 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWildGHand: Learning Anti-Perturbation Gaussian Hand Avatars from Monocular In-the-Wild Videos
Feb 24, 2026Despite recent progress in 3D hand reconstruction from monocular videos, most existing methods rely on data captured in well-controlled environments and therefore degrade in real-world settings with severe perturbations, such as hand-object interactions, extreme poses, illumination changes, and motion blur. To tackle these issues, we introduce WildGHand, an optimization-based framework that enables self-adaptive 3D Gaussian splatting on in-the-wild videos and produces high-fidelity hand avatars. WildGHand incorporates two key components: (i) a dynamic perturbation disentanglement module that explicitly represents perturbations as time-varying biases on 3D Gaussian attributes during optimization, and (ii) a perturbation-aware optimization strategy that generates per-frame anisotropic weighted masks to guide optimization. Together, these components allow the framework to identify and suppress perturbations across both spatial and temporal dimensions. We further curate a dataset of monocular hand videos captured under diverse perturbations to benchmark in-the-wild hand avatar reconstruction. Extensive experiments on this dataset and two public datasets demonstrate that WildGHand achieves state-of-the-art performance and substantially improves over its base model across multiple metrics (e.g., up to a $15.8\%$ relative gain in PSNR and a $23.1\%$ relative reduction in LPIPS). Our implementation and dataset are available at https://github.com/XuanHuang0/WildGHand.
SOFTooth: Semantics-Enhanced Order-Aware Fusion for Tooth Instance Segmentation
Dec 29, 2025Three-dimensional (3D) tooth instance segmentation remains challenging due to crowded arches, ambiguous tooth-gingiva boundaries, missing teeth, and rare yet clinically important third molars. Native 3D methods relying on geometric cues often suffer from boundary leakage, center drift, and inconsistent tooth identities, especially for minority classes and complex anatomies. Meanwhile, 2D foundation models such as the Segment Anything Model (SAM) provide strong boundary-aware semantics, but directly applying them in 3D is impractical in clinical workflows. To address these issues, we propose SOFTooth, a semantics-enhanced, order-aware 2D-3D fusion framework that leverages frozen 2D semantics without explicit 2D mask supervision. First, a point-wise residual gating module injects occlusal-view SAM embeddings into 3D point features to refine tooth-gingiva and inter-tooth boundaries. Second, a center-guided mask refinement regularizes consistency between instance masks and geometric centroids, reducing center drift. Furthermore, an order-aware Hungarian matching strategy integrates anatomical tooth order and center distance into similarity-based assignment, ensuring coherent labeling even under missing or crowded dentitions. On 3DTeethSeg'22, SOFTooth achieves state-of-the-art overall accuracy and mean IoU, with clear gains on cases involving third molars, demonstrating that rich 2D semantics can be effectively transferred to 3D tooth instance segmentation without 2D fine-tuning.
AD-DINOv3: Enhancing DINOv3 for Zero-Shot Anomaly Detection with Anomaly-Aware Calibration
Sep 18, 2025

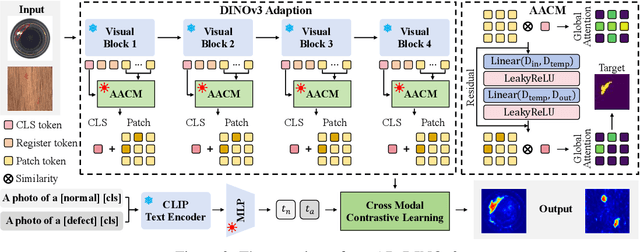

Zero-Shot Anomaly Detection (ZSAD) seeks to identify anomalies from arbitrary novel categories, offering a scalable and annotation-efficient solution. Traditionally, most ZSAD works have been based on the CLIP model, which performs anomaly detection by calculating the similarity between visual and text embeddings. Recently, vision foundation models such as DINOv3 have demonstrated strong transferable representation capabilities. In this work, we are the first to adapt DINOv3 for ZSAD. However, this adaptation presents two key challenges: (i) the domain bias between large-scale pretraining data and anomaly detection tasks leads to feature misalignment; and (ii) the inherent bias toward global semantics in pretrained representations often leads to subtle anomalies being misinterpreted as part of the normal foreground objects, rather than being distinguished as abnormal regions. To overcome these challenges, we introduce AD-DINOv3, a novel vision-language multimodal framework designed for ZSAD. Specifically, we formulate anomaly detection as a multimodal contrastive learning problem, where DINOv3 is employed as the visual backbone to extract patch tokens and a CLS token, and the CLIP text encoder provides embeddings for both normal and abnormal prompts. To bridge the domain gap, lightweight adapters are introduced in both modalities, enabling their representations to be recalibrated for the anomaly detection task. Beyond this baseline alignment, we further design an Anomaly-Aware Calibration Module (AACM), which explicitly guides the CLS token to attend to anomalous regions rather than generic foreground semantics, thereby enhancing discriminability. Extensive experiments on eight industrial and medical benchmarks demonstrate that AD-DINOv3 consistently matches or surpasses state-of-the-art methods.The code will be available at https://github.com/Kaisor-Yuan/AD-DINOv3.
