 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Branch Residual Network for Cross-Domain Few-Shot Hyperspectral Image Classification with Refined Prototype
Apr 27, 2025Convolutional neural networks (CNNs) are effective for hyperspectral image (HSI) classification, but their 3D convolutional structures introduce high computational costs and limited generalization in few-shot scenarios. Domain shifts caused by sensor differences and environmental variations further hinder cross-dataset adaptability. Metric-based few-shot learning (FSL) prototype networks mitigate this problem, yet their performance is sensitive to prototype quality, especially with limited samples. To overcome these challenges, a dual-branch residual network that integrates spatial and spectral features via parallel branches is proposed in this letter. Additionally, more robust refined prototypes are obtained through a regulation term. Furthermore, a kernel probability matching strategy aligns source and target domain features, alleviating domain shift. Experiments on four publicly available HSI datasets illustrate that the proposal achieves superior performance compared to other methods.
Towards Student Actions in Classroom Scenes: New Dataset and Baseline
Sep 02, 2024



Analyzing student actions is an important and challenging task in educational research. Existing efforts have been hampered by the lack of accessible datasets to capture the nuanced action dynamics in classrooms. In this paper, we present a new multi-label student action video (SAV) dataset for complex classroom scenes. The dataset consists of 4,324 carefully trimmed video clips from 758 different classrooms, each labeled with 15 different actions displayed by students in classrooms. Compared to existing behavioral datasets, our dataset stands out by providing a wide range of real classroom scenarios, high-quality video data, and unique challenges, including subtle movement differences, dense object engagement, significant scale differences, varied shooting angles, and visual occlusion. The increased complexity of the dataset brings new opportunities and challenges for benchmarking action detection. Innovatively, we also propose a new baseline method, a visual transformer for enhancing attention to key local details in small and dense object regions. Our method achieves excellent performance with mean Average Precision (mAP) of 67.9\% and 27.4\% on SAV and AVA, respectively. This paper not only provides the dataset but also calls for further research into AI-driven educational tools that may transform teaching methodologies and learning outcomes. The code and dataset will be released at https://github.com/Ritatanz/SAV.
Bag of Tricks: Semi-Supervised Cross-domain Crater Detection with Poor Data Quality
Dec 11, 2023


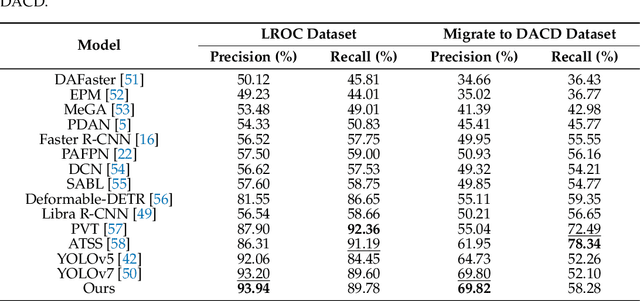
With the development of spaceflight and the exploration of extraterrestrial planets, exoplanet crater detection has gradually gained attention. However, with the current scarcity of relevant datasets, high sample background complexity, and large inter-domain differences, few existing detection models can achieve good robustness and generalization across domains by training on data with more background interference. To obtain a better robust model with better cross-domain generalization in the presence of poor data quality, we propose the SCPQ model, in which we first propose a method for fusing shallow information using attention mechanism (FSIAM), which utilizes feature maps fused with deep convolved feature maps after fully extracting the global sensory field of shallow information via the attention mechanism module, which can fully fit the data to obtain a better sense of the domain in the presence of poor data, and thus better multiscale adaptability. Secondly, we propose a pseudo-label and data augment strategy (PDAS) and a smooth hard example mining (SHEM) loss function to improve cross-domain performance. PDAS adopts high-quality pseudo-labeled data from the target domain to the finetune model, and adopts different strong and weak data enhancement strategies for different domains, which mitigates the different distribution of information inherent in the source and target domains, and obtains a better generalization effect. Meanwhile, our proposed SHEM loss function can solve the problem of poor robustness of hard examples due to partial background interference learning during the training process. The SHEM loss function can smooth this interference and has generalization while learning hard examples. Experimental results show that we achieved better performance on the DACD dataset and improved the Recall of cross-domain detection by 24.04\% over baseline.