 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Dense Labels Always Necessary for 3D Object Detection from Point Cloud?
Paper and Code
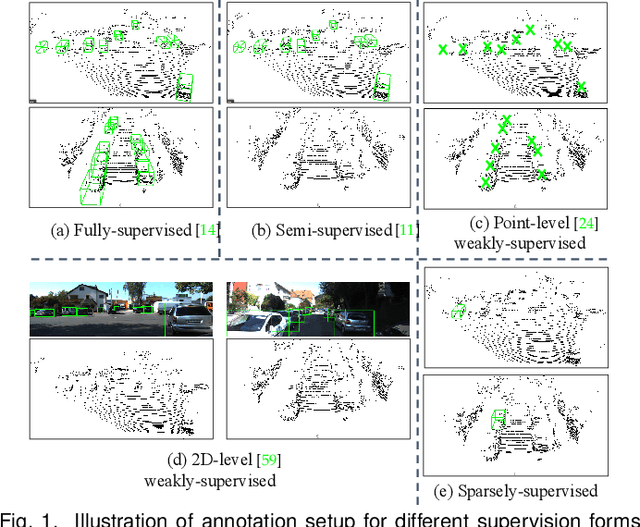



Current state-of-the-art (SOTA) 3D object detection methods often require a large amount of 3D bounding box annotations for training. However, collecting such large-scale densely-supervised datasets is notoriously costly. To reduce the cumbersome data annotation process, we propose a novel sparsely-annotated framework, in which we just annotate one 3D object per scene. Such a sparse annotation strategy could significantly reduce the heavy annotation burden, while inexact and incomplete sparse supervision may severely deteriorate the detection performance. To address this issue, we develop the SS3D++ method that alternatively improves 3D detector training and confident fully-annotated scene generation in a unified learning scheme. Using sparse annotations as seeds, we progressively generate confident fully-annotated scenes based on designing a missing-annotated instance mining module and reliable background mining module. Our proposed method produces competitive results when compared with SOTA weakly-supervised methods using the same or even more annotation costs. Besides, compared with SOTA fully-supervised methods, we achieve on-par or even better performance on the KITTI dataset with about 5x less annotation cost, and 90% of their performance on the Waymo dataset with about 15x less annotation cost. The additional unlabeled training scenes could further boost the performance. The code will be available at https://github.com/gaocq/SS3D2.