively. Besides, the attention-guided fusion module is proposed for effectively fusing by exploring the complementary information of two modalities. Moreover, we also adopt the cutout&mix augmentation strategy to conduct the data augmentation, which further improves the ability of the model to mine the regional complementary between the two modalities. Extensive experiments show that the IVGF outperforms state-of-the-art dual-modality methods in the semantic segmentation and object detection tasks. The detailed ablation studies demonstrate the effectiveness of each module, and another experiment explores the anti-missing modality ability of the proposed method in the dual-modality semantic segmentation task.
DPDETR: Decoupled Position Detection Transformer for Infrared-Visible Object Detection
Aug 12, 2024
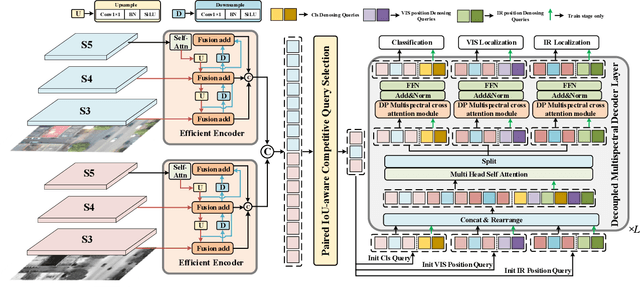
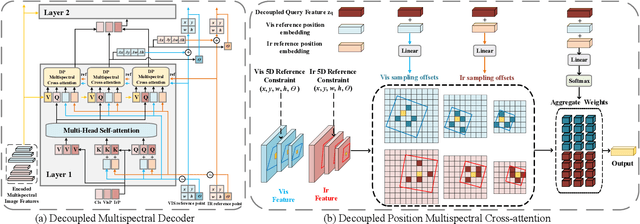
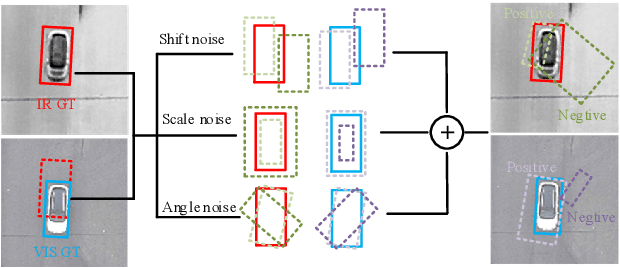
Infrared-visible object detection aims to achieve robust object detection by leveraging the complementary information of infrared and visible image pairs. However, the commonly existing modality misalignment problem presents two challenges: fusing misalignment complementary features is difficult, and current methods cannot accurately locate objects in both modalities under misalignment conditions. In this paper, we propose a Decoupled Position Detection Transformer (DPDETR) to address these problems. Specifically, we explicitly formulate the object category, visible modality position, and infrared modality position to enable the network to learn the intrinsic relationships and output accurate positions of objects in both modalities. To fuse misaligned object features accurately, we propose a Decoupled Position Multispectral Cross-attention module that adaptively samples and aggregates multispectral complementary features with the constraint of infrared and visible reference positions. Additionally, we design a query-decoupled Multispectral Decoder structure to address the optimization gap among the three kinds of object information in our task and propose a Decoupled Position Contrastive DeNosing Training strategy to enhance the DPDETR's ability to learn decoupled positions. Experiments on DroneVehicle and KAIST datasets demonstrate significant improvements compared to other state-of-the-art methods. The code will be released at https://github.com/gjj45/DPDETR.
DAMSDet: Dynamic Adaptive Multispectral Detection Transformer with Competitive Query Selection and Adaptive Feature Fusion
Mar 07, 2024



Infrared-visible object detection aims to achieve robust even full-day object detection by fusing the complementary information of infrared and visible images. However, highly dynamically variable complementary characteristics and commonly existing modality misalignment make the fusion of complementary information difficult. In this paper, we propose a Dynamic Adaptive Multispectral Detection Transformer (DAMSDet) to simultaneously address these two challenges. Specifically, we propose a Modality Competitive Query Selection strategy to provide useful prior information. This strategy can dynamically select basic salient modality feature representation for each object. To effectively mine the complementary information and adapt to misalignment situations, we propose a Multispectral Deformable Cross-attention module to adaptively sample and aggregate multi-semantic level features of infrared and visible images for each object. In addition, we further adopt the cascade structure of DETR to better mine complementary information. Experiments on four public datasets of different scenes demonstrate significant improvements compared to other state-of-the-art methods. The code will be released at https://github.com/gjj45/DAMSDet.
Are Dense Labels Always Necessary for 3D Object Detection from Point Cloud?
Mar 05, 2024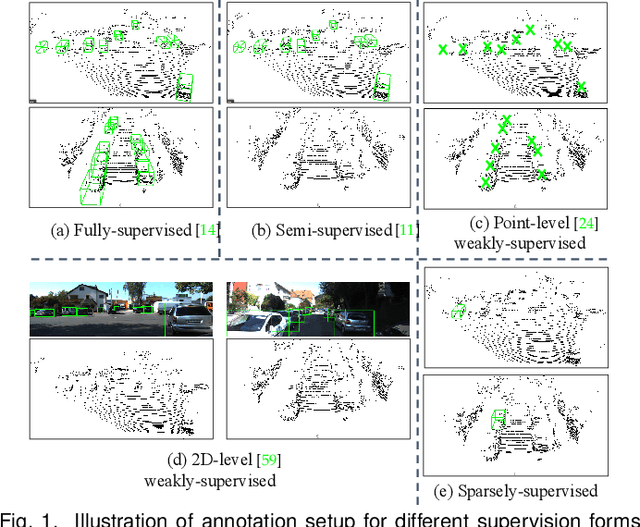