DOD-SA: Infrared-Visible Decoupled Object Detection with Single-Modality Annotations
Aug 14, 2025Infrared-visible object detection has shown great potential in real-world applications, enabling robust all-day perception by leveraging the complementary information of infrared and visible images. However, existing methods typically require dual-modality annotations to output detection results for both modalities during prediction, which incurs high annotation costs. To address this challenge, we propose a novel infrared-visible Decoupled Object Detection framework with Single-modality Annotations, called DOD-SA. The architecture of DOD-SA is built upon a Single- and Dual-Modality Collaborative Teacher-Student Network (CoSD-TSNet), which consists of a single-modality branch (SM-Branch) and a dual-modality decoupled branch (DMD-Branch). The teacher model generates pseudo-labels for the unlabeled modality, simultaneously supporting the training of the student model. The collaborative design enables cross-modality knowledge transfer from the labeled modality to the unlabeled modality, and facilitates effective SM-to-DMD branch supervision. To further improve the decoupling ability of the model and the pseudo-label quality, we introduce a Progressive and Self-Tuning Training Strategy (PaST) that trains the model in three stages: (1) pretraining SM-Branch, (2) guiding the learning of DMD-Branch by SM-Branch, and (3) refining DMD-Branch. In addition, we design a Pseudo Label Assigner (PLA) to align and pair labels across modalities, explicitly addressing modality misalignment during training. Extensive experiments on the DroneVehicle dataset demonstrate that our method outperforms state-of-the-art (SOTA).
Dual-Branch Residual Network for Cross-Domain Few-Shot Hyperspectral Image Classification with Refined Prototype
Apr 27, 2025Convolutional neural networks (CNNs) are effective for hyperspectral image (HSI) classification, but their 3D convolutional structures introduce high computational costs and limited generalization in few-shot scenarios. Domain shifts caused by sensor differences and environmental variations further hinder cross-dataset adaptability. Metric-based few-shot learning (FSL) prototype networks mitigate this problem, yet their performance is sensitive to prototype quality, especially with limited samples. To overcome these challenges, a dual-branch residual network that integrates spatial and spectral features via parallel branches is proposed in this letter. Additionally, more robust refined prototypes are obtained through a regulation term. Furthermore, a kernel probability matching strategy aligns source and target domain features, alleviating domain shift. Experiments on four publicly available HSI datasets illustrate that the proposal achieves superior performance compared to other methods.
MFP-CLIP: Exploring the Efficacy of Multi-Form Prompts for Zero-Shot Industrial Anomaly Detection
Mar 17, 2025Recently, zero-shot anomaly detection (ZSAD) has emerged as a pivotal paradigm for identifying defects in unseen categories without requiring target samples in training phase. However, existing ZSAD methods struggle with the boundary of small and complex defects due to insufficient representations. Most of them use the single manually designed prompts, failing to work for diverse objects and anomalies. In this paper, we propose MFP-CLIP, a novel prompt-based CLIP framework which explores the efficacy of multi-form prompts for zero-shot industrial anomaly detection. We employ an image to text prompting(I2TP) mechanism to better represent the object in the image. MFP-CLIP enhances perception to multi-scale and complex anomalies by self prompting(SP) and a multi-patch feature aggregation(MPFA) module. To precisely localize defects, we introduce the mask prompting(MP) module to guide model to focus on potential anomaly regions. Extensive experiments are conducted on two wildly used industrial anomaly detection benchmarks, MVTecAD and VisA, demonstrating MFP-CLIP's superiority in ZSAD.
CM-Diff: A Single Generative Network for Bidirectional Cross-Modality Translation Diffusion Model Between Infrared and Visible Images
Mar 12, 2025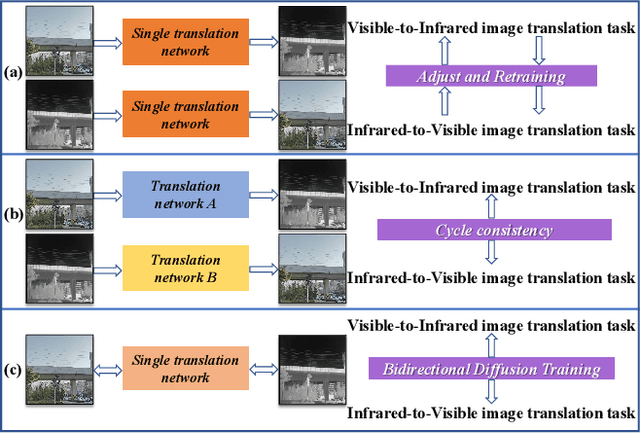
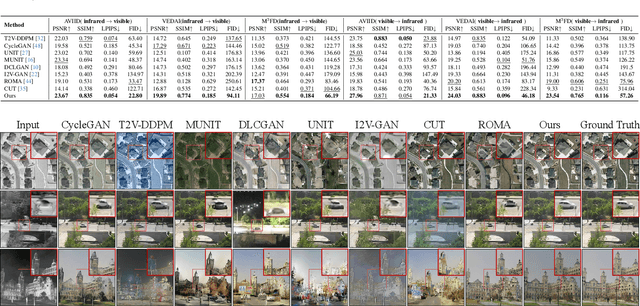
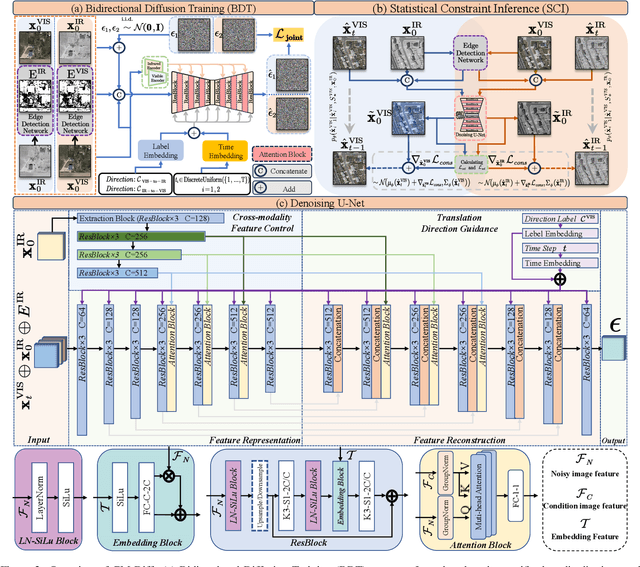

The image translation method represents a crucial approach for mitigating information deficiencies in the infrared and visible modalities, while also facilitating the enhancement of modality-specific datasets. However, existing methods for infrared and visible image translation either achieve unidirectional modality translation or rely on cycle consistency for bidirectional modality translation, which may result in suboptimal performance. In this work, we present the cross-modality translation diffusion model (CM-Diff) for simultaneously modeling data distributions in both the infrared and visible modalities. We address this challenge by combining translation direction labels for guidance during training with cross-modality feature control. Specifically, we view the establishment of the mapping relationship between the two modalities as the process of learning data distributions and understanding modality differences, achieved through a novel Bidirectional Diffusion Training (BDT) strategy. Additionally, we propose a Statistical Constraint Inference (SCI) strategy to ensure the generated image closely adheres to the data distribution of the target modality. Experimental results demonstrate the superiority of our CM-Diff over state-of-the-art methods, highlighting its potential for generating dual-modality datasets.
IV-tuning: Parameter-Efficient Transfer Learning for Infrared-Visible Tasks
Dec 21, 2024Infrared-visible (IR-VIS) tasks, such as semantic segmentation and object detection, greatly benefit from the advantage of combining infrared and visible modalities. To inherit the general representations of the Vision Foundation Models (VFMs), task-specific dual-branch networks are designed and fully fine-tuned on downstream datasets. Although effective, this manner lacks generality and is sub-optimal due to the scarcity of downstream infrared-visible datasets and limited transferability. In this paper, we propose a novel and general fine-tuning approach, namely "IV-tuning", to parameter-efficiently harness VFMs for various infrared-visible downstream tasks. At its core, IV-tuning freezes pre-trained visible-based VFMs and integrates modal-specific prompts with adapters within the backbone, bridging the gap between VFMs and downstream infrared-visible tasks while simultaneously learning the complementarity between different modalities. By fine-tuning approximately 3% of the backbone parameters, IV-tuning outperforms full fine-tuning across various baselines in infrared-visible semantic segmentation and object detection, as well as previous state-of-the-art methods. Extensive experiments across various settings demonstrate that IV-tuning achieves superior performance with fewer training parameters, providing a good alternative to full fine-tuning and a novel method of extending visible-based models for infrared-visible tasks. The code is available at https://github.com/Yummy198913/IV-tuning.
IVGF: The Fusion-Guided Infrared and Visible General Framework
Sep 02, 2024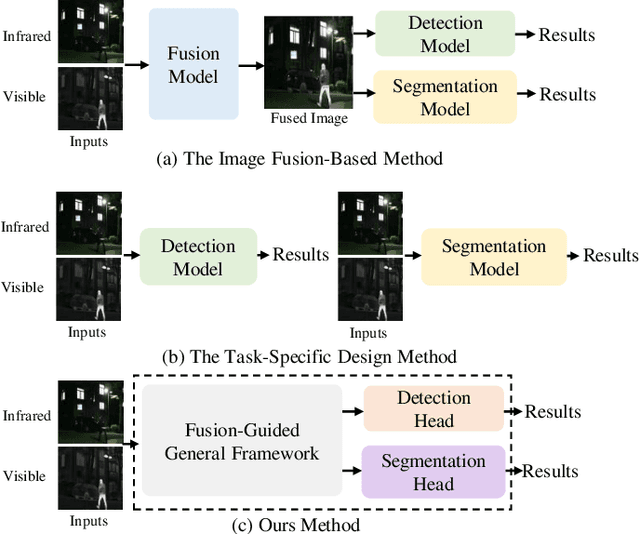
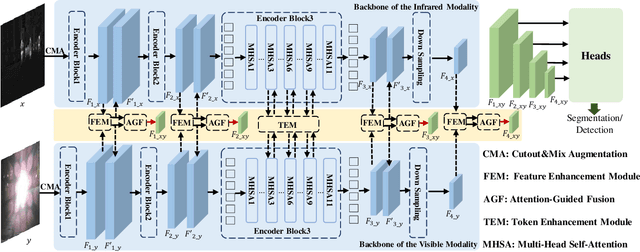
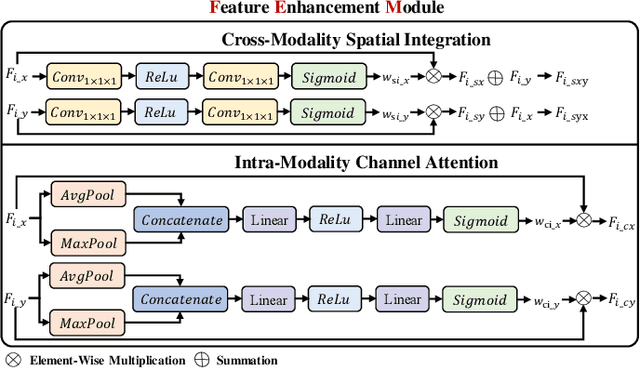

Infrared and visible dual-modality tasks such as semantic segmentation and object detection can achieve robust performance even in extreme scenes by fusing complementary information. Most current methods design task-specific frameworks, which are limited in generalization across multiple tasks. In this paper, we propose a fusion-guided infrared and visible general framework, IVGF, which can be easily extended to many high-level vision tasks. Firstly, we adopt the SOTA infrared and visible foundation models to extract the general representations. Then, to enrich the semantics information of these general representations for high-level vision tasks, we design the feature enhancement module and token enhancement module for feature maps and tokens, respectively. Besides, the attention-guided fusion module is proposed for effectively fusing by exploring the complementary information of two modalities. Moreover, we also adopt the cutout&mix augmentation strategy to conduct the data augmentation, which further improves the ability of the model to mine the regional complementary between the two modalities. Extensive experiments show that the IVGF outperforms state-of-the-art dual-modality methods in the semantic segmentation and object detection tasks. The detailed ablation studies demonstrate the effectiveness of each module, and another experiment explores the anti-missing modality ability of the proposed method in the dual-modality semantic segmentation task.
Towards Student Actions in Classroom Scenes: New Dataset and Baseline
Sep 02, 2024



Analyzing student actions is an important and challenging task in educational research. Existing efforts have been hampered by the lack of accessible datasets to capture the nuanced action dynamics in classrooms. In this paper, we present a new multi-label student action video (SAV) dataset for complex classroom scenes. The dataset consists of 4,324 carefully trimmed video clips from 758 different classrooms, each labeled with 15 different actions displayed by students in classrooms. Compared to existing behavioral datasets, our dataset stands out by providing a wide range of real classroom scenarios, high-quality video data, and unique challenges, including subtle movement differences, dense object engagement, significant scale differences, varied shooting angles, and visual occlusion. The increased complexity of the dataset brings new opportunities and challenges for benchmarking action detection. Innovatively, we also propose a new baseline method, a visual transformer for enhancing attention to key local details in small and dense object regions. Our method achieves excellent performance with mean Average Precision (mAP) of 67.9\% and 27.4\% on SAV and AVA, respectively. This paper not only provides the dataset but also calls for further research into AI-driven educational tools that may transform teaching methodologies and learning outcomes. The code and dataset will be released at https://github.com/Ritatanz/SAV.