Current state-of-the-art (SOTA) 3D object detection methods often require a large amount of 3D bounding box annotations for training. However, collecting such large-scale densely-supervised datasets is notoriously costly. To reduce the cumbersome data annotation process, we propose a novel sparsely-annotated framework, in which we just annotate one 3D object per scene. Such a sparse annotation strategy could significantly reduce the heavy annotation burden, while inexact and incomplete sparse supervision may severely deteriorate the detection performance. To address this issue, we develop the SS3D++ method that alternatively improves 3D detector training and confident fully-annotated scene generation in a unified learning scheme. Using sparse annotations as seeds, we progressively generate confident fully-annotated scenes based on designing a missing-annotated instance mining module and reliable background mining module. Our proposed method produces competitive results when compared with SOTA weakly-supervised methods using the same or even more annotation costs. Besides, compared with SOTA fully-supervised methods, we achieve on-par or even better performance on the KITTI dataset with about 5x less annotation cost, and 90% of their performance on the Waymo dataset with about 15x less annotation cost. The additional unlabeled training scenes could further boost the performance. The code will be available at https://github.com/gaocq/SS3D2.
InfMAE: A Foundation Model in Infrared Modality
Feb 01, 2024In recent years, the foundation models have swept the computer vision field and facilitated the development of various tasks within different modalities. However, it remains an open question on how to design an infrared foundation model. In this paper, we propose InfMAE, a foundation model in infrared modality. We release an infrared dataset, called Inf30 to address the problem of lacking large-scale data for self-supervised learning in the infrared vision community. Besides, we design an information-aware masking strategy, which is suitable for infrared images. This masking strategy allows for a greater emphasis on the regions with richer information in infrared images during the self-supervised learning process, which is conducive to learning the generalized representation. In addition, we adopt a multi-scale encoder to enhance the performance of the pre-trained encoders in downstream tasks. Finally, based on the fact that infrared images do not have a lot of details and texture information, we design an infrared decoder module, which further improves the performance of downstream tasks. Extensive experiments show that our proposed method InfMAE outperforms other supervised methods and self-supervised learning methods in three downstream tasks. Our code will be made public at https://github.com/liufangcen/InfMAE.
Hierarchical Supervision and Shuffle Data Augmentation for 3D Semi-Supervised Object Detection
Apr 04, 2023



State-of-the-art 3D object detectors are usually trained on large-scale datasets with high-quality 3D annotations. However, such 3D annotations are often expensive and time-consuming, which may not be practical for real applications. A natural remedy is to adopt semi-supervised learning (SSL) by leveraging a limited amount of labeled samples and abundant unlabeled samples. Current pseudolabeling-based SSL object detection methods mainly adopt a teacher-student framework, with a single fixed threshold strategy to generate supervision signals, which inevitably brings confused supervision when guiding the student network training. Besides, the data augmentation of the point cloud in the typical teacher-student framework is too weak, and only contains basic down sampling and flip-and-shift (i.e., rotate and scaling), which hinders the effective learning of feature information. Hence, we address these issues by introducing a novel approach of Hierarchical Supervision and Shuffle Data Augmentation (HSSDA), which is a simple yet effective teacher-student framework. The teacher network generates more reasonable supervision for the student network by designing a dynamic dual-threshold strategy. Besides, the shuffle data augmentation strategy is designed to strengthen the feature representation ability of the student network. Extensive experiments show that HSSDA consistently outperforms the recent state-of-the-art methods on different datasets. The code will be released at https://github.com/azhuantou/HSSDA.
Infrared Small-Dim Target Detection with Transformer under Complex Backgrounds
Sep 29, 2021
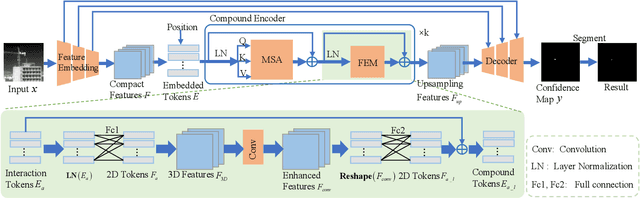
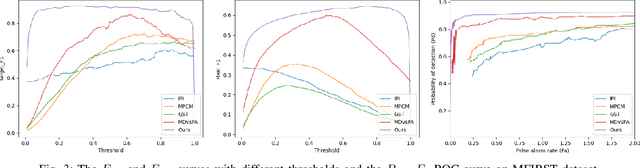

The infrared small-dim target detection is one of the key techniques in the infrared search and tracking system. Since the local regions which similar to infrared small-dim targets spread over the whole background, exploring the interaction information amongst image features in large-range dependencies to mine the difference between the target and background is crucial for robust detection. However, existing deep learning-based methods are limited by the locality of convolutional neural networks, which impairs the ability to capture large-range dependencies. To this end, we propose a new infrared small-dim target detection method with the transformer. We adopt the self-attention mechanism of the transformer to learn the interaction information of image features in a larger range. Additionally, we design a feature enhancement module to learn more features of small-dim targets. After that, we adopt a decoder with the U-Net-like skip connection operation to get the detection result. Extensive experiments on two public datasets show the obvious superiority of the proposed method over state-of-the-art methods